The schedule is out 🗓️ for POSETTE: An Event for Postgres 2026!
Postgres community released a new feature, in Postgres 15.0, that performs actions to modify rows in the target table, using the data from a source. MERGE provides a single SQL statement that can conditionally INSERT, UPDATE or DELETE rows, a task that would otherwise require multiple procedural language statements, using INSERT with ON CONFLICT clause etc.
In this blog post, you will learn a high-level overview of the functioning of Postgres MERGE. It will delve into some of the practical use-cases, and subsequently elaborate on the different strategies employed by Citus for handling MERGE in a distributed environment.
- Real-world applications of the Postgres MERGE SQL operation
- How MERGE works in Postgres (as of Postgres 15)
- From theory to practice: Diving into use case(s)
- The yet-to-be-implemented frontier
- You are eager to unlock the full potential of MERGE SQL
Real-world applications of the Postgres MERGE SQL operation
- Data synchronization: If you're periodically syncing data from an external system and want to update existing records while creating new ones as necessary. MERGE ensures that the database remains consistent with the external data source.
- Data deduplication: If you're handling data that might contain duplicates, and a duplicate row is detected, you can simply update the existing record.
- Logging: In cases where you're logging events to a table and you want to count occurrences of events, and an event occurs that's already in the table, you increment a counter; otherwise, you insert a new row.
- Real-time data update: If you're dealing with real-time data that's constantly being updated, such as stock prices or sensor readings, you can use MERGE to ensure that the most recent data is always available, without the need to distinguish between new and existing data.
- Batch operations: When performing bulk operations that may involve both insertions and updates, using MERGE can be more efficient than issuing separate insert and update commands, as it minimizes the number of total commands sent and processed.
How MERGE works in Postgres (as of Postgres 15)
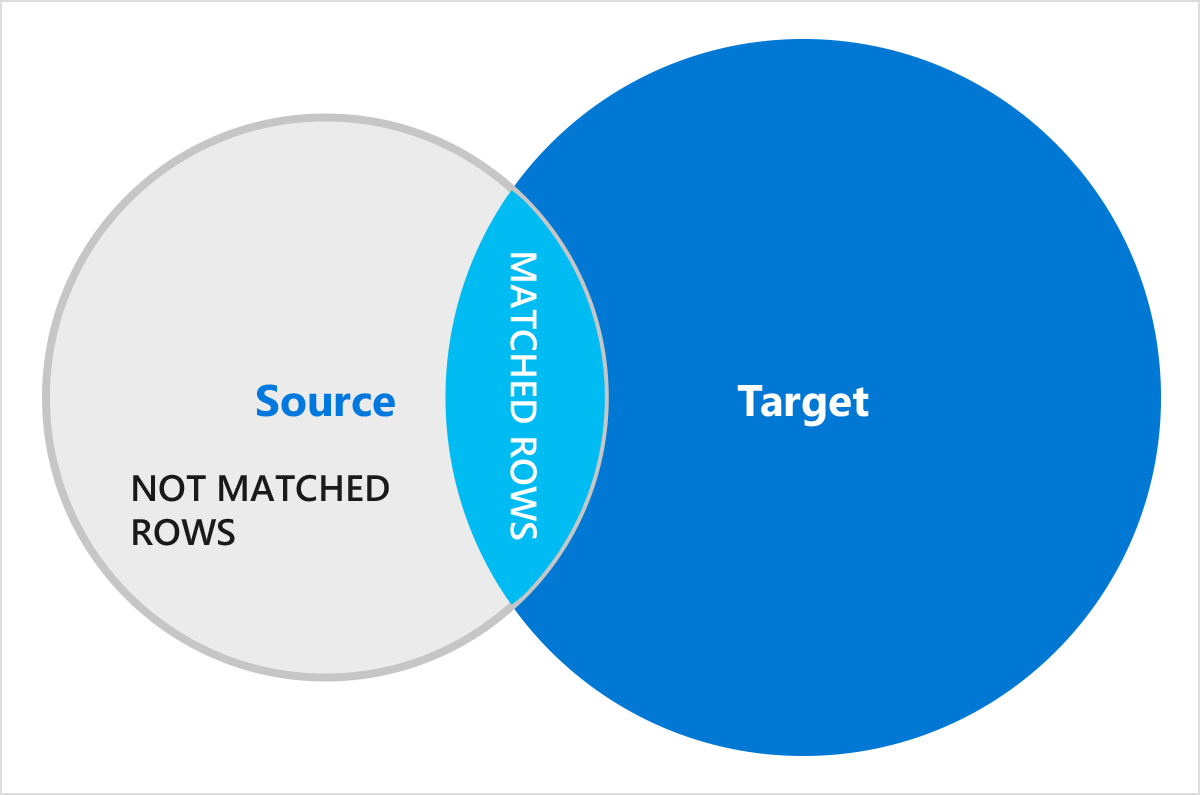
For each matched row:
- WHEN clauses are evaluated in the exact specified order until one of them is activated.
