Watch 👀 the Citus 12.0 Release Party livestream replay—with demos + Q&A! 📺
What if you could automatically shard your PostgreSQL database across any number of servers and get industry-leading performance at scale without any special data modelling steps?
Our latest Citus open source release, Citus 12, adds a new and easy way to transparently scale your Postgres database: Schema-based sharding, where the database is transparently sharded by schema name.
Schema-based sharding gives an easy path for scaling out several important classes of applications that can divide their data across schemas:
- Multi-tenant SaaS applications
- Microservices that use the same database
- Vertical partitioning by groups of tables
Each of these scenarios can now be enabled on Citus using regular CREATE SCHEMA commands. That way, many existing applications and libraries (e.g. django-tenants) can scale out without any changes, and developing new applications can be much easier. Moreover, you keep all the other benefits of Citus, including distributed transactions, reference tables, rebalancing, and more.
In this blog post, you’ll get a high-level overview of schema-based sharding and other new Citus 12 features:
- What is schema-based sharding?
- How to use Citus schema-based sharding for Postgres
- Benefits of schema-based sharding
- Choosing a sharding model for multi-tenant applications (schema-based vs. row-based)
- Migrating an existing schema-per-tenant application to Citus
- MERGE improvements
Even more details available in the release notes on the 12.0 Updates page. And if you want to see demos of some of this functionality, be sure to watch the replay of the Citus 12 Release party livestream.
Let’s dive in!
What is schema-based sharding?
Schema-based sharding means that tables from the same schema are placed on the same node, while different schemas may be on different nodes. That way, queries and transactions that involve a single schema can always be evaluated efficiently by a single node (read: without network overhead), while the system can transparently scale out to accommodate an arbitrarily large amount of data and high rate of queries across different schemas. Moreover, the cluster can be rebalanced based on disk usage, such that large schemas automatically get more resources dedicated to them, while small schemas are efficiently packed together.
So far, Citus primarily focused on “row-based sharding”, where tables are hash-distributed across nodes based on the value in the distribution column. Row-based sharding enables arbitrarily large PostgreSQL tables, with parallel distributed queries, query routing based on filters, and distributed DML and DDL. Row-based sharding is very suitable for analytical applications (e.g. IoT, time series) and other scenarios in which you need very large tables. It also works well for multi-tenant applications that keep their data in a set of shared tables, but to be able to distribute your database effectively you to add a “tenant ID” column to all your tables, and include that column in all filters, inserts, foreign keys, etc. You also need to explicitly run create_distributed_table to select a distribution column for each table. If you skip one of these steps, performance might be poor due to network overhead, or you might run into distributed SQL limitations.
Schema-based sharding has almost no data modelling restrictions or special steps compared to unsharded PostgreSQL. That makes it easy to build a scalable multi-tenant application with a schema per tenant, or other applications where different parts of your data model can live in different schemas. The main restriction of schema-based sharding is that joins and foreign keys should only involve tables from the same schema (or reference tables), but transactions across schemas still work fine. That makes schema-based sharding much easier to use than row-based sharding, though it only makes sense for specific workload patterns. For applications that can use either model (e.g. multi-tenant apps), a downside of schema-based sharding is the need to manage many tables and performance overhead. A more detailed comparison is given below.
How to use Citus schema-based sharding for Postgres
You can easily get started with schema-based sharding by enabling the citus.enable_schema_based_sharding setting. When enabled, any schema you create will become a “distributed schema”.
-- Enable schema-based sharding!
set citus.enable_schema_based_sharding to on;
-- Create distributed schemas for two of my tenants
create schema tenant1;
create schema tenant2;
-- See my distributed schemas
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
tenant1 | 3 | 0 bytes | marco
tenant2 | 4 | 0 bytes | marco
(1 row)
Any table created in the tenant1 or tenant2 schema will now automatically become a “single shard” table that is "co-located" with all other tables in the schema. Compared to hash-distributed tables in Citus, single shard tables do not have a distribution column. There is only one shard per table, and all shards in the same schema live on the same node.
