📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
Citus is a PostgreSQL extension that makes PostgreSQL scalable by transparently distributing and/or replicating tables across one or more PostgreSQL nodes. Citus could be used either on Azure cloud, or since the Citus database extension is fully open source, you can download and install Citus anywhere you like.
A typical Citus cluster consists of a special node called coordinator and a few worker nodes. Applications usually send their queries to the Citus coordinator node, which relays them to worker nodes and accumulates the results. (Unless of course you’re using the Citus query from any node feature, an optional feature introduced in Citus 11, in which case the queries can be routed to any of the nodes in the cluster.)
Anyway, one of the most frequently asked questions is: “How does Citus handle failures of the coordinator or worker nodes? What’s the HA story?”
And with the exception of when you’re running Citus in a managed service in the cloud, the answer so far was not great—just use PostgreSQL streaming to run coordinator and workers with HA and it is up to you how to handle a failover.
In this blog post, you’ll learn how Patroni 3.0+ can be used to deploy a highly available Citus database cluster—just by adding a few lines to the Patroni configuration file. Let’s take a walk through these topics:
- What is Patroni?
- Introducing Citus support in Patroni 3.0
- Our first distributed Citus cluster with Patroni
- Our first HA switchover with Patroni and Citus
- Future plans & possible improvements
- Conclusion: Patroni and Citus together for distributed PostgreSQL HA
Terminology clarification: the many competing meanings of “cluster”
In the Postgres world, the word “cluster” is used in many different contexts, and so it is easy to get confused. Here’s how we’re using the term:
- Database cluster (the SQL standard calls it the
catalog cluster): a collection of databases that is managed by a single instance of a running database server. - PostgreSQL cluster (or Patroni cluster): multiple database instances, primary with a few standby nodes, usually connected via streaming replication.
- Citus cluster: a distributed set of database nodes, formation of one or many PostgreSQL clusters logically connected using Citus extension to Postgres.
- Kubernetes cluster: a set of node machines for running containerized applications. Kubernetes could be used to deploy Citus or PostgreSQL clusters at scale.
In this blog post we will be mostly talking about distributed Citus clusters and PostgreSQL clusters managed by Patroni (or Patroni clusters.)
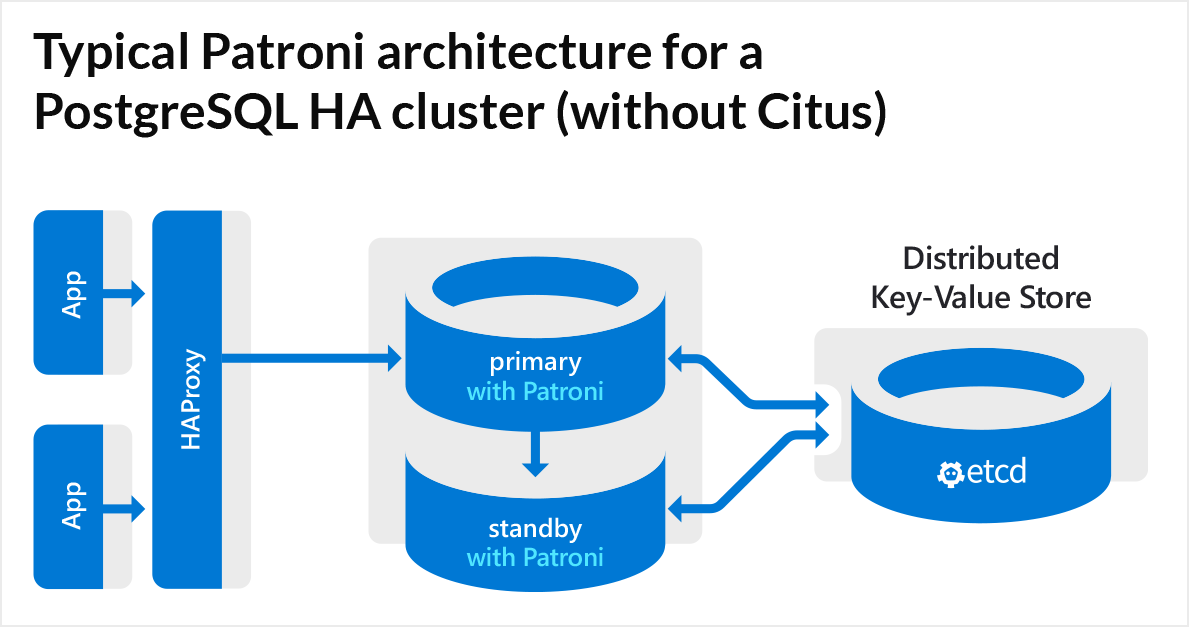
What is Patroni? (skip this if you already know)
Patroni is an open-source tool that helps to deploy, manage, and monitor highly available PostgreSQL clusters using physical streaming replication. The Patroni daemon runs on all nodes of PostgreSQL cluster, monitors the state of Postgres process(es), and publishes the state to the Distributed Key-Value Store.
