Watch 👀 the Citus 12.1 Release Party livestream replay—with demos + Q&A! 💬
The new PostgreSQL 16 release is out, packed with exciting improvements and features—and Citus 12.1 brings them to you at scale, within just one week of the PG16 release.
As many of you likely know, Citus is an open source PostgreSQL extension that turns Postgres into a distributed database. Our team started integrating Citus with the PG16 beta and release candidates early-on, so that you could have a new Citus 12.1 release that is compatible with Postgres 16 as quickly as possible after PG16 came out.
There are a lot of good reasons to upgrade to Postgres 16—huge thanks to everyone who contributed into this Postgres release! PG16 highlights include query performance boost with more parallelism; load balancing with multiple hosts in libpq (contributed by my Citus teammate, Jelte Fennema-Nio); I/O monitoring with pg_stat_io; developer experience enhancements; finer-grained options for access control; logical replication from standby servers and other replication improvements, like using btree indexes in the absence of a primary key (contributed by one of my teammates, Onder Kalaci.)
The good news for those of you who care about distributed Postgres: Citus 12.1 is now available and adds support for Postgres 16.
In addition to Postgres 16 support, Citus 12.1 includes enhancements to schema-based sharding, which was recently added to Citus 12.0—and is super useful for multi-tenant SaaS applications. In 12.1, you can now move tenant tables within a distributed schema to another node using the simple and powerful citus_schema_move() function. And you can manage permissions on creating distributed schemas more easily, too.
So if you’re a Citus user and you’re ready to upgrade to Postgres 16, you will also need to upgrade to Citus 12.1. (And if you use the Citus on Azure managed service, the answer is yes, Postgres 16 support is also coming soon to Azure Cosmos DB for PostgreSQL. Stay tuned for the next blog post.)
Let’s dive in to explore what’s new in 12.1.
- Postgres 16 support in Citus 12.1
- Schema-based sharding improvements
- Community contributions into Citus 12.1
To learn even more, you can always consult the Citus 12.1 Updates page which give you detailed release notes.
Postgres 16 support in Citus 12.1
Citus 12.1 adds support for Postgres 16. Among the many new capabilities in PG 16, these PostgreSQL 16 features enabled in Citus 12.1 are particularly interesting for Citus users:
- Load balancing when querying from any node
- pg_stat_io in a distributed Citus cluster
- Support for JSON_ARRAYAGG() and JSON_OBJECTAGG() aggregates
- Support for DEFAULT option to COPY FROM
- Propagate custom ICU collation rules
- Support for TRUNCATE triggers on Citus foreign tables
- Propagate new CREATE TABLE, VACUUM and ANALYZE options to Citus nodes
Load balancing when querying from any node
To handle a large number of read queries, load balancing is used to distribute the connections across multiple read replicas.
PostgreSQL 16 has introduced a new feature for load balancing multiple servers with libpq, that lets you specify a connection parameter called load_balance_hosts. By setting the load_balance_hosts parameter to random, libpq will randomly connect to different hosts and their associated IP addresses. This helps distribute the workload when there are multiple clients or frequent connection setups—and is especially useful for Citus when querying from any node, which is why the Citus team contributed it!
Query-from-any-node was the biggest enhancement in Citus 11.0—you can run distributed queries from any node in the cluster because the schema and metadata are automatically synchronized. You can use query-from-any-node to scale query throughput, by load balancing connections across the nodes. Some PostgreSQL clients (e.g. JDBC for Java, Npgsql for C#) already supported load-balancing, but now it is also supported in libpq, which is the PostgreSQL client that comes with PostgreSQL and forms the basis of most other PostgreSQL clients.
