📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
This post by Marco Slot about Postgres stored procedures in Citus was originally published on the Azure Database for PostgreSQL Blog on Microsoft TechCommunity.
Update in October 2022: Citus has a new home on Azure! The Citus database is now available as a managed service in the cloud as Azure Cosmos DB for PostgreSQL. Azure documentation links have been updated throughout the post, to point to the new Azure docs.
Stored procedures are widely used in commercial relational databases. You write most of your application logic in PL/SQL and achieve notable performance gains by pushing this logic into the database. As a result, customers who are looking to migrate from other databases to PostgreSQL usually make heavy use of stored procedures.
When migrating from a large database, using the Citus extension to distribute your database can be an attractive option, because you will always have enough hardware capacity to power your workload. The Hyperscale (Citus) option in Azure Database for PostgreSQL makes it easy to get a managed Citus cluster in minutes.
In the past, customers who migrated stored procedures to Citus often reported poor performance because each statement in the procedure involved an extra network round trip between the Citus coordinator node and the worker nodes. We also observed this ourselves when we evaluated Citus performance using the TPC-C-based workload in HammerDB (TPROC-C), which is implemented using stored procedures.
The good news is that this all changed in Citus 9.0, which introduced a feature called "distributed functions." Distributed functions can take away most of the network overhead in stored procedures for an important class of workloads—and we have further improved distributed Postgres functions in subsequent Citus releases. In HammerDB, these changes added up to give an order of magnitude speed up!
This blog post will show you how we achieved such a dramatic performance improvement in Citus—and why stored procedures are now a powerful technique for scaling transactional workloads on Postgres, with Citus.
Why stored procedures might not be such a bad idea
Stored procedures do have a poor reputation among some developers, which relates primarily to cases in which stored procedures are used to implement business logic. Business logic is certainly much easier to maintain outside the database where you have all your infrastructure for updates, logging, monitoring, debugging, testing, etc. However, using stored procedures and putting business logic in your database are really two different things.
Stored procedures can help you create a well-defined API for your Postgres database. Having a well-defined API means that you decouple your application logic from your database schema and can update them independently. Without that, it's super hard to do even simple things like changing a column name without downtime. In addition, the mapping between your application logic and your Postgres queries becomes very straight-forward, which helps you simplify your code. Most importantly, the efficiency gains you can realize with stored procedures are too big to ignore at scale.
Used correctly, stored procedures in Postgres give you a rare opportunity to simplify your code AND simplify operations AND get a significant performance and scalability boost.
Perhaps, as Rob Conery so eloquently put it, it's time to get over that stored procedure aversion you have.
The challenge of stored procedures in a distributed database like Citus
Distributed database performance is a complex topic and stored procedures show why.
Consider the following scenario:
A stored procedure performs 10 queries. On a single Postgres server, the execution time of each query is 1ms, so the overall procedure takes 10ms.
We then decide to distribute the tables across a large Citus cluster, which means we can keep all data in memory and queries execute in 0.1ms on the Citus worker nodes, but now each query also involves a 1ms network round trip between the Citus coordinator and the worker node, which means the overall procedure takes 11ms, even with a lot of extra hardware.
To solve this problem, we looked more closely at customer workloads. We noticed that stored procedures on Citus very often make repeated network round trips to the same Citus worker node. For instance, a stored procedure in a SaaS / multi-tenant application typically only operates on a single tenant. That means that, in theory, all the work in the stored procedure could be delegated to the worker node that stores the data for that tenant in a single network round trip.
Delegating stored procedure calls using distributed functions
Delegating stored procedure calls to the node that stores the relevant data is not a new idea. VoltDB by Michael Stonebraker and PL/proxy were architected entirely around the idea of scaling the database by executing procedures within a partition boundary, but as database systems they are a lot more restrictive than Citus.
Citus users can write PL/pgSQL stored procedures (defined as a function or procedure) that contain arbitrary queries on distributed tables. As we mentioned, stored procedures often operate on a single Citus worker node, but nothing prevents them from operating across multiple worker nodes.
To achieve scalability without losing functionality, we introduced the concept of "distributed functions" which can be called on any worker node and can perform arbitrary queries. When you create a distributed function, the Citus coordinator node replicates all its metadata to the Citus worker nodes automatically, such that the worker can act as a coordinator for any procedure call it receives.