-- Create single shard tables in schema tenant1 (automatically co-located)
set search_path to tenant1;
create table note_categories (
category_id bigserial primary key,
category_name text not null);
create table notes (
note_id bigserial primary key,
category_id bigint references note_categories (category_id),
message text not null);
-- Create single shard tables in schema tenant2 (automatically co-located)
set search_path to tenant2;
create table note_categories (
category_id bigserial primary key,
category_name text not null);
create table notes (
note_id bigserial primary key,
category_id bigint references note_categories (category_id),
message text not null);
You can easily see where the tables live in the citus_shards view
select table_name, shardid, colocation_id, nodename, nodeport, shard_size
from citus_shards where citus_table_type = 'schema';
table_name | shardid | colocation_id | nodename | nodeport | shard_size
------------------------+---------+---------------+-----------+----------+------------
tenant1.note_categories | 102310 | 3 | wrk1.host | 5432 | 16384
tenant1.notes | 102311 | 3 | wrk1.host | 5432 | 16384
tenant2.note_categories | 102312 | 4 | wrk2.host | 5432 | 16384
tenant2.notes | 102313 | 4 | wrk2.host | 5432 | 16384
(4 rows)
Now, any query that involves only tables from the same schema will be transparently delegated to the right node. You can either set the search_path or use fully qualified names in your queries:
-- perform a query on different tenants using search_path and relative paths
set search_path to tenant1;
select * from notes join note_categories using (category_id);
set search_path to tenant2;
select * from notes join note_categories using (category_id);
-- perform a query on different tenants using fully-qualified names
select * from tenant1.notes join tenant1.note_categories using (category_id);
select * from tenant2.notes join tenant2.note_categories using (category_id);