There a few properties required from Distributed Key-Value (Configuration) Store (DCS):
- It must implement the consensus algorithm, like Raft, Paxos, Zab, or similar
- It must support Compare-And-Set operations
- It should have Sessions/Lease/TTL mechanisms to expire keys
- It is nice if it provides WATCH API, to subscribe and receive changes of certain keys
The last two properties are nice to have, but Patroni could still work if they are not supported/implemented, while the first two are mandatory.
Patroni supports the following DCS: etcd, Consul, ZooKeeper, and Kubernetes API:
- Consul and etcd implement Raft protocol
- ZooKeeper implements Zab
- Kubernetes API is backed by etcd
Every node of the Patroni/PostgreSQL cluster maintains a member key in DCS with its own name. The value of member key contains the address of the node (host and port), and state of PostgreSQL, like role (primary or standby), current Postgres LSN, tags, and so on. Member keys allow automatic discovery of all nodes of the given Patroni/PostgreSQL cluster.
Patroni running next to the Postgres primary also maintains the /leader key in DCS.
- The
/leaderkey has the limited TTL and expires if it doesn’t receive regular updates. - If the
/leaderkey is missing, standby nodes do the leader race trying to create the new/leaderkey. - Patroni on the node that created the new
/leaderkey promotes Postgres to the primary and Patroni on remaining standby nodes reconfigure Postgres to stream from the new primary. - What is important, that all operations on the
/leaderkey are protected with Compare-And-Set.
Patroni on standby nodes is using the /leader and member keys to figure out which nodes is the primary and configure governed Postgres to replicate from the primary. Besides Automatic Failover for HA, Patroni helps automating all kinds of management operations:
- Initialization of new nodes using pg_basebackup or 3rd-party backup tools like pgBackRest, wal-g/wal-e, barman, and so on
- Handles synchronous replication requirements
- Supports running pg_rewind after failover to join the old primary to the Postgres cluster as a standby
- Helps with PITR by initializing new PostgreSQL clusters from backup instead of using initdb
- And many more
Introducing Citus support in Patroni 3.0
Patroni 3.0 brings official Citus support to Patroni. While it was already possible to run Patroni with Citus before Patroni 3.0 (due to the flexibility and extensibility of Patroni!), the 3.0 release has made the integration with Citus for HA much better and easier to use.
Patroni is relying on DCS to discover nodes of the PostgreSQL cluster and configure streaming replication. As already explained in the “Terminology clarification” section, the Citus cluster is just a bunch of PostgreSQL clusters that are logically connected using Citus extension to Postgres. Hence, it was logical to extend Patroni so it could discover not only nodes of the given Patroni/PostgreSQL cluster, but also discover nodes in a Citus cluster, such as when a new Citus worker node has been added. As Citus nodes are discovered, they are added to the Citus coordinator pg_dist_node metadata.
There are only a few simple rules one should follow to enable Citus support in Patroni:
- Scope (cluster name): The scope must be the same for all Citus nodes
- Superuser username/password: The superuser username/password preferably should be the same on coordinator and worker nodes or you should configure superuser connections between nodes using client certificates. Of course, pg_hba.conf should allow superuser connections across all nodes.
- REST API access: Patroni REST API access should be allowed from worker nodes to the coordinator. E.g., credentials should be the same and if configured, client certificates from worker nodes must be accepted by the coordinator.
- Adding Citus to the Patroni configuration file: Add the following section to the
patroni.yaml. The full example of the Patroni configuration file is available on GitHub.
citus:
group: X # 0 for coordinator and 1, 2, 3, etc for workers
database: citus # must be the same on all nodes
That’s it! Now you can start Patroni and enjoy Citus integration.