With this new load balancing feature in libpq, you can use your application as-is. Only add all the host names to the connections string, and utilize query-from-any-node. If your client is based on PostgreSQL 16, you can use load balancing by adding multiple comma-separate host names to your URL, and adding the load_balance_hosts argument:
psql "postgresql://{worker0}.postgres.cosmos.azure.com,{worker1}.postgres.cosmos.azure.com/?load_balance_hosts=random"
pg_stat_io in a distributed Citus cluster
To optimize the performance of your database workloads, it's crucial to grasp how your I/O operations affect your system. My Microsoft colleague Melanie Plageman added a new view called pg_stat_io to PostgreSQL 16, which shows essential I/O metrics for in-depth examination of I/O access patterns. You can also check out her CitusCon talk to get more detailed insight on what pg_stat_io provides. With the added PG16 support in Citus, you can inspect these monitoring metrics from the coordinator for all the nodes in your distributed cluster.
run_command_on_workers() is one of the existing Citus functions that will help you out here—check out the following example that runs a simple pgbench benchmark workload on a distributed Citus cluster with 1 coordinator and 2 worker nodes:
First, create the pgbench database and distribute the pgbench tables. The coordinator is in port 9700 in this example. After that, reset the io stats so that we have no stats before actually running the benchmark:
pgbench -i -s 100 -p 9700
psql -p 9700 -c "SELECT create_distributed_table('pgbench_accounts', 'aid')"
psql -p 9700 -c "SELECT create_distributed_table('pgbench_branches', 'bid')"
psql -p 9700 -c "SELECT create_distributed_table('pgbench_history', 'tid')"
psql -p 9700 -c "SELECT create_distributed_table('pgbench_tellers', 'tid')"
psql -p 9700 -c "VACUUM ANALYZE"
psql -p 9700 -c "SELECT pg_stat_reset_shared('io')" # coordinator
psql -p 9701 -c "SELECT pg_stat_reset_shared('io')" # worker1
psql -p 9702 -c "SELECT pg_stat_reset_shared('io')" # worker2
Then, run the pgbench test for 15 seconds with 5 clients:
pgbench -T 15 –c 5 -p 9700
Now, for the magical part – connect to your coordinator to explore pg_stat_io:
-- check out the io stats in the coordinator with the following query
-- since the data resides in the workers and we reset the stats right before the pgbench test,
-- coordinator io stats appear empty for now
SELECT backend_type, object, context, reads, writes, writebacks,
extends, hits, evictions, fsyncs FROM pg_stat_io
WHERE reads > 0 OR writes > 0;
backend_type | object | context | reads | writes | writebacks | extends | hits | evictions | fsyncs
--------------+--------+---------+-------+--------+------------+---------+------+-----------+--------
(0 rows)
-- the real io stats come from the workers
-- we have written this query for you to get the worker io stats to the coordinator
-- you can copy/paste and reuse this query as you wish
WITH workers_stat_io AS ( SELECT * FROM run_command_on_workers
($$ SELECT coalesce(to_jsonb (array_agg(worker_stat_io.*)), '[{}]'::jsonb)
FROM (SELECT backend_type, object, context, reads, writes, writebacks,
extends, hits, evictions, fsyncs FROM pg_stat_io
WHERE reads > 0 OR writes > 0) AS worker_stat_io; $$))
SELECT * FROM jsonb_to_recordset((
SELECT jsonb_agg(all_workers_stat_io_as_jsonb.workers_stat_io_as_jsonb)::jsonb
FROM ( SELECT jsonb_array_elements(result::jsonb)::jsonb ||
('{"worker_port":' || nodeport || '}')::jsonb
AS workers_stat_io_as_jsonb FROM workers_stat_io)
AS all_workers_stat_io_as_jsonb))
AS ( worker_port integer, backend_type text, context text, reads bigint, writes bigint,
writebacks bigint, extends bigint, hits bigint, evictions bigint, fsyncs bigint);
worker_port | backend_type | context | reads | writes | writebacks | extends | hits | evictions | fsyncs
-------------+-------------------+---------+-------+--------+------------+---------+-------+-----------+--------
9701 | client backend | normal | 3869 | 0 | 0 | 85 | 77616 | 3954 | 0
9701 | background writer | normal | | 2993 | 2944 | | | | 0
9702 | client backend | normal | 3809 | 0 | 0 | 145 | 77836 | 3954 | 0
9702 | background writer | normal | | 3056 | 3072 | | | | 0
9702 | checkpointer | normal | | 2 | 0 | | | | 0
(5 rows)
From being empty, immediately after the pgbench test pg_stat_io looks different on the workers. You can immediately notice how the client backends have performed multiple reads on each worker, and the background writers have performed multiple writes.