You can run these queries from any node. We are also improving PgBouncer to handle search_path correctly when using schema-based sharding.
That’s pretty much it. To use schema-based sharding in Citus 12 or later, you create multiple schemas, and use search_path or fully qualified names to switch between schemas when creating tables or running queries. The schemas are transparently spread across nodes (starting on a single node) and can be rebalanced. No additional data modelling steps (like create_distributed_table) required!
In a follow up blog post, we’ll dive deeper into different usage scenarios and schema management.
Benefits of schema-based sharding in Citus and Postgres
Schema-based sharding gives you an easy path for sharding if your application and database model fits into one of these classes:
Multi-tenant applications (schema per tenant): Software as a service (SaaS) applications serve many different tenants from a single deployment, often backed by a single database for ease-of-management and cost efficiency. Most queries done by these SaaS applications can be scoped to a single tenant, which makes the tenant a natural shard key. You can shard your Citus database by creating a schema per tenant, as an alternative to distributing tables by a tenant ID column.
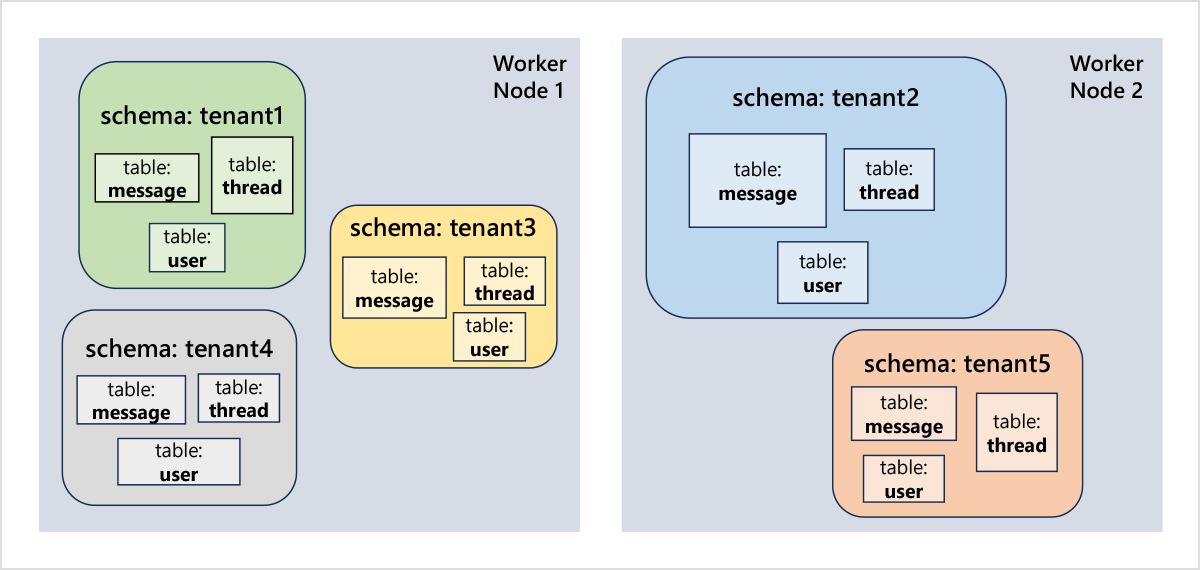
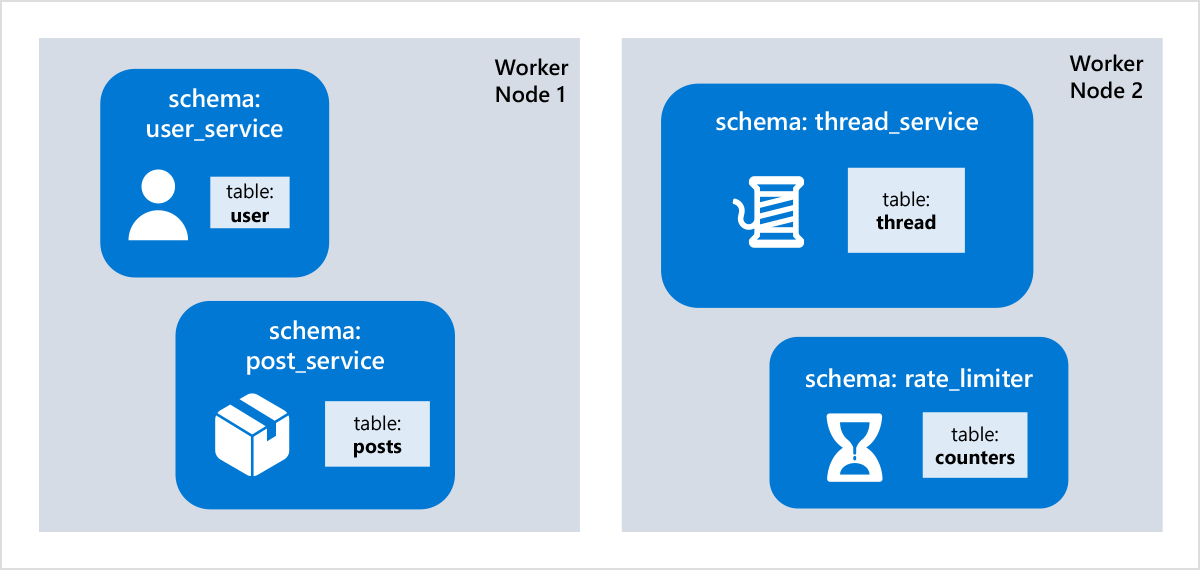
Microservices (schema per microservice): Many cloud-native applications are broken down into microservices that are developed and deployed separately. Each microservice has its own state, which is usually quite small, and simple. Rather than creating and managing a separate database system for each microservice, it is useful to consolidate the state of different microservices into a single distributed database. That way, you have a single place to manage and query all data, can share data and perform transactions across microservices, and can minimize cost by sharing resources, without the database becoming a bottleneck.