Patroni will handle all of the following:
- The Citus extension will be automatically added to shared_preload_libraries (to the first place in the list!)
- If max_prepared_transactions is not explicitly set in the global dynamic configuration Patroni will automatically set it to 2*max_connections.
- The
citus.databasewill be automatically created followed byCREATE EXTENSION citus;. - Current superuser credentials (from patroni.yaml) will be added to the pg_dist_authinfo table to allow cross-node communication. Do not forget to update them if later you decide to change superuser username/password/sslcert/sslkey!
- The coordinator primary node will automatically discover worker primary nodes and add them to the pg_dist_node table using the citus_add_node() function.
- Patroni will also maintain pg_dist_node in case failover/switchover on the coordinator or worker clusters occurs.
- Last, but not least, Patroni will pause client connections on the coordinator primary when controlled switchover is executed on the worker cluster, so that clients will not get any visible error.
The diagram below is an example of Citus HA deployment with Patroni 3.0.0.

Our first distributed Citus cluster with Patroni
To deploy our test cluster locally we will use docker and docker-compose. The Dockerfile.citus is in the Patroni repository.
First, we need to clone Patroni repo and build patroni-citus docker image:
$ git clone https://github.com/zalando/patroni.git
$ cd patroni
$ docker build -t patroni-citus -f Dockerfile.citus .
Sending build context to Docker daemon 573.6MB
Step 1/36 : ARG PG_MAJOR=15
… skip intermediate logs
Step 36/36 : ENTRYPOINT ["/bin/sh", "/entrypoint.sh"]
---> Running in 1933967fcb58
Removing intermediate container 1933967fcb58
---> 0eea66f3c4c7
Successfully built 0eea66f3c4c7
Successfully tagged patroni-citus:latest
Once the image is ready, we will deploy the stack with:
$ docker-compose -f docker-compose-citus.yml up -d
Creating demo-etcd1 ... done
Creating demo-work1-2 ... done
Creating demo-coord2 ... done
Creating demo-coord3 ... done
Creating demo-work1-1 ... done
Creating demo-etcd2 ... done
Creating demo-work2-2 ... done
Creating demo-coord1 ... done
Creating demo-work2-1 ... done
Creating demo-haproxy ... done
Creating demo-etcd3 ... done
Now we can verify that containers are up and running:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e7740f00796d patroni-citus "/bin/sh /entrypoint…" About a minute ago Up About a minute demo-etcd2
8a3903ca40a7 patroni-citus "/bin/sh /entrypoint…" About a minute ago Up About a minute demo-etcd3
3d384bf74315 patroni-citus "/bin/sh /entrypoint…" About a minute ago Up About a minute 0.0.0.0:5000-5001->5000-5001/tcp demo-haproxy
2f6c9e4c63b8 patroni-citus "/bin/sh /entrypoint…" About a minute ago Up About a minute demo-work2-1
4bd35bfdba58 patroni-citus "/bin/sh /entrypoint…" About a minute ago Up About a minute demo-coord1
8dce43a4f499 patroni-citus "/bin/sh /entrypoint…" About a minute ago Up About a minute demo-work1-1
e76372163464 patroni-citus "/bin/sh /entrypoint…" About a minute ago Up About a minute demo-work2-2
0de7bf5044fd patroni-citus "/bin/sh /entrypoint…" About a minute ago Up About a minute demo-coord3
633f9700e86f patroni-citus "/bin/sh /entrypoint…" About a minute ago Up About a minute demo-coord2
f50bb1e1d6e7 patroni-citus "/bin/sh /entrypoint…" About a minute ago Up About a minute demo-etcd1
03bd34403ac2 patroni-citus "/bin/sh /entrypoint…" About a minute ago Up About a minute demo-work1-2
In total we have 11 containers:
- three containers with etcd (forming a three-node etcd cluster),
- seven containers with Patroni+PostgreSQL+Citus (three coordinator nodes, and two worker clusters with two nodes each), and
- one container with HAProxy.