- The corresponding action is then applied, and processing continues for the next row.
Note: Each output row of the join can activate at most one when-clause.
From theory to practice: Diving into use case(s)
Let's start by looking at a simple query-routing scenario
CREATE TABLE orders
( order_id INT,
customer_id INT,
order_center VARCHAR,
order_time timestamp
);
CREATE TABLE customers
( customer_id INT,
last_order_id INT,
order_center VARCHAR,
order_count INT,
last_order timestamp
);
Distribute both the tables on customer_id and co-locate them.
SELECT create_distributed_table('customers', 'customer_id');
SELECT create_distributed_table('orders', 'customer_id', colocate_with=>'customers');
MERGE INTO customers t
USING orders s
ON (t.customer_id = s.customer_id)
WHEN MATCHED AND t.order_center = 'New York' THEN
-- Remove the customer in target
DELETE
WHEN MATCHED THEN
-- Existing customer, update the order count
UPDATE SET order_count = t.order_count + 1, last_order_id = s.order_id
WHEN NOT MATCHED THEN
-- New entry, record it in target
INSERT (customer_id, last_order_id, order_center, order_count, last_order)
VALUES (customer_id, s.order_id, s.order_center, 1, s.order_time);
Since the data pertaining to a customer is stored on a singular worker node, the MERGE command uses query routing. Query routing means taking (part of) the query and letting the worker node that stores the relevant shards handle the query, which is possible when the query filters and joins by the distribution column.
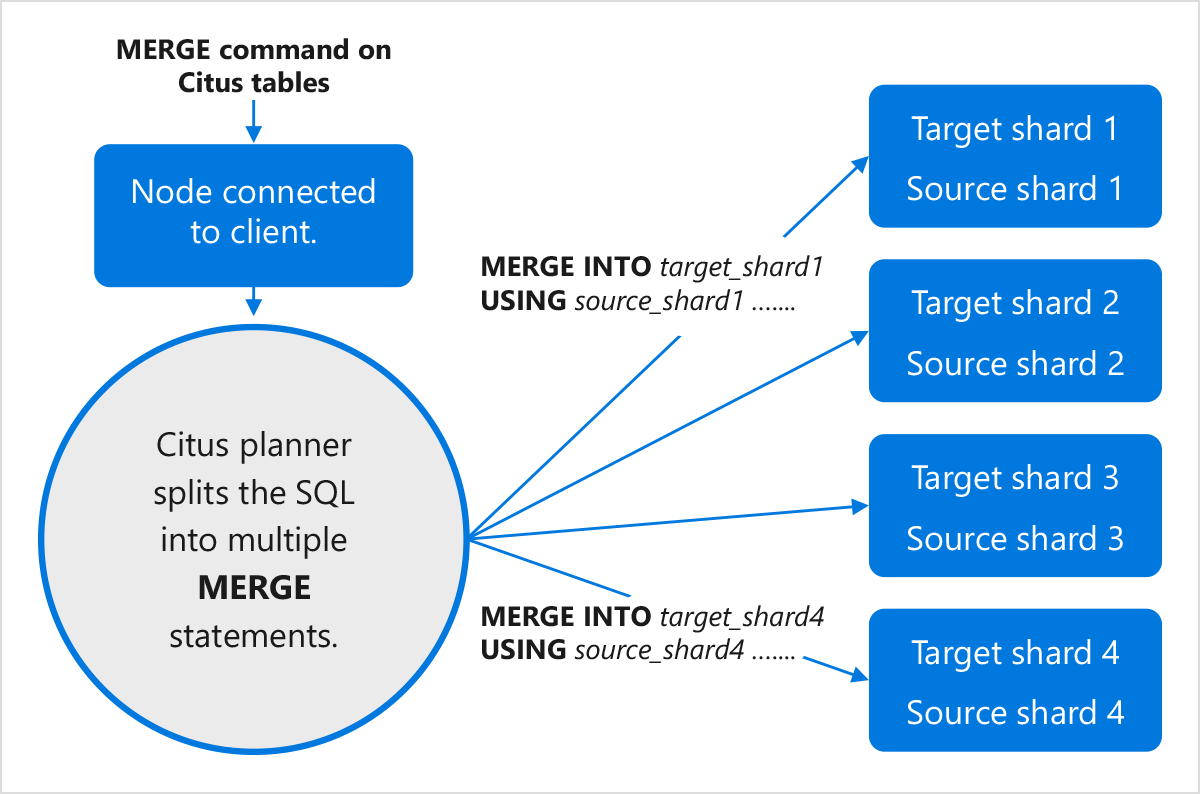
Query routing allows Citus to support all the SQL functionality of the underlying PostgreSQL servers at scale for multi-tenant (SaaS) applications, which typically filter by tenant ID. This approach has minimal overhead in terms of distributed query planning time and network traffic, which enables high concurrency and low latency. However, this limits flexibility for both the data location and join clauses in the MERGE statement.
Beyond the Basics: Exploring MERGE in Complex Scenarios
