📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
The topic of this month's PGSQL Phriday #011 community blogging event is partitioning vs. sharding in PostgreSQL. It seemed right to share a perspective on the question of "partitioning vs. sharding" from someone in the Citus open source team, since we eat, sleep, and breathe sharding for Postgres.
Postgres built-in "native" partitioning—and sharding via PG extensions like Citus—are both tools to grow your Postgres database, scale your application, and improve your application's performance.
What is partitioning and what is sharding? In Postgres, database partitioning and sharding are techniques for splitting collections of data into smaller sets, so the database only needs to process smaller chunks of data at a time. And as you might imagine, work gets done faster when you're processing less data.
In this post, you'll learn what partitioning and sharding are, why they matter, and when to use them. The table of contents:
- What is partitioning in Postgres?
- How Postgres partitioning can benefit you
- What is sharding?
- When to use Citus to shard Postgres?
- Partitioning vs. Sharding, a comparison table
- How to use range partitioning & Citus sharding together for time series
- What about sharding using partitioned tables with postgres_fdw?
The question of partitioning vs. sharding is a bit of a false dichotomy. It's not a choice of one or the other, since the two techniques are not mutually exclusive. Rather, you can choose to use Postgres native partitioning, or you can shard Postgres with an extension like Citus to distribute Postgres across multiple nodes—or you can use both together.
What is partitioning in Postgres?
Table partitioning in Postgres is:
- A built-in, native feature in Postgres
- Some people refer to it as "declarative partitioning" since you have to declare whether you mean to
PARTITION BY RANGEorPARTITION BY LISTorPARTITION BY HASHwhen you are creating the table - Splits large tables into many smaller tables ("partitions")—which can benefit you in terms of performance, since it's more efficient to work with smaller chunks of data
- While most tables probably don't need to be partitioned, and per Brandur's footnote advice you shouldn't use this feature for no reason—partitioning has improved quite a lot in Postgres in recent years and can be useful for scaling performance on a single Postgres node.
- Needs to be declared up front when you first create a Postgres table, since you can't turn an existing regular Postgres table into a partitioned table without a significant amount of data rewriting.1
How Postgres partitioning can benefit you
By far the most common use case for partitioning is to partition tables containing time series data by time (e.g. typically a partition per or week). That has several key benefits:
- Improves query performance: particularly when you query a subset of partitions (e.g. recent data) and the partitions you're querying can be held in memory
- Improves performance of bulk deletes if the data you're expiring is associated with older partitions, so you can avoid having to scan the table, table bloat, and fragmentation by simply dropping the old partitions.
- Improves performance of autovacuum, since it can run in parallel on the partitions and avoids the "autovacuum can't keep up" problem.
- Storage cost optimization: Perhaps you want to put some partitions on different storage (maybe you have a table space for big slow disks for seldom-used and older data, and fast expensive storage for currently active partitions.)
- Compression: Perhaps you want to use a different Postgres table access method for some data: data that is still changing can be in regular row format, and older data can move into (say) Citus columnar.
There are other cases in which you might want to use partitioning, especially if you are suffering from autovacuuming issues, though time series is the most common.
One of my favorite blog posts about Postgres partitioning
Prior to this PGSQL Phriday blogging event on partitioning vs. sharding, one of my favorite Postgres partitioning blog posts was this one by Brandur. I love his description of Postgres partitioned tables:
"Partitioned tables aren't an everyday go to, but are invaluable in some cases, particularly when you have a high volume table that's expected to keep growing.
In Postgres, trying to remove old rows from a large, hot table is flitting with disaster. A long running query must iterate through and mark each one as dead, and even then nothing is reclaimed until an equally expensive vacuum runs through and frees space, and only when it's allowed to after rows are no longer visible to any other query in the system, whether they're making use of the large table or not. Each row removal land in the WAL, resulting in significant amplification.
But with partitions, deletion becomes a simple DROP TABLE. It executes instantly, and with negligible costs (partitioning has other benefits too). The trade-off is maintenance."