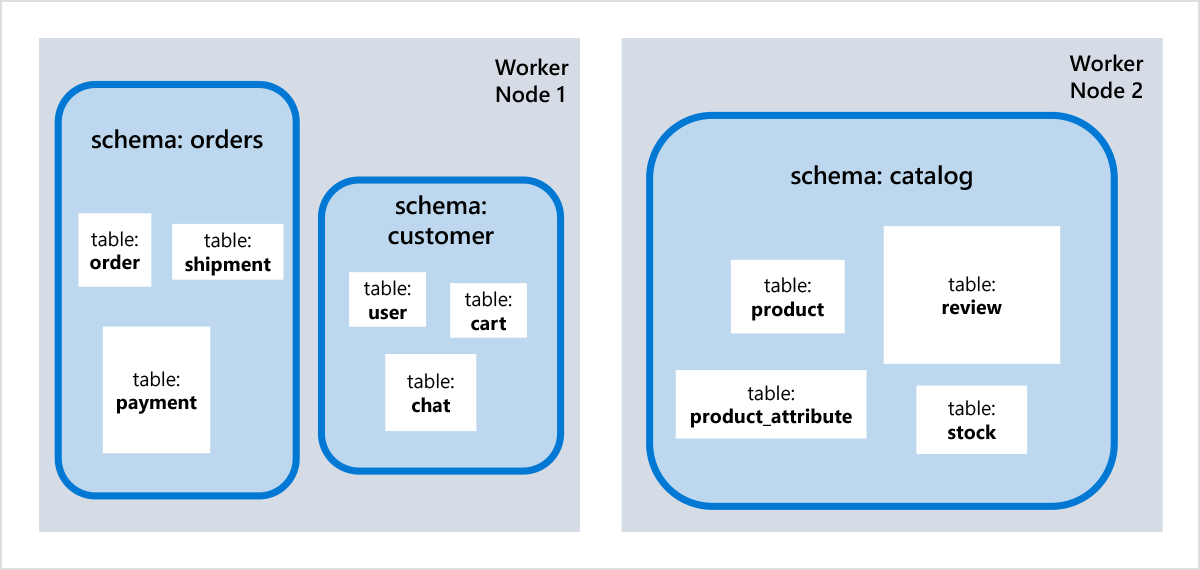
Vertical partitioning (schema per table group): The databases of complex OLTP applications often involve many different tables, and not all of them are closely related. “Vertical partitioning” refers to the practice of sharding your database into groups related tables with each group living on its own database server. With schema-based sharding, you can easily achieve this or prepared for it upfront by assigning each group to its own schema and scale out only when necessary (and avoid all the growing pains).
Within a distributed schema, you can use arbitrary joins and foreign keys. Transactions that remain scoped to a schema will be efficiently delegated to the node that stores the schema, which minimizes overhead and gives you PostgreSQL performance characteristics at any scale. Distributed transactions across schemas are still possible, with some additional network round trips.
Schema-based sharding offers many other benefits over manual, application-level sharding:
- Very easy shard management: Just CREATE/DROP SCHEMA, and Citus does the rest.
- Automatic rebalancing of schemas across nodes without downtime.
- Share data across schemas using reference tables with support for local joins and foreign keys.
- Tenant-level statistics, which has been expanded in Citus 12 to treat schemas as tenants.
- Mixed distributed database modes, e.g. multi-tenancy apps where small tenants live in a shared table and large tenants have their own distributed schema. Or ultra-large tenants / microservices live in a regular schema with distributed tables, while others have a distributed schema.
- Transparent stored procedure call delegation by co-locating with a table in a distributed schema.
- Can manage all schemas via transactions.
And with all the flexibility that PostgreSQL and Citus already offer, the overall list of benefits can go on for a while.
Of course, everything in distributed databases is ultimately still a trade-off. One thing to consider is that having a very large number of schemas (or rather, tables) can create certain performance issues in PostgreSQL. For instance, each process keeps a separate catalog cache, which can cause high memory consumption when there are many tables. We recommend carefully considering your sharding model if you expect to have over 10k schemas. Queries and transactions that span multiple schemas may also be slower than on a single PostgreSQL node, and may incur certain SQL limitations.