In certain cases, queries may involve joining on columns that are not distributed, which necessitates on-the-fly matching of source and target rows. This can be accomplished through techniques like repartitioning. For queries that require final aggregation of the query results processing, such as 'order by with limit' clause, achieved through the pull-to-coordinator approach.
Consider an IoT scenario related to Industrial IoT (IIoT) in a manufacturing setting. Let's use four tables to demonstrate this example: machines, sensors, sensor_readings and real_sensor_readings.
-- Contains information about the machines in the manufacturing facility
CREATE TABLE machines (
machine_id NUMERIC PRIMARY KEY,
machine_name VARCHAR(100),
location VARCHAR(50),
status VARCHAR(20)
);
SELECT create_reference_table('machines');
-- Holds data on the various sensors installed on each machine
CREATE TABLE sensors (
sensor_id NUMERIC PRIMARY KEY,
sensor_name VARCHAR(100),
machine_id NUMERIC,
sensor_type VARCHAR(50)
);
SELECT create_distributed_table('sensors', 'sensor_id');
-- Stores real-time readings from the sensors
CREATE TABLE sensor_readings (
reading_id NUMERIC ,
sensor_id NUMERIC,
reading_value NUMERIC,
reading_timestamp TIMESTAMP
);
SELECT create_distributed_table('sensor_readings', 'sensor_id');
-- Holds real-time sensor readings for machines on 'Production Floor 1'
CREATE TABLE real_sensor_readings (
real_reading_id NUMERIC ,
sensor_id NUMERIC,
reading_value NUMERIC,
reading_timestamp TIMESTAMP
);
SELECT create_distributed_table('real_sensor_readings', 'sensor_id');
Now, let's insert some sample data into these tables:
-- Insert data into the machines table
INSERT INTO machines (machine_id, machine_name, location, status)
VALUES
(1, 'Machine A', 'Production Floor 1', 'Active'),
(2, 'Machine B', 'Production Floor 2', 'Active'),
(3, 'Machine C', 'Production Floor 1', 'Inactive');
-- Insert data into the sensors table
INSERT INTO sensors (sensor_id, sensor_name, machine_id, sensor_type)
VALUES
(1, 'Temperature Sensor 1', 1, 'Temperature'),
(2, 'Pressure Sensor 1', 1, 'Pressure'),
(3, 'Temperature Sensor 2', 2, 'Temperature'),
(4, 'Vibration Sensor 1', 3, 'Vibration');
-- Insert data into the real_sensor_readings table
INSERT INTO real_sensor_readings (real_reading_id, sensor_id, reading_value, reading_timestamp)
VALUES