JSON_ARRAYAGG() and JSON_OBJECTAGG() aggregates
One of the highlights of the Postgres 16 release is the addition of SQL/JSON standard-conforming aggregates for JSON types, namely the JSON_ARRAYAGG() and JSON_OBJECTAGG() aggregates.
Prior to Postgres 16, Citus already supported and parallelized most PostgreSQL aggregate functions—and as of Citus 12.1, Citus now supports the new JSON_ARRAYAGG() and JSON_OBJECTAGG() aggregates. Check out the following example for a simple tip on how the JSON_ARRAYAGG() aggregate executes in the Citus distributed database:
-- create, distribute and populate the table
CREATE TABLE agg_test(country text, city text);
SELECT create_distributed_table('agg_test', 'country', shard_count := 2);
INSERT INTO agg_test VALUES ('Albania', 'Tirana'), ('Albania', 'Shkodra'), ('Albania', 'Elbasan');
INSERT INTO agg_test VALUES ('Turkey', 'Ankara'), ('Turkey', 'Istanbul');
-- change this config to be able to see how the JSON_ARRAYAGG aggregate is executed
SET citus.log_remote_commands TO on;
-- use JSON_ARRAYAGG() grouped on the table’s distribution column: country
-- in this way you get maximum performance from your Citus distributed database
-- Citus can push down execution of the entire query to each worker node, with ports 9701 and 9702
SELECT country, JSON_ARRAYAGG(city),
JSON_ARRAYAGG(city RETURNING jsonb) AS json_arrayagg_jsonb
FROM agg_test GROUP BY country;
NOTICE: issuing SELECT country, JSON_ARRAYAGG(city RETURNING json) AS "json_arrayagg", JSON_ARRAYAGG(city RETURNING jsonb) AS json_arrayagg_jsonb FROM public.agg_test_14000 GROUP BY country
DETAIL: on server postgres@localhost:9701 connectionId: 5
NOTICE: issuing SELECT country, JSON_ARRAYAGG(city RETURNING json) AS "json_arrayagg", JSON_ARRAYAGG(city RETURNING jsonb) AS json_arrayagg_jsonb FROM public.agg_test_14001 GROUP BY country
DETAIL: on server postgres@localhost:9702 connectionId: 6
country | json_arrayagg | json_arrayagg_jsonb
---------+----------------------------------+----------------------------------
Albania | ["Tirana", "Shkodra", "Elbasan"] | ["Tirana", "Shkodra", "Elbasan"]
Turkey | ["Ankara", "Istanbul"] | ["Ankara", "Istanbul"]
(2 rows)
DEFAULT option to COPY FROM
Everyone loves a nice and simple COPY command to populate their PostgreSQL and Citus tables.
If you have defined a default value in a specific column of your distributed table, then with PG16 you can control in which rows you want to insert the default value for that specific column, and in which rows you want to insert a defined non-default value. This control is achieved by choosing a specific string with the new DEFAULT option in PG16, that is also supported and propagated in Citus. Each time that specific string is found in the input file, the default value of the corresponding column will be used.
See below for a simple example using this new PG16 default in COPY FROM with Citus distributed tables:
-- create a table with default value columns and distribute it
-- using a similar example as in Postgres tests, but with a distributed table
CREATE TABLE dist_table_copy_default(
id int,
text_value text NOT NULL DEFAULT 'default_value_for_text',
ts_value timestamp without time zone NOT NULL DEFAULT '2023-09-21');
SELECT create_distributed_table('dist_table_copy_default', 'id');
-- perform COPY FROM operation with DEFAULT option specified
COPY dist_table_copy_default FROM stdin WITH (default '\D');
1 value '2022-07-04'
2 \D '2022-07-03'
3 \D \D
\.
SELECT * FROM dist_table_copy_default ORDER BY id;
id | text_value | ts_value
----+------------------------+---------------------
1 | value | 2022-07-04 00:00:00
2 | default_value_for_text | 2022-07-03 00:00:00
3 | default_value_for_text | 2023-09-21 00:00:00
(3 rows)
Propagation of Postgres 16’s new custom collation rules
PG16 allows custom ICU collation rules to be created using the new rules option in the CREATE COLLATION command. Citus already supports distributed collations, and in Citus 12.1 we added the propagation of the new PG16 collation rules option as well.