The HAProxy listens on ports 5000 (connects to the Citus coordinator primary) and 5001 (which does load balancing between worker primary nodes):
In a few seconds, our Citus cluster will be up and running. We can verify it by using patronictl tool from the demo-haproxy container:
$ docker exec -ti demo-haproxy bash
postgres@haproxy:~$ patronictl list
+ Citus cluster: demo ---------+--------------+---------+----+-----------+
| Group | Member | Host | Role | State | TL | Lag in MB |
+-------+---------+------------+--------------+---------+----+-----------+
| 0 | coord1 | 172.19.0.8 | Sync Standby | running | 1 | 0 |
| 0 | coord2 | 172.19.0.7 | Leader | running | 1 | |
| 0 | coord3 | 172.19.0.6 | Replica | running | 1 | 0 |
| 1 | work1-1 | 172.19.0.5 | Sync Standby | running | 1 | 0 |
| 1 | work1-2 | 172.19.0.2 | Leader | running | 1 | |
| 2 | work2-1 | 172.19.0.9 | Sync Standby | running | 1 | 0 |
| 2 | work2-2 | 172.19.0.4 | Leader | running | 1 | |
+-------+---------+------------+--------------+---------+----+-----------+
Now, let's connect to the coordinator primary via HAProxy and verify that Citus extension was created and worker nodes are registered in coordinator metadata:
postgres@haproxy:~$ psql -h localhost -p 5000 -U postgres -d citus
Password for user postgres: postgres
psql (15.1 (Debian 15.1-1.pgdg110+1))
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off)
Type "help" for help.
citus=# \dx
List of installed extensions
Name | Version | Schema | Description
---------------+---------+------------+------------------------------
citus | 11.2-1 | pg_catalog | Citus distributed database
citus_columnar | 11.2-1 | pg_catalog | Citus Columnar extension
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(3 rows)
citus=# select nodeid, groupid, nodename, nodeport, noderole
from pg_dist_node order by groupid;
nodeid | groupid | nodename | nodeport | noderole
-------+---------+------------+----------+----------
1 | 0 | 172.19.0.7 | 5432 | primary
3 | 1 | 172.19.0.2 | 5432 | primary
2 | 2 | 172.19.0.4 | 5432 | primary
(3 rows)
So far, so good. :)
In this specific setup Patroni is configured to use client certificates in addition to passwords for superuser connections between nodes. Since Citus actively uses superuser connections to communicate between nodes, Patroni also took care about configuring authentication parameters via pg_dist_authinfo:
citus=# select * from pg_dist_authinfo;
nodeid | rolename | authinfo
-------+----------+--------------------------------------------------------------------------------------------------------------
0 | postgres | password=postgres sslcert=/etc/ssl/certs/ssl-cert-snakeoil.pem sslkey=/etc/ssl/private/ssl-cert-snakeoil.key
(1 row)
Don’t be scared by the password you see in the authinfo field. Why? Because first of all, access to pg_dist_authinfo is restricted to the superuser. Secondly, it is possible to setup authentication using only client certificates, what is actually the recommended way.
Our first HA switchover with Patroni and Citus
In Postgres HA terminology, and in Patroni terminology, a “switchover” is an intentional failover. It’s something that you do when you have planned maintenance and you need to trigger a failover yourself for some reason.
Before doing a switchover with Patroni, let’s first create a Citus distributed table and start writing some data to it using the \watch psql command:
citus=# create table my_distributed_table(id bigint not null generated always as identity, value double precision);
CREATE TABLE
citus=# select create_distributed_table('my_distributed_table', 'id');
create_distributed_table
--------------------------
(1 row)
citus=# with inserted as (
insert into my_distributed_table(value)
values(random()) RETURNING id
) SELECT now(), id from inserted\watch 0.01
The \watch 0.01 will execute the given query every 10ms and the query will return inserted id plus the current time with microsecond precession, so that we can see how the switchover affects it.