(1, 1, 35.6, TIMESTAMP '2023-07-20 10:15:00'),
(2, 1, 36.8, TIMESTAMP '2023-07-20 10:30:00'),
(3, 2, 100.5, TIMESTAMP '2023-07-20 10:15:00'),
(4, 2, 101.2, TIMESTAMP '2023-07-20 10:30:00'),
(5, 3, 36.2, TIMESTAMP '2023-07-20 10:15:00'),
(6, 3, 36.5, TIMESTAMP '2023-07-20 10:30:00'),
(7, 4, 0.02, TIMESTAMP '2023-07-20 10:15:00'),
(8, 4, 0.03, TIMESTAMP '2023-07-20 10:30:00');
We'll calculate the average sensor reading value for each sensor on 'Production Floor 1' from the real_sensor_readings table. The MERGE statement will then update the sensor_readings table with the calculated average values.
MERGE INTO sensor_readings SR
USING (SELECT
rsr.sensor_id,
AVG(rsr.reading_value) AS average_reading,
MAX(rsr.reading_timestamp) AS last_reading_timestamp,
MAX(rsr.real_reading_id) AS rid
FROM sensors s
INNER JOIN machines m ON s.machine_id = m.machine_id
INNER JOIN real_sensor_readings rsr ON s.sensor_id = rsr.sensor_id
WHERE m.location = 'Production Floor 1'
GROUP BY rsr.sensor_id
) NEW_READINGS
ON (SR.sensor_id = NEW_READINGS.sensor_id)
-- Existing reading, update it
WHEN MATCHED THEN
UPDATE SET reading_value = NEW_READINGS.average_reading, reading_timestamp = NEW_READINGS.last_reading_timestamp
-- New reading, record it
WHEN NOT MATCHED THEN
INSERT (reading_id, sensor_id, reading_value, reading_timestamp)
VALUES (NEW_READINGS.rid, NEW_READINGS.sensor_id,
NEW_READINGS.average_reading, NEW_READINGS.last_reading_timestamp);
SELECT * FROM sensor_readings ORDER BY 1;
┌────────────┬───────────┬────────────────────────┬─────────────────────┐
│ reading_id │ sensor_id │ reading_value │ reading_timestamp │
├────────────┼───────────┼────────────────────────┼─────────────────────┤
│ 2 │ 1 │ 36.2000000000000000 │ 2023-07-20 10:30:00 │
│ 4 │ 2 │ 100.8500000000000000 │ 2023-07-20 10:30:00 │
│ 8 │ 4 │ 0.02500000000000000000 │ 2023-07-20 10:30:00 │
└────────────┴───────────┴────────────────────────┴─────────────────────┘
Even though the source and target table are not co-located (a mix of distributed and reference table with complex joins), Citus uses a flexible repartition strategy which either gathers or reshuffles the intermediate results of the source data and aggregates the results at the coordinator.