Choosing a sharding model for multi-tenant SaaS applications
Schema-based sharding is only applicable if your application naturally divides into distinct groups of tables. For applications with a single large table (e.g. IoT measurements), row-based sharding is the obvious choice. However, for multi-tenant applications, row-based sharding (by tenant ID) and schema-based sharding (with a schema per tenant) are both very reasonable options, with different characteristics.
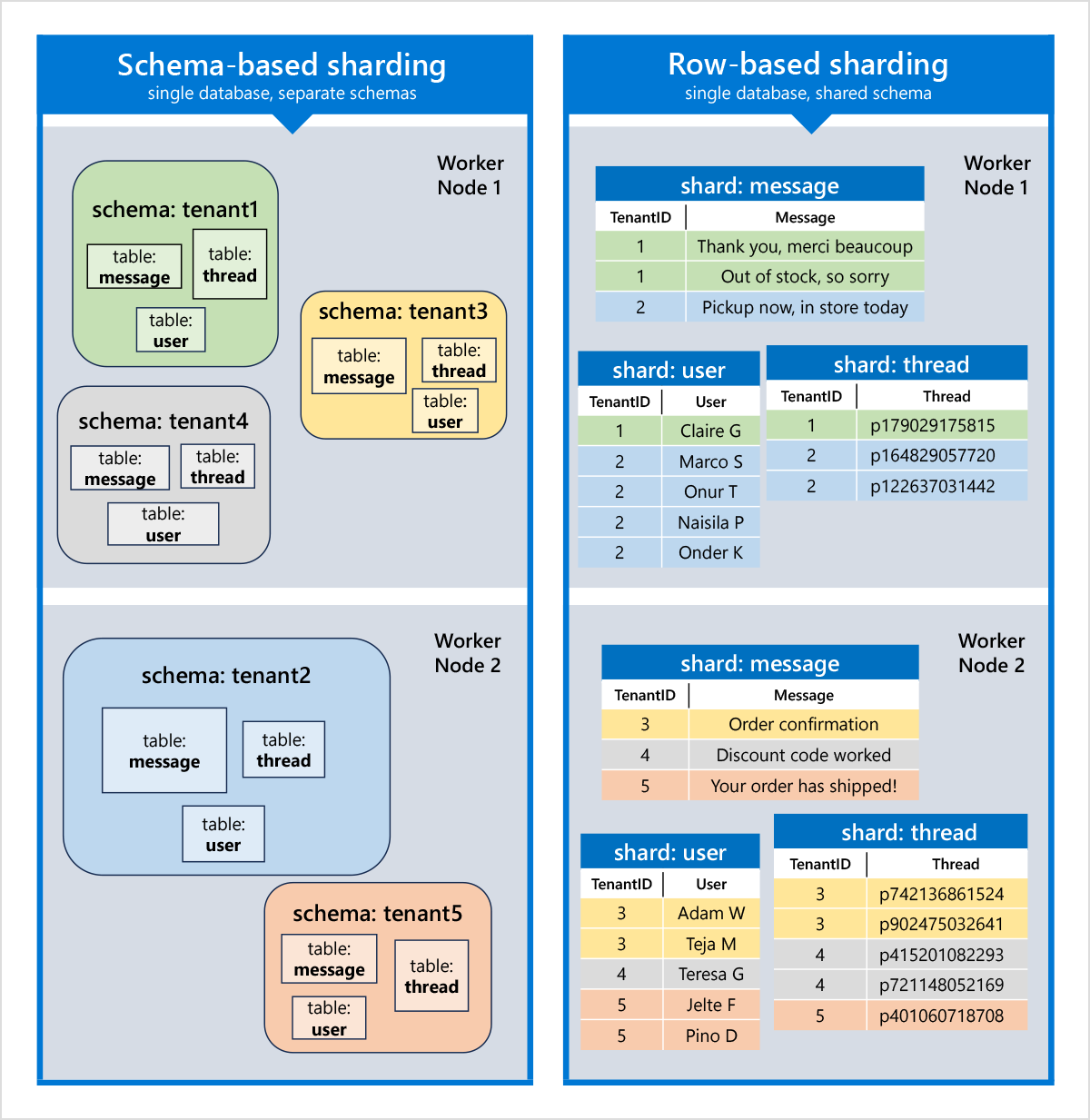
Each of these models has different pros and cons to consider:
Schema-based sharding: Each tenant has a separate schema with its own set of tables, in the same database. Tables do not have any restrictions with regards to constraints or foreign keys, except that foreign keys should not cross the schema boundary, unless they are foreign keys to reference tables. Schema-based sharding works especially well to scale applications that have many large tenants but might see performance degradation with a very large number of tenants (>10k).