Meanwhile, in different terminal we will initiate a switchover on one of the worker nodes:
$ docker exec -ti demo-haproxy bash
postgres@haproxy:~$ patronictl switchover
Current cluster topology
+ Citus cluster: demo ---------+--------------+---------+----+-----------+
| Group | Member | Host | Role | State | TL | Lag in MB |
+-------+---------+------------+--------------+---------+----+-----------+
| 0 | coord1 | 172.19.0.8 | Sync Standby | running | 1 | 0 |
| 0 | coord2 | 172.19.0.7 | Leader | running | 1 | |
| 0 | coord3 | 172.19.0.6 | Replica | running | 1 | 0 |
| 1 | work1-1 | 172.19.0.5 | Sync Standby | running | 1 | |
| 1 | work1-2 | 172.19.0.2 | Leader | running | 1 | 0 |
| 2 | work2-1 | 172.19.0.9 | Sync Standby | running | 1 | 0 |
| 2 | work2-2 | 172.19.0.4 | Leader | running | 1 | |
+-------+---------+------------+--------------+---------+----+-----------+
Citus group: 2
Primary [work2-2]:
Candidate ['work2-1'] []:
When should the switchover take place (e.g. 2023-02-06T14:27 ) [now]:
Are you sure you want to switchover cluster demo, demoting current leader work2-2? [y/N]: y
2023-02-06 13:27:56.00644 Successfully switched over to "work2-1"
+ Citus cluster: demo (group: 2, 7197024670041272347) ------+
| Member | Host | Role | State | TL | Lag in MB |
+---------+------------+---------+---------+----+-----------+
| work2-1 | 172.19.0.9 | Leader | running | 1 | |
| work2-2 | 172.19.0.4 | Replica | stopped | | unknown |
+---------+------------+---------+---------+----+-----------+
Finally, after the switchover is completed let's check logs in the first terminal:
Mon Feb 6 13:27:54 2023 (every 0.01s)
now | id
------------------------------+------
2023-02-06 13:27:54.441635+00 | 1172
(1 row)
Mon Feb 6 13:27:54 2023 (every 0.01s)
now | id
-----------------------------+------
2023-02-06 13:27:54.45187+00 | 1173
(1 row)
Mon Feb 6 13:27:57 2023 (every 0.01s)
now | id
------------------------------+------
2023-02-06 13:27:57.345054+00 | 1174
(1 row)
Mon Feb 6 13:27:57 2023 (every 0.01s)
now | id
------------------------------+------
2023-02-06 13:27:57.351412+00 | 1175
(1 row)
As you may see, before the switchover happened, queries were consistently running every 10ms. Between ids 1173 and 1174 you may notice a short spike of latency, 2893ms (less than 3 seconds). This is how the controlled switchover manifested itself, producing no client errors!
After switchover has finished, we can again check pg_dist_node:
citus=# select nodeid, groupid, nodename, nodeport, noderole
from pg_dist_node order by groupid;
nodeid | groupid | nodename | nodeport | noderole
-------+---------+------------+----------+----------
1 | 0 | 172.19.0.7 | 5432 | primary
3 | 1 | 172.19.0.2 | 5432 | primary
2 | 2 | 172.19.0.9 | 5432 | primary
(3 rows)
As you may see, nodename for the primary in a group 2 was automatically changed by Patroni from 172.19.0.4 to 172.19.0.9.
Future plans & possible improvements
The article would not be complete without explaining what further work on Patroni & Citus integration is possible. And there are quite a few options:
- Read scaling: We could register worker standby nodes in pg_dist_node so they could be used for scaling read-only queries.
- Connection pooling: When communicating between nodes, Citus has an option to use connection pooling. To facilitate it the pg_dist_poolinfo should be automatically filled and kept up to date on failover/switchover.
- Multiple databases: Currently Patroni only supports clusters with a single Citus-enabled database, but there are users that have more than one.
Together, Patroni and Citus give distributed PostgreSQL users a good HA solution
Patroni opens a route to automated, fully-declarative, open source Postgres deployments of Citus distributed database clusters with high availability (HA)—on any imaginable platform. In our examples we have used docker and docker-compose, but the real production deployment doesn’t require using containers.
Even though Patroni 3.0 supports Citus all the way back to Citus version 10.0, we recommend using the latest versions of Citus and PostgreSQL 15 to fully benefit from transparent switchovers and/or restarts of worker nodes. From the Citus 11.2 Updates page, a.k.a. the release notes page, you can see that:
“The main thing that we improved [for HA in Citus 11.2], is that we now transparently reconnect when we detect that a cached connection to a worker got disconnected while we were not using it.”
To get started with Citus and Patroni there are some great docs:
For Kubernetes lovers we also have good news: please check Citus on Kubernetes in the Patroni repository. Please keep in mind that this is just an example and not meant for production usage. For the real production usage, we recommend waiting until Postgres Operators from Crunchy, Zalando, or OnGres start to support Citus.