In general, Citus 12.0 can handle any query in the source part of the MERGE command and repartition its output to match the target table.
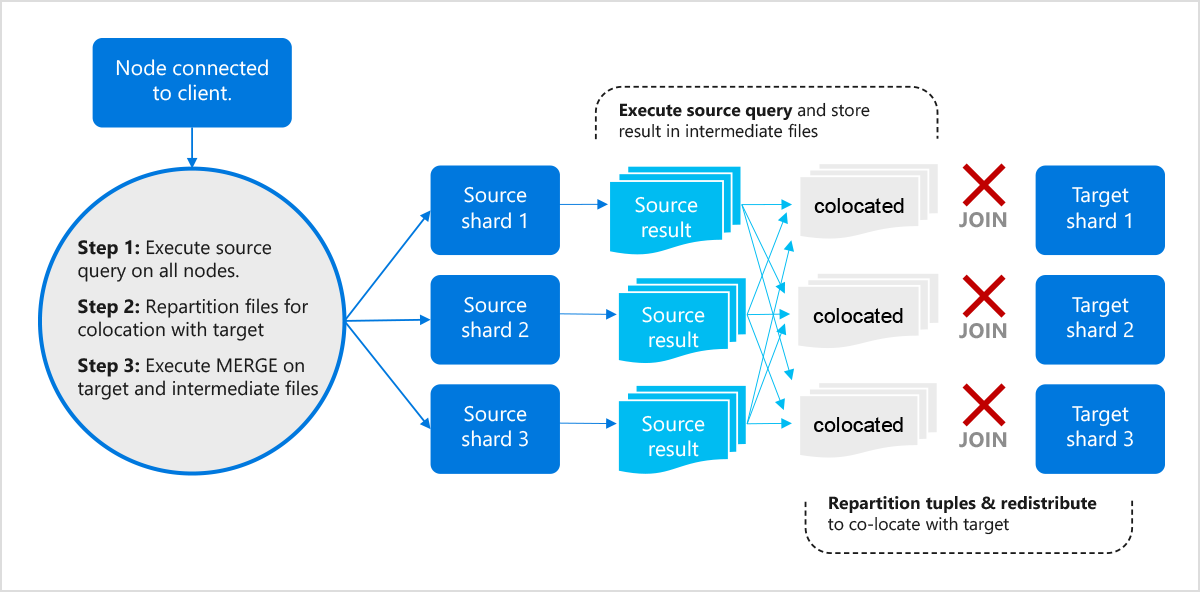
In the above example, Citus will execute the source query at the worker nodes in parallel, then repartition the intermediate results data across the cluster on the fly to co-locate it with the target, before running the MERGE operation on the target and intermediate results.
However, in certain scenarios, such as a source query with a LIMIT clause, where processing of results at the coordinator becomes necessary, Citus employs a slightly different strategy Pull-to-coordinator: It gathers the intermediate results on the coordinator for further processing and does repartition similar to the above-described strategy. All these operations are done within a single parallel, distributed transaction.
The combination of all three different strategies makes the MERGE command the most advanced distributed database operation available in Citus.
The yet-to-be-implemented frontier
Despite using repartitioning or pull-to-coordinator execution, there remain two significant limitations of the MERGE command on distributed tables. These limitations stem from the distributed nature of Citus and the characteristics of the MERGE command.
Repartitioning or pulling-to-coordinator of the target_table is not feasible. Therefore, in the MERGE query processing, we rely on the target_table as the anchor and only shuffle the source part of the query.
The two limitations resulting from the above approach are:
- The ON clause must include the distribution key of the
target_table. - In the NOT MATCHED ... INSERT() action, the value provided for the distribution key of the target must be the joining clause of the source query of the ON clause.