Below you can find a simple example of how the rules option is useful and how it’s propagated to the worker nodes in the Citus database:
CREATE COLLATION default_rule (provider = icu, locale = '');
-- let’s put a special rule here, and see how it propagates to the worker nodes
-- this test is similar with the Postgres test with the "&a < g" rule
-- "&b < s" places "s" after "b" and before "c", and the "b" does not change place.
SET citus.log_remote_commands TO on;
CREATE COLLATION special_rule (provider = icu, locale = '', rules = '&b < s');
NOTICE: issuing SELECT worker_create_or_replace_object('CREATE COLLATION public.special_rule (provider = ''icu'', locale = ''und'', rules = ''&b < s'')');
DETAIL: on server postgres@localhost:9701 connectionId: 1
NOTICE: issuing SELECT worker_create_or_replace_object('CREATE COLLATION public.special_rule (provider = ''icu'', locale = ''und'', rules = ''&b < s'')');
DETAIL: on server postgres@localhost:9702 connectionId: 2
RESET citus.log_remote_commands;
-- Create and distribute a table
CREATE TABLE test_collation_rules (a text);
SELECT create_distributed_table('test_collation_rules', 'a');
-- insert values that reflect sorting changes with '&b < s' rule
INSERT INTO test_collation_rules VALUES ('Berat'), ('bird'), ('cat'), ('Cerrik'), ('Shkodra'), ('sheep');
-- compare different orders using the default and the special rule '&b < s'
SELECT array_agg(a ORDER BY a COLLATE default_rule) FROM test_collation_rules
UNION
SELECT array_agg(a ORDER BY a COLLATE special_rule) FROM test_collation_rules;
array_agg
---------------------------------------
{Berat,bird,cat,Cerrik,sheep,Shkodra}
{Berat,bird,sheep,cat,Cerrik,Shkodra}
(2 rows)
TRUNCATE triggers on Citus foreign tables
Postgres 16 has added support for TRUNCATE triggers on foreign tables, which can be useful for audit logging and especially for preventing undesired truncation.
With Citus 12.1, you can use PG16’s new TRUNCATE triggers feature with Citus foreign tables as well. In Citus 11.0 we enabled adding foreign tables to Citus metadata. Citus foreign tables are citus managed local tables, i.e. single-sharded tables added to Citus metadata, and also propagated to the worker nodes in a Citus distributed cluster. So, these foreign tables can be accessed easily from each node. And now in 12.1, you can also create useful TRUNCATE triggers on them.
Here’s an example with a dummy trigger that demonstrates how the feature works:
-- prepare the environment for Citus managed local tables
SELECT citus_add_node('localhost', :master_port, groupid => 0);
SET citus.use_citus_managed_tables TO ON;
-- create a foreign table using the postgres_fdw extension
CREATE TABLE foreign_table_test (id integer NOT NULL, data text);
CREATE EXTENSION postgres_fdw;
CREATE SERVER foreign_server FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (host 'coordinator_host', port :'coordinator_port', dbname 'dbname');
CREATE USER MAPPING FOR CURRENT_USER SERVER foreign_server OPTIONS (user 'postgres');
CREATE FOREIGN TABLE foreign_table (id integer NOT NULL, data text)
SERVER foreign_server OPTIONS (table_name 'foreign_table_test');
-- see that it's a Citus foreign table
SELECT partmethod, repmodel FROM pg_dist_partition
WHERE logicalrelid = 'foreign_table'::regclass ORDER BY logicalrelid;
partmethod | repmodel
-----------------------
n | s
(1 row)
-- insert data
INSERT INTO foreign_table VALUES (1, 'text_test'), (2, 'test_2'), (3, 'test_3');
-- create a simple TRUNCATE trigger on the Citus foreign table
CREATE FUNCTION trigger_func() RETURNS trigger LANGUAGE plpgsql AS $$
BEGIN
RAISE NOTICE 'trigger_func() called: action = %, when = %, level = %', TG_OP, TG_WHEN, TG_LEVEL;
RETURN NULL;
END;$$;
CREATE TRIGGER trig_stmt_before BEFORE TRUNCATE ON foreign_table
FOR EACH STATEMENT EXECUTE PROCEDURE trigger_func();
-- here the raised notice will let us know that the trigger has been activated
TRUNCATE foreign_table;
NOTICE: trigger_func() called: action = TRUNCATE, when = BEFORE, level = STATEMENT
NOTICE: executing the command locally: TRUNCATE TABLE public.foreign_table_102201 CASCADE
New options in CREATE TABLE, VACUUM, and ANALYZE
You can now specify the STORAGE attribute when creating a new table in PG16, which sets the storage mode for a column. This attribute controls whether the column is held inline or in a secondary TOAST table, and whether the data should be compressed or not. With Citus 12.1 and later, each shard will reflect this STORAGE attribute, if specified. Yet another detail that seamlessly propagates in your distributed cluster.