You can additionally give a distributed function a "distribution argument" which corresponds to the "distribution column" of distributed tables. In that case, when calling the function or procedure on the Citus coordinator node, the call is delegated to the worker node that stores the distribution column value (e.g. tenant ID) given by the distribution argument. The figure below shows an example where the call to the delivery function.
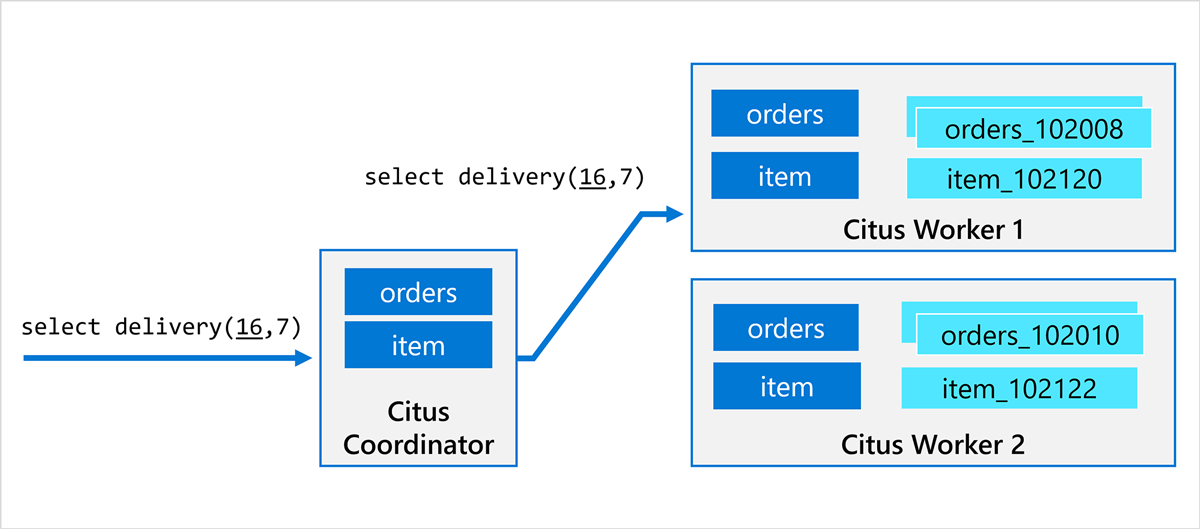
Ideally, the stored procedure uses the argument as a filter on the distribution column in all the queries, which means it only needs to access shards that are local to the worker node. If not, that's ok, because each Citus worker node can initiate a distributed transaction involving other worker nodes.
Distributed functions can be created by calling create_distributed_function on an existing function and procedure. For example, below are the complete set of steps we use to distribute tables and procedures generated by HammerDB when building the TPROC-C schema:
-- necessary only if you're using Citus open source, to activate metadata replication
set citus.replication_model = 'streaming';
-- distribute tables based on their warehouse ID columns (tables are automatically co-located)
SELECT create_distributed_table('customer', 'c_w_id');
SELECT create_distributed_table('district', 'd_w_id');
SELECT create_distributed_table('history', 'h_w_id');
SELECT create_distributed_table('warehouse', 'w_id');
SELECT create_distributed_table('stock', 's_w_id');
SELECT create_distributed_table('new_order', 'no_w_id');
SELECT create_distributed_table('orders', 'o_w_id');
SELECT create_distributed_table('order_line', 'ol_w_id');
SELECT create_reference_table('item');
…
-- distribute functions, using the first argument (warehouse ID) as the distribution argument, and co-locate with the warehouse table
SELECT create_distributed_function('delivery(int, int)', '$1', colocate_with := 'warehouse');
SELECT create_distributed_function('neword(int, int, int, int, int, int)', '$1', colocate_with := 'warehouse');
SELECT create_distributed_function('payment(int, int, int, int, numeric, int, numeric, varchar, varchar, numeric)', '$1', colocate_with := 'warehouse');
SELECT create_distributed_function('slev(int, int, int)', '$1', colocate_with := 'warehouse');
SELECT create_distributed_function('ostat(int, int, int, int, varchar)', '$1', colocate_with := 'warehouse');
-- just create this function on all the nodes (no distribution argument)
SELECT create_distributed_function('dbms_random(int,int)');
After these steps, every stored procedure call is delegated to the Citus worker node that stores warehouse ID specified in the first argument. Most of the time, the stored procedures pass on the argument as a filter to these distributed queries, which means almost all queries can be answered without network round trips.
The neword and payment procedures occasionally access multiple warehouses, which will result in the Citus worker node performing a distributed transaction.
When we first prototyped distributed functions in Citus, it still had one major performance issue: worker nodes were making TCP connections to themselves to query shards—causing significant overhead and limiting concurrency. We resolved that by introducing a complementary technique that we call "local execution."
Local execution avoids connections for local shards
Before we explore how local execution works, you probably should understand how Citus handles queries on distributed tables.
The Citus query planner intercepts queries on distributed tables via the PostgreSQL planner hooks. The Citus distributed query planner detects which shards are accessed based on distribution column filters in the query, and then generates a query tree for each shard. Each query tree is then "deparsed" back to SQL text, and the Citus query planner hands over the query plan to the distributed query executor. The executor sends SQL queries to worker nodes using PostgreSQL's standard connection library (libpq). Each Citus worker node executes its query and replies to the Citus coordinator node with the results.
This approach works well for most queries because only the coordinator connects to the worker nodes. However, with the distributed function approach, the Citus coordinator would connect to the Citus worker node and then the Citus worker node would connect to itself. Connections are a scarce resource in Postgres, so this approach limited achievable concurrency.
Fortunately, the Citus worker nodes do not really need a separate TCP connection to query the shard, since the shard is in the same database as the stored procedure. We therefore introduced local execution, to execute Postgres queries within a function locally, over the same connection that issued the function call. The following diagram outlines the Citus connection logic before and after the change.
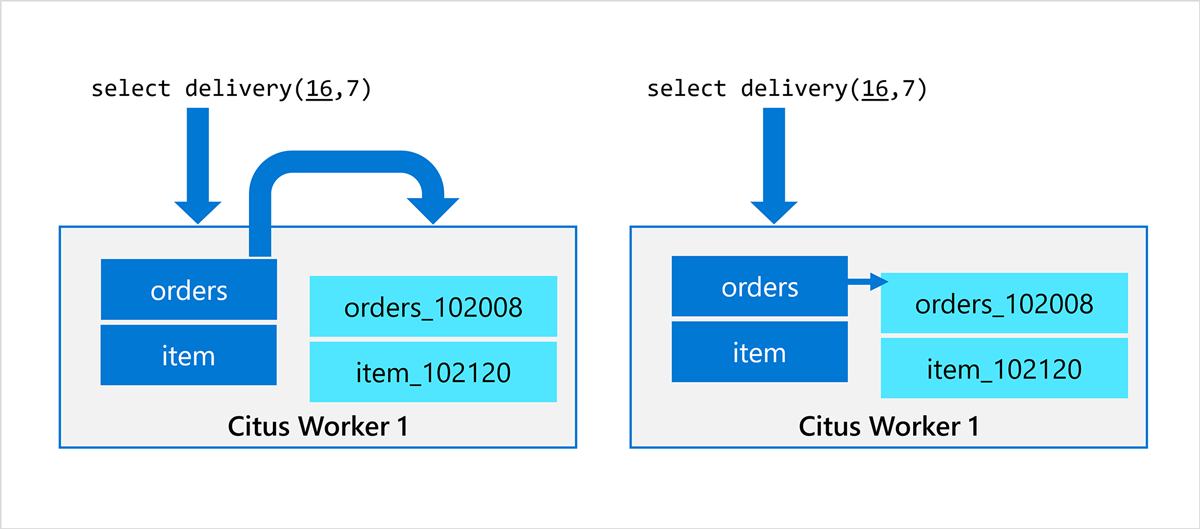
By introducing local execution, distributed functions incurred less overhead and we could achieve higher concurrency since it kept all connection slots available for stored procedure calls. After this change in Citus 9.0, throughput was only limited by the number of workers.
When running the HammerDB benchmark, we did find that the Citus worker nodes were relatively inefficient compared to a regular PostgreSQL server. We therefore implemented another optimization: plan caching.
Plan caching skips local planning overhead
PostgreSQL has the notion of prepared statements, which allow you to cache a query plan for multiple executions and skip the overhead of parsing and planning the same query many times. The Postgres planner tries to use a generic plan that works for any parameter value after 5 executions, as shown in the diagram below:
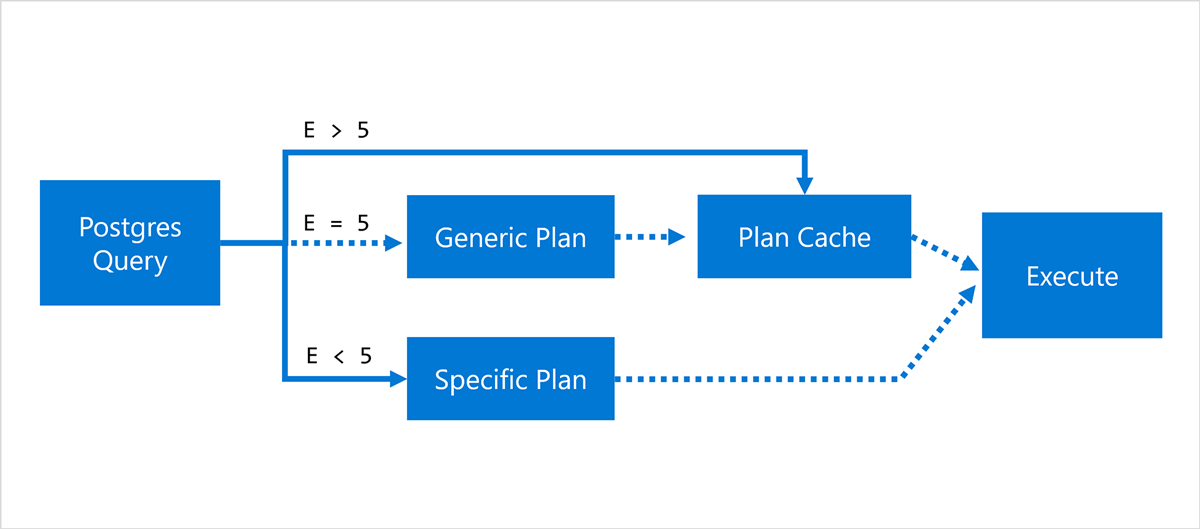
One of the benefits of writing a stored procedure in PL/pgSQL, is that Postgres automatically turns every SQL query into a prepared statement, but this logic did not immediately help Citus. The reason is that a Citus worker node contains multiple shards, and Citus does not know which one is going to be queried in advance.
The solution was simple: We cache the Postgres query plans for each of the local shards within the plan of the distributed query, and the distributed query plan is cached by the prepared statement logic. Since the number of local shards in Citus is typically small, this only incurs a small amount of memory overhead.
Plan caching in Citus 9.2 gives you another 30% performance improvement in HammerDB.
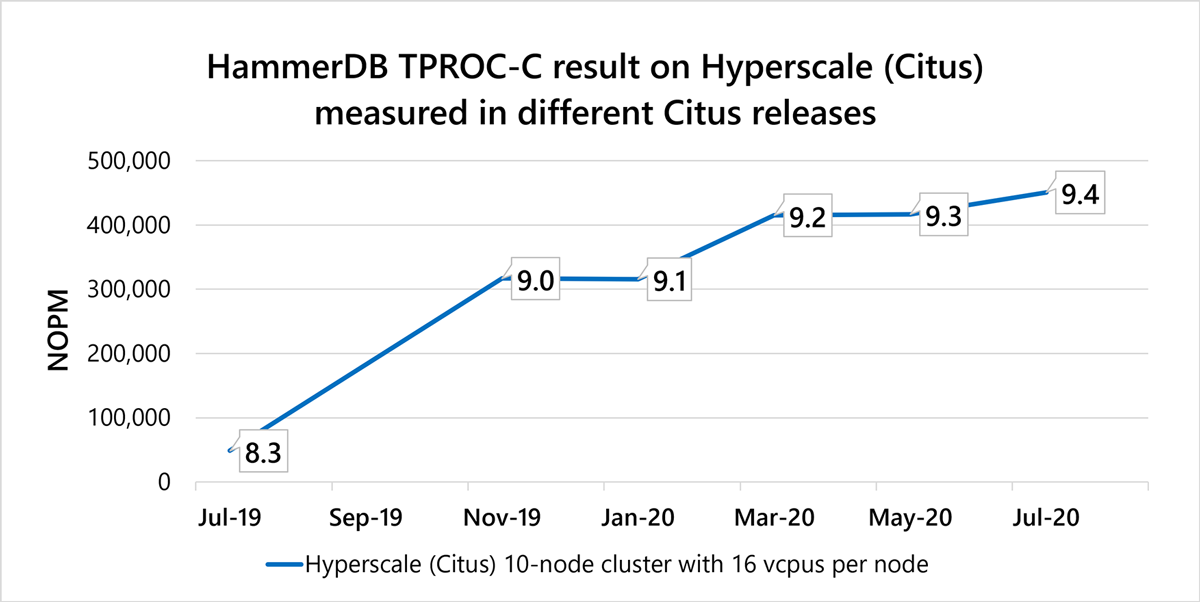
Stored procedure performance in Citus across releases
We released distributed functions and local query execution changes in Citus 9.0, plan caching in Citus 9.2, and additional performance improvements in the Citus 9.4 release.