CREATE TABLE target(tid int, val int);
CREATE TABLE source(sid int, val int);
SELECT create_distributed_table('target', 'tid');
SELECT create_distributed_table('source', 'sid');
MERGE INTO target USING source ON (source.sid = target.val)
WHEN MATCHED THEN UPDATE SET val = source.val
WHEN NOT MATCHED THEN INSERT VALUES(source.sid, source.val);
ERROR: The required join operation is missing between the target's distribution column and any expression originating from the source. The issue may arise from either a non-equi-join or a mismatch in the datatypes of the columns being joined.
DETAIL: Without a equi-join condition on the target's distribution column, the source rows cannot be efficiently redistributed, and the NOT-MATCHED condition cannot be evaluated unambiguously. This can result in incorrect or unexpected results when attempting to merge tables in a distributed setting
Trying to put a different value than the one used for joining with target distribution column will result in
CREATE TABLE target(tid int, val int);
CREATE TABLE source(sid int, val int);
SELECT create_distributed_table('target', 'tid');
SELECT create_distributed_table('source', 'sid');
MERGE INTO target USING source ON (source.sid = target.tid)
WHEN MATCHED THEN UPDATE SET val = source.val
WHEN NOT MATCHED THEN INSERT VALUES(source.val, 0);
MERGE INSERT must use the source's joining column for target's distribution column
Currently you cannot MERGE into a reference table, but you can use it as source for any type of target table.
CREATE TABLE target(tid int, val int);
CREATE TABLE source(sid int, val int);
SELECT create_reference_table('target');
SELECT create_distributed_table('source', 'sid');
MERGE INTO target USING source ON (source.sid = target.tid)
WHEN MATCHED THEN UPDATE SET val = 15;
ERROR: Reference table as target is not allowed in MERGE command
Given that Citus columnar lacks UPDATE and DELETE capabilities, this creates a limitation on using Columnar table as a target in MERGE.
CREATE TABLE target(tid int, val int) USING columnar;
CREATE TABLE source(sid int, val int);
SELECT create_distributed_table('target', 'tid');
SELECT create_distributed_table('source', 'sid');
MERGE INTO target USING source ON (source.sid = target.val)
WHEN MATCHED THEN UPDATE SET val = 15
WHEN NOT MATCHED THEN INSERT VALUES(source.sid, 0);
ERROR: Columnar table as target is not allowed in MERGE command
Subqueries and CTEs are supported only in the source i.e. USING clause.
CREATE TABLE target(tid int, val int);
CREATE TABLE source(sid int, val int);
SELECT create_distributed_table('target', 'tid');
SELECT create_distributed_table('source', 'sid');
MERGE INTO target t
USING (SELECT * FROM source) AS s
ON (s.sid = t.tid AND (SELECT 1=1 FROM target))
WHEN MATCHED THEN
DELETE;
ERROR: Sub-queries and CTEs are not allowed in ON clause for MERGE with repartitioning
HINT: Consider making the source and target co-located and joined on the distribution column to make it a routable query
CREATE TABLE target(tid int, val int);
CREATE TABLE source(sid int, val int);
SELECT create_distributed_table('target', 'tid');
SELECT create_distributed_table('source', 'sid');
MERGE INTO target
USING source
ON (target.tid = source.sid)
WHEN NOT MATCHED THEN
INSERT VALUES (source.sid, (select MAX(val) from source));
ERROR: Sub-queries and CTEs are not allowed in actions for MERGE with repartitioning
HINT: Consider making the source and target colocated and joined on the distribution column to make it a routable query
You are eager to unlock the full potential of MERGE SQL
If feasible, choose the most optimal approach among the three strategies, known as query routing, by co-locating the target and source tables and performing the join on their distributed columns. Nonetheless, it's important to note that these colocation requirements should not impose limitations on your MERGE capabilities, as the other two repartitioning strategies remain available. The remarkable aspect is that as an end user, you need not concern yourself with selecting a strategy, as the Citus planner consistently strives to choose the optimal approach and ensures complete transparency for the user.
Here are some more useful reads on the Citus MERGE:
