📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
Distributed transactions are one of the meanest, baddest problems in relational databases. With the release of Citus 7.1, distributed transactions are now available to all our users. In this article, we are going to describe how we built distributed transaction support into Citus by using PostgreSQL modules. But first, let’s give an overview of what a distributed transaction is.
(If this sounds familiar, that’s because we first announced distributed transactions as part of last week’s Citus Cloud 2 announcement. The Citus Cloud announcement centered on other new useful capabilities —such as our warp feature to streamline migrations from single-node Postgres deployments to Citus Cloud — but it seems worthwhile to dedicate an entire post to distributed transactions.)
Why are distributed transactions hard?
You do a BEGIN transaction, INSERT, and UPDATE. Once you run a SELECT, you should see your changes applied against the database. But others shouldn’t until you do a COMMIT. Or you ROLLBACK, and your changes should disappear.
These transactional semantics, also known as ACID properties, are already hard to provide on a single node. So how do you provide them in a distributed database, in the face of machine and network failures?
Distributed Atomic Transactions
Let’s start with a well known transaction example. We have two bank accounts that belong to Alice and Bob, and we’re looking to transfer money from Alice’s account to Bob’s. The wire transfer needs to happen atomically. That is, both accounts should be updated together or neither account should be updated at all.
In Citus, we’re also going to execute this transaction on a distributed database. The database has three participating nodes that have PostgreSQL and the Citus extension installed. One of these nodes is the coordinator node—the coordinator holds metadata about distributed tables and their shards. The cluster also has two worker nodes, where each worker node holds four shards. In Citus, each shard is one PostgreSQL table. Shards are also transparent to the application.
In this example, we have a distributed table named accounts that’s sharded on account_id. We’re now going to transfer $100 from Alice’s to Bob’s account in four steps.
In the first and second steps, the client starts a transaction and sends two commands to update Alice and Bob’s accounts. The Citus coordinator then starts a transaction across two worker nodes, and associates these two local transactions with a distributed transaction (more on why we do this later). The coordinator then pushes these two update commands to two worker nodes.
In the third and fourth steps, when the client issues a commit, the Citus coordinator initiates the 2PC protocol. First, the coordinator sends PREPARE TRANSACTION to both worker nodes. When the worker nodes vote to commit the transactions, the coordinator then sends COMMIT PREPARED. The workers then commit their local transactions, release their locks, and send acknowledgments to the coordinator. Once the coordinator receives all acks, it completes the distributed transaction.
The 2PC algorithm’s assumptions and behavior is widely discussed in distributed systems literature. You can read more about it in wikipedia.
Improving built-in 2PC
2PC has one disadvantage. If the coordinator node fails permanently, worker nodes may never resolve their transactions. In particular, after a worker node agrees to a PREPARE TRANSACTION, the transaction will block until the worker receives a commit or rollback.
To overcome this disadvantage, we made two improvements to 2PC in Citus. First, Citus Cloud and Enterprise deployments usually run in high availability mode. In this mode, both the coordinator and worker nodes have streaming replicas. When any of these nodes fails, their secondaries get promoted within seconds.
Second, when the coordinator sends PREPARE commands to worker nodes, it saves this information in distributed metadata tables. Later, the coordinator node checks this metadata table during crash recovery and at regular intervals. If any transactions on the worker nodes are in an incomplete state, the coordinator recovers them.
Consistency Algorithms in Distributed Systems
Consistency is a well established problem in distributed systems. In that context, consistency means that every read receives the most recent write or an error. There are three popular distributed consistency algorithms (each algorithm also has variants):
- Two-phase commit (2PC): All participating nodes need to be up
- Paxos: Achieves consensus with quorum
- Raft: Designed as an alternative to Paxos. Meant to be more understandable than Paxos
The primary difference between 2PC and Paxos is that 2PC needs all participating nodes to be available to make progress.
In Citus, we looked into the 2PC algorithm built into PostgreSQL. We also developed an experimental extension called pg_paxos. We decided to use 2PC for two reasons. First, 2PC has been used in production across thousands of Postgres deployments. Second, most Citus Cloud and Enterprise deployments use streaming replication behind the covers. When a node becomes unavailable, the node’s secondary usually gets promoted within a seconds. This way, Citus can have all participating nodes be available most of the time.
Distributed Deadlock Detection
Most articles on distributed transactions focus on the more visible problem around data consistency. They then discuss protocols such as 2PC or Raft. In practice, data consistency is only part of the problem. If you’re using a relational database, your application also benefits from another key feature: deadlock detection.
In PostgreSQL, when a transaction updates a row, the update grabs a lock for that row. If you have concurrent transactions that need to acquire the same set of locks, but in different orders, you run into a deadlock.
Deadlock Detection in PostgreSQL
Going back to our original wire transfer example, let’s say that Alice initiated a wire transfer to Bob, and Bob initiated a transfer to Alice around the same time. In this case, when you have session 1 and session 2 updating the same rows in different orders, you will run into a deadlock.
S1: BEGIN; // session 1 starts transaction block
S1: UPDATE accounts SET balance = balance - '100.00' WHERE id = 'Alice'; // S1 takes 'Alice' lock
S2: BEGIN; // session 2 starts transaction block
S2: UPDATE accounts SET balance = balance + '100.00' WHERE id = 'Bob'; // S2 takes 'Bob' lock
S1: UPDATE accounts SET balance = balance + '100.00' WHERE key = 'Bob'; // waits for 'Bob' lock held by S2
S2: UPDATE accounts SET balance = balance - '100.00' WHERE key = 'Alice'; // deadlocks on 'Alice' lock held by S1
In Postgres, if sessions are waiting on a lock for more than the deadlock_timeout (1s), the database will check whether those sessions are waiting for each other. In the Alice and Bob case, Postgres will for example abort session 2’s transaction to resolve the deadlock. Session 1 will then acquire the lock on Bob’s row and complete the transaction.