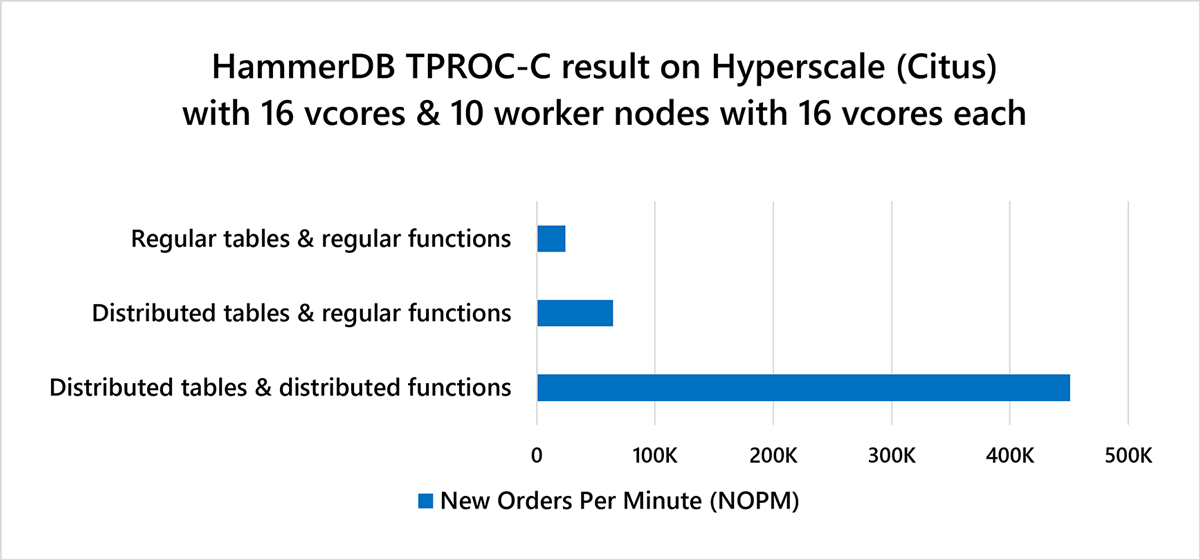
The result: improved performance in the HammerDB benchmark by 9X overall!
Running the TPROC-C workload using the HammerDB benchmarking tool on a 10-node Hyperscale (Citus) cluster on Azure Database for PostgreSQL, with 16 vcores per node:
- In Citus 9.0, improved from ~50k to 320K NOPM when using distributed functions. The NOPM refers to new order transactions per minute (roughly 43% of the total number of transactions).
- In Citus 9.2 (same configuration), improved further from 320K NOPM to approx. 420K NOPM
- In Citus 9.4, additional performance improvements increased overall HammerDB performance to 450K NOPM.
The following chart of HammerDB TPROC-C performance visualizes how we've improved the Citus stored procedure performance across these different Citus open source releases, as measured on Hyperscale (Citus) in Azure Database for PostgreSQL.
Stored procedures as a distributed database power feature
What is neat about all these changes is that we started from a place where stored procedures were best avoided in Citus and arrived at a place were stored procedures are a powerful way of scaling out Postgres OLTP workloads on Citus.
Stored procedures in PostgreSQL can be so helpful: they give you automatic plan caching, help you avoid network round trips in Citus, AND you can change your stored procedure along with your schema in a single distributed transaction (this last bit is still mind-blowing to me!) So, if you're migrating your procedures from a commercial database to Postgres—or if you find Postgres stored procedures a useful primitive—and you need your stored procedures to be ultra-fast and scalable, we recommend you use the new distributed function feature in Citus 😊.
Special thanks to Splendid Data who helped us come up with the idea for distributed functions during a brainstorming session on Oracle->Citus migrations last year.