PG16 allows control of the shared buffer usage by VACUUM and ANALYZE through the new BUFFER_USAGE_LIMIT option. You can also instruct VACUUM to only process TOAST tables through the new PROCESS_MAIN option. And lastly, there are new options to skip or update all frozen statistics. Citus does not interfere with the VACUUM and ANALYZE processes, but we do need to propagate these commands to the shards in order for the Postgres process to complete successfully on your distributed tables. This propagation functionality has also been added to Citus 12.1.
Schema-based sharding improvements
Citus 12 added a new and easy way to transparently scale your Postgres database: Schema-based sharding, where the database is transparently sharded by schema name.
Schema-based sharding gives an easy path for scaling out several important classes of applications that can divide their data across schemas, like multi-tenant SaaS applications and microservices that use the same database. Each newly-created schema becomes a logical shard of your database, ensuring that all tables for a given tenant are stored on the same node.
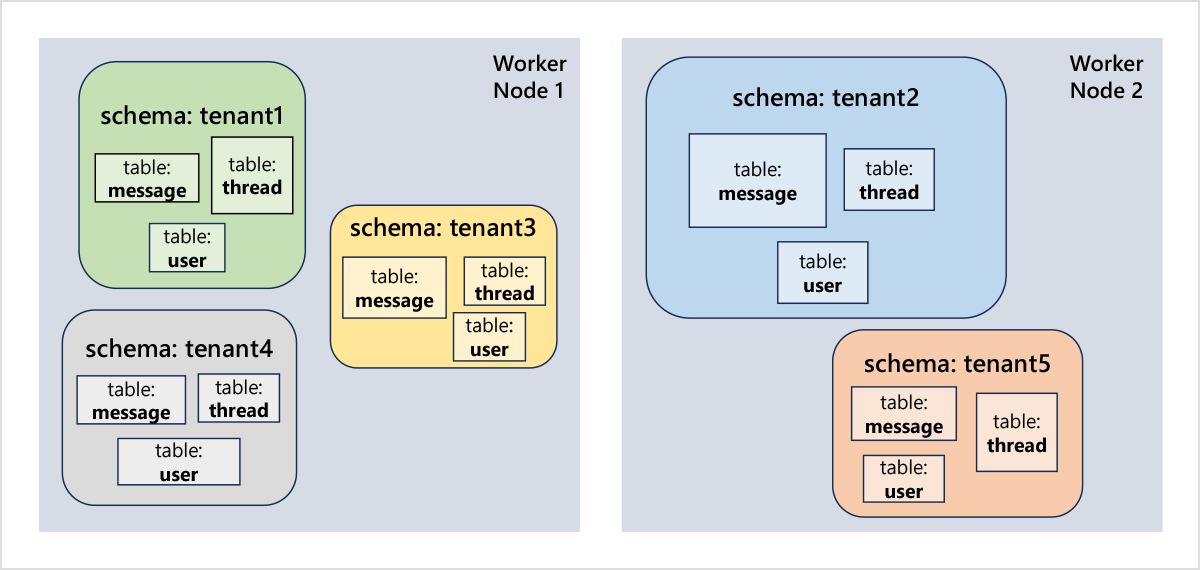
Citus 12.1 brings numerous additions and improvements to schema-based sharding, including:
- Distributed schema moves at your fingertips
- GRANT … ON DATABASE propagation
- Support for creating distributed schema tables from Citus local tables with identity columns
Distributed schema moves at your fingertips
To rebalance your Citus cluster with schema-based sharding, you can simply use the citus_rebalance_start() function. If you would like more control in deciding where should a specific set of tenant tables be, you can instead use the new Citus 12.1 citus_schema_move() function. All you need to do is specify the schema name and the target node (and optionally the shard transfer mode).