Row-based sharding: The data from all tenants is in the same set of tables. Each table has a tenant ID column (or equivalent) which acts as the distribution column. Tables are co-located such that the same tenant ID lives on the same node, across different tables. Primary keys, foreign keys, joins, and filter should include the tenant ID column to ensure operations can be evaluated locally. Very large tenants should be isolated to their own shard.
A high-level comparison of these sharding models (in the context of multi-tenant applications) is given below:
| Schema-based sharding | Row-based sharding | |
|---|---|---|
| Multi-tenancy model | Separate schema per tenant | Shared tables with tenant ID columns |
| Citus version | 12.0+ | All versions |
| Additional steps compared to vanilla PostgreSQL | None, only a config change | Use create_ |
| Number of tenants | 1-10k | 100-1M+ |
| Data modelling requirement | No foreign keys across distributed schemas. | Need to include a tenant ID column and use it as the a distribution column in each table, and include it in primary keys, foreign keys. |
| SQL requirement for single node queries | Use a single distributed schema per query. | Joins and WHERE clauses should include tenant_id column |
| Parallel cross-tenant queries | No | Yes |
| Custom table definitions per tenant | Yes | No |
| Access control | Schema permissions | Row-level security |
| Data sharing across tenants | Yes, using reference tables (in a separate schema) | Yes, using reference tables |
| Tenant to shard isolation | Every tenant has its own shard group by definition | Can give specific tenant IDs their own shard group via isolate_ |
Which model to choose depends on your requirements. The biggest benefit of schema-based sharding is ease-of-use; no additional data modelling steps are required, only a single setting change. If you have a smaller number of large tenants (B2B), and some require a custom table definition or permissions, then schema-based sharding is also a great fit. If you have a very large number of small tenants (B2C) and want to simplify schema management and cross-tenant queries, then row-based sharding is likely to be a better fit.
If you need both, then consider that nothing prevents you from using one set of distributed tables for small tenants with row-based sharding, and separate distributed schemas for large tenants.
Migrating an existing schema-per-tenant application to Citus
One more thing… if you already have an existing PostgreSQL application that uses a schema per tenant, then you can easily migrate into a Citus cluster that uses schema-based sharding using pgcopydb, a powerful open-source database migration tool created by my colleague Dimitri Fontaine.
To see it in action, make sure citus.enable_schema_based_sharding = on is in your postgresql.conf and then run:
pgcopydb clone --source "host=source.host" --target "host=target.host" --restart --drop-if-exists --skip-extensions
You can also use the --follow option to replay writes that happen during the migration to avoid downtime. You should not make schema changes or create/drop schemas during the migration. We do recommend extensively testing your application before switching over, and reporting any issues via the Citus GitHub repo.
Extending the MERGE superpower in Citus 12
Schema-based sharding is super exciting and the biggest enhancement in Citus 12, but we also continue to improve Citus for other scenarios, including row-based multi-tenancy and Internet-of-things (IoT) scenarios.
PostgreSQL 15 introduced the MERGE command, which is especially useful when you receive a batch of records and you not only want to insert new records, but also update or delete existing records.