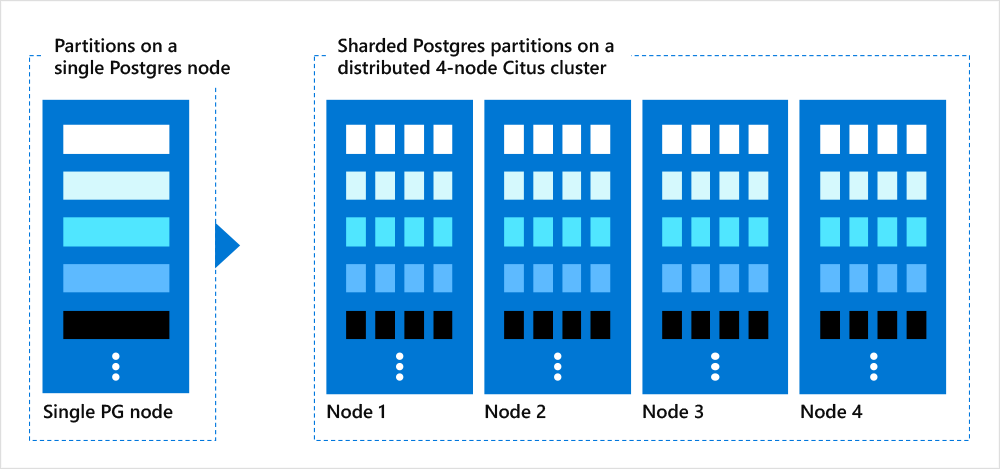
What is sharding in Postgres?
Sharding in Postgres is:
- a technique of splitting Postgres database tables into smaller tables (called "shards") that is typically used to distribute data horizontally across multiple nodes comprising a cluster of database instances
- a capability available via the Citus open source extension to Postgres
- typically deployed in a multi-node cluster2
- can be thought of as "horizontal scaling" since you're distributing Postgres across nodes in a cluster
Some people associate the term sharding with the idea of "manual sharding" or what I call "sharding at the application level." Many of you likely know that application-level sharding is a LOT of work, since your application needs to keep track of which shards are where in order to know which nodes to query. That's not what I'm talking about with Citus and Postgres.
With the Citus extension to Postgres, all the sharding metadata (such as which shard is on which node) is managed and maintained by Citus, which means your application can remain blissfully ignorant of the fact that it is running on top of a Postgres cluster and you can let Citus take care of the sharding management.
Of course, that's not to say that you can completely ignore the fact that your app is running on top of distributed Postgres. You'll still need to decide up-front what tables (or schemas) to distribute across the cluster, and which tables you might leave as regular Postgres tables on the coordinator, and which tables would make good reference tables. And you'll likely need to add nodes to your cluster as you scale and grow, rebalance shards to balance performance, and perhaps even isolate big tenants if you're running a multi-tenant SaaS application. Basically, you'll have to do things to optimize the cluster as your workload grows.
When to use Citus to shard Postgres?
The traditional "row-based" Citus sharding approach for Postgres is a good fit for real-time analytics apps including:
- time series applications,
- IOT applications that need UPDATEs and JOINs,
- HTAP applications with mixed transactional and analytics workloads,
- high-throughput transactional apps, and
- multi-tenant SaaS apps that have a very large number of tenants (think: B2C apps with more than 100K tenants)
The Citus "schema-based sharding" approach—newly-introduced in Citus 12.0—is a good fit for:
- multi-tenant SaaS apps with fewer than 10K tenants (think: B2B)
- microservices applications.
- vertical partitioning of complex applications by function
- complex OLTP applications that can be vertically sharded by function
As a developer, schema-based sharding is a bit easier to get started with since you do not need to choose a distribution key or make any changes to your data model to ensure that the distribution column is in your tables. Rather, with Citus schema-based sharding, you can leverage the existing Postgres schemas you've defined for your database to distribute Postgres across multiple nodes.
How can sharding Postgres with Citus benefit you?
The reason to shard Postgres with Citus pretty much always comes down to needing more performance and more scale than you can eek out on a single node—even a really freaking big single node. I wrote this in a blog post back in late 2020 and it's still true:
Why would you want to use Citus to shard Postgres?
- Performance: Because your single node Postgres is not performant enough and cannot keep up with the peaks in your workload.
- Scale: Because your application is growing fast and you want to prepare your Postgres deployment to scale out before you run into performance issues, before you have to send your customers apology letters for poor performance.
Since sharding is inherently also a form of hash-partitioning, some of the performance benefits of partitioning also apply to sharding. In particular, autovacuum runs in parallel across all the Citus shards in the cluster.