-- move the schema named tenant4 to node 3
SELECT citus_schema_move('tenant4', target_node_id := 3);
Note that if you later run citus_rebalance_start, Citus may decide to move the schema again. We will provide a persistent tenant-to-node isolation feature in a future release.
Manage schema permissions with GRANT … ON DATABASE propagation
Another improvement we made for schema-based sharding in Citus 12.1 is to propagate GRANT .. ON DATABASE commands. Schema-based sharding implies creating many schemas. Normally, only the administrative user (e.g. the "citus" user in the Azure Cosmos DB for PostgreSQL managed service, aka “Citus on Azure”) can create schemas. To allow other database users to create schemas, you would need to run GRANT CREATE ON DATABASE, but so far Citus did not automatically propagate database-level commands.
With Citus 12.1, we are making a first step by propagating GRANT .. ON DATABASE, which also enables you to manage permissions on create distributed schemas.
-- assume we are using the database named my_database
-- by default, a new user cannot create distributed schemas on it
CREATE USER my_user;
SET ROLE my_user;
CREATE SCHEMA tenant1;
ERROR: permission denied for database my_database
RESET ROLE;
-- let’s test the grant CREATE privilege propagation on my_database
GRANT CREATE ON DATABASE my_database TO my_user;
SELECT has_database_privilege('my_user','my_database', 'CREATE');
has_database_privilege
---------------------------------------------------------------------
t
(1 row)
SELECT nodeport, result FROM
run_command_on_workers($$SELECT has_database_privilege('my_user','my_database', 'CREATE')$$)
nodeport | result
----------+--------
9701 | t
9702 | t
(2 rows)
-- now we can create a distributed schema with my_user
SET ROLE my_user;
CREATE SCHEMA tenant1;
SELECT * FROM citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
tenant1 | 4 | 0 bytes | my_user
(1 row)
Support for creating distributed schema tables from local tables added to metadata and that use identity columns
Citus adds local tables into metadata when they are involved in a foreign key relationship with a reference table to ensure that the foreign key constraint is properly enforced in a distributed environment.
Before Citus 12.1, it was not possible to create a distributed schema table from such a local table if it uses an identity column. With this release, Citus lifts this limitation.
CREATE TABLE products (
id int GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
name text,
price numeric
);
CREATE SCHEMA big_market;
CREATE TABLE big_market.orders (
id bigint GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
product_id int REFERENCES products(id),
quantity integer,
date date
);
-- This automatically adds now-local "big_market.orders" table into
-- metadata to enforce the foreign key constraint.
SELECT create_reference_table('products');
-- This was failing before Citus 12.1 with the following error message:
-- ERROR: cannot complete operation on a table with identity column
SELECT citus_schema_distribute('big_market');
NOTICE: distributing the schema big_market
If you use a tool like django-tenants with schema-based sharding in Citus, you have now more flexibility given that identity columns are used by Django.
Special thanks in Citus 12.1 for Community Contributions
We always love seeing community contributions. So we are really excited and grateful about these Citus 12.1 commits.
We would like to thank Ivan Vyazmitinov for his improvements to 2PC recovery when using Citus in multiple databases. While we generally do not recommend using Citus in multiple databases, we are gradually improving support and Ivan's patch solves a significant operational issue.
We would also like to thank zhjwpku for his metadata cache improvements, code compatibility enhancements, and other contributions.
Diving deeper into Citus 12.1 and distributed Postgres
To get into more details of the Citus 12.1 new additions, you can:
- Check out the 12.1 Updates page to get the detailed release notes.
- Watch the replay of the Citus 12.1 Release Party livestream to see demos and learn more about what’s new in Citus 12.1, including the Postgres 16 support.
You can also stay connected on the Citus Slack and visit the Citus open source GitHub repo to see recent developments as well. If there’s something you’d like to see next in Citus, feel free to also open a feature request issue :)