For instance, consider the following IoT scenario where we want to maintain a table of “active alerts” based on incoming measurements:
create table alerts (
alert_id bigserial primary key,
metric text not null,
upper_bound double precision not null);
create index on alerts (metric);
select create_reference_table('alerts');
create table active_alerts (
alert_id bigint not null,
device_id bigint not null,
alert_start_time timestamptz not null,
max_value double precision,
primary key (alert_id, device_id));
-- distributed by alert_id for fast lookup of all devices that are exceeding the threshold for a particular alert
select create_distributed_table('active_alerts', 'alert_id');
create table measurements (
measurement_id uuid not null default uuid_generate_v4(),
device_id bigint not null,
payload jsonb not null,
measurement_time timestamptz default now(),
primary key (device_id, measurement_id));
-- distributed by device_id_id for fast grouping by device_id
select create_distributed_table('measurements', 'device_id');
insert into alerts (metric, upper_bound) values ('temperature-9177', 38.0);
insert into measurements (device_id, payload) values (1, '{"value":37.5, "metric":"temperature-9177"}');
insert into measurements (device_id, payload) values (1, '{"value":38.5, "metric":"temperature-9177"}');
insert into measurements (device_id, payload) values (1, '{"value":38.6, "metric":"temperature-9177"}');
insert into measurements (device_id, payload) values (1, '{"value":38.7, "metric":"temperature-9177"}');
We want to periodically register all devices for which the last 3 measurements exceeded a particular threshold. When the last 3 measurements were all below the threshold, we want to delete it. We can do that using a MERGE command:
/* run every minute using pg_cron */
select cron.schedule('periodic-merge', '* * * * * ', $$
/* lets have some fun with (distributed) SQL */
merge into active_alerts aa
using (
/* select minimum and maximum value across last 3 measurements, per device */
select alert_id, device_id, min(value) as min_value, max(value) as max_value, upper_bound, max(measurement_time) as measurement_time
from (
/* get time-ordered measurements by device (latest is row_number 1) */
select
device_id,
payload->>'metric' as metric,
(payload->>'value')::double precision as value,
measurement_time,
row_number() over(partition by device_id order by measurement_time desc) as row_number
from measurements
) meas
join alerts on (meas.metric = alerts.metric)
where row_number <= 3
group by alert_id, device_id
) m
on aa.alert_id = m.alert_id AND aa.device_id = m.device_id
/* if the threshold is broken and the alert is not yet active, insert it */
when not matched and m.min_value > m.upper_bound then
insert values (m.alert_id, m.device_id, m.measurement_time, m.max_value)
/* if the threshold is broken and the alert is already active, update it */
when matched and m.max_value > aa.max_value then update set max_value = m.max_value
/* if the threshold is no longer broken but the alert is still active, delete it */
when matched and m.max_value <= m.upper_bound then delete;
$$);
What’s new in Citus 12 is that this MERGE works even though the measurements table and the active_alerts table are not co-located (their distribution columns do not match). The MERGE will re-partition the data across the cluster on the fly, in one parallel, distributed transaction. That makes MERGE the most advanced distributed database command available in Citus.
If you use MERGE in combination with schema-based sharding, then it will be fully pushed down to the node that stores the schema and handled by PostgreSQL.
Start building scalable apps
Schema-based sharding in Citus 12 gives you a new and easy way to scale out your PostgreSQL database. Whether you are an ISV building a multi-tenant SaaS application, microservices, or a complex OLTP workload that can use vertical partitioning, you can now easily tell Citus how to distribute the database by grouping tables into schemas without any special syntax. There are various application development libraries that will help you do this, but you can also easily build it yourself through simple commands like SET search_path TO <schema name> or using variables schema names in your queries.
To learn even more about what Citus 12.0 can do for you:
- Check out the 12.0 Updates page if you want to read through the detailed release notes
- Watch the replay of the Citus 12.0 Release Party livestream, with demos of schema-based sharding, tenant monitoring, and a PgBouncer update.
And if you want to get started distributing Postgres with Citus, the links in the bullets below should be useful:
- Citus open source repo on GitHub
- Getting started page for Citus
- Download Citus open source
- Citus open source docs
- Join the Citus Public Slack
- Quickstart docs for Citus on Azure, now known as Azure Cosmos DB for PostgreSQL… Since Citus 12.0 is just released, it is not yet available on Azure but it will be soon. Oh, and there is a free trial, too.