Partitioning vs. Sharding, a comparison table
| Partitioning in Postgres | Sharding in Postgres | |
|---|---|---|
| Feature availability | Built-in, native support in Postgres | Available via Citus extension to Postgres |
| # of nodes | Single node3 | Typically a multi-node cluster |
| Types | RANGE, LIST, & HASH | Row-based (hash) & schema-based |
| Good fit for | Time series IoT Real-time analytics | Time series Real-time analytics Multi-tenant applications Microservices High throughput CRUD ... |
| Shard/partition maintenance | Manual (use additional tools) | Automatic / transparent |
| Unique capabilities | Drop old data quickly Compress old data | Horizontal scale out of hardware Parallel, distributed SQL/DML/DDL |
| Other benefits | Read only relevant partitions Parallel autovacuum Better index cache hit ratios | Read only relevant shards Parallel, distributed autovacuum Data rebalancing across nodes |
How to use range partitioning & Citus sharding together for time series
If you work on an application that deals with time series data, specifically append-mostly time series data, you'll likely find this post about using Postgres range partitioning and Citus sharding together to scale time series workloads to be useful additional reading.
The time series post covers:
- Built-in Postgres partitioning
- Citus UDFs that simplify partition management:
create_time_partitionsanddrop_old_time_partitions - Compression (if you use Citus columnar)
- Automation via pg_cron
- Sharding & distributing across nodes with Citus
The bottom line of the time series blog post is that you can use Postgres built-in range partitioning to partition your tables by time ranges (super useful for time series data) and then—assuming your application needs more cpu and memory than you can get on a single node—you can also use Citus database sharding to distribute sharded partitions across a multi-node cluster.
What about sharding using partitioned tables with postgres_fdw?
An alternative approach to sharding Postgres using Citus is to create a hash-partitioned table in Postgres in which every partition is a foreign table that uses postgres_fdw. That way, you can query tables across multiple PostgreSQL servers, and queries for a specific partition key value will only access one remote PostgreSQL server.
While this approach has the advantage of being part of core PostgreSQL, it lacks many of the elemental features that a Postgres sharding solution needs, both in terms of management and performance. For instance:
- No full query pushdown (necessary to achieve scalability)
- No transparent schema changes
- No rebalancing
- No reference tables
- No co-located joins
- No multi-stage query execution (e.g. broadcast results of CTE, then join with the CTE)
- No object propagation (e.g. create type)
- No shard splits
- No pg_dump
- No support for 2PC – cross-shard changes may only be partially applied
- Limited support for parallel query
- Poor query performance
- Poor bulk loading performance
- Manual creation of shards
In that sense, Postgres native partitioning that uses FOREIGN TABLES to shard is effectively manual sharding with the ability to do simple queries across nodes. If you are considering using partitioning with foreign tables for sharding, we recommend you look into Citus as well.
Big thank you to PGSQL Phriday blog event organizers
+1 to Ryan Booz for organizing the #PGSQLPhriday community blogging initiative—and to Tomasz Gintowt for hosting this month's #PGSQL Phriday #011 event and selecting the topic of "Partitioning vs. Sharding", a topic I know and love. Like many of you, I'm looking forward to reading more of the Postgres partitioning and sharding blogs on this topic that get published.
If you want to learn more about partitioning in Postgres and sharding Postgres with Citus, here are some links:
- Postgres docs on table partitioning
- Partitioning in Postgres, 2022 edition by Brandur
- Citus open source repo on GitHub, the place to file issues or start discussions (or give a star :)
- Citus open source docs
- Citus on Azure docs, now known as Azure Cosmos DB for PostgreSQL
Also, big thanks to Thomas Munro, Marco Slot, and Rob Treat for their thoughtful feedback on earlier drafts of this blog post. I really appreciate your inputs! And to Andreas Scherbaum for making sure this PGSQL Phriday was on my post-vacation radar.
Footnotes
- However, it is possible to add an existing regular table as a partition to a partitioned table. More details on
ATTACH PARTITIONandDETACH PARTITIONcan be found in the Postgres documentation for ALTER TABLE. ↩ - N.B. As of Citus 10.0, it is possible to use Citus on a single node and shard your Postgres database on day one, even before you need the resources of multiple nodes. ↩
- While you can use Postgres partitions combined with postgres_fdw to shard partitions across nodes, you probably shouldn't. See the section about partitioned tables with postgres_fdw. ↩