Distributed Deadlock Detection in Citus
Now, things are trickier when you’re running Alice and Bob’s wire transfers in a distributed database. In this case, let’s say that worker node 1 has a shard that holds Alice’s account. Worker 3 has another shard that holds Bob’s account.
You initiate a wire transfer (D1) to transfer money from Alice to Bob’s account. You concurrently initiate another transfer D2 that moves money from Bob to Alice’s account. D1 and D2 will then block on each other.
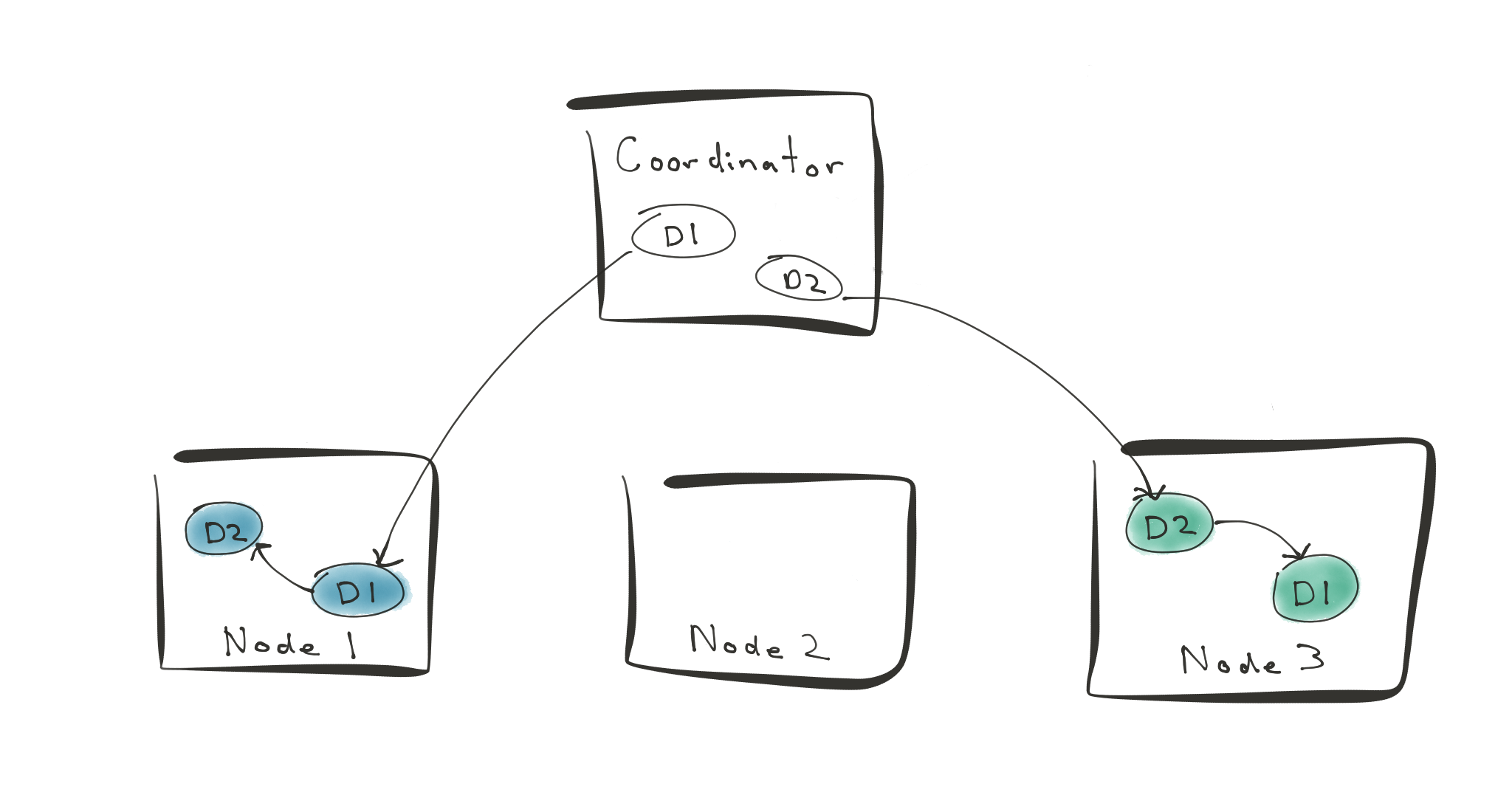
In this example, PostgreSQL runs deadlock detection on the coordinator, worker 1, and worker 3. None of the nodes involved in these distributed transactions see a deadlock. If you look at the whole picture however, there’s a deadlock. This is the situation we have to deal with to safely support distributed transactions.
To handle deadlocks that span across nodes, Citus adds a new distributed deadlock detector. This deadlock detector runs as a background worker process within the Postgres extension framework.
When a client sends a transaction to Citus, the coordinator sends the transaction to related worker nodes. Before sending the transaction however, the coordinator also calls the function SELECT assign_distributed_transaction_id(); This call ensures that the local transaction on the worker node is associated with the distributed transaction on the coordinator.
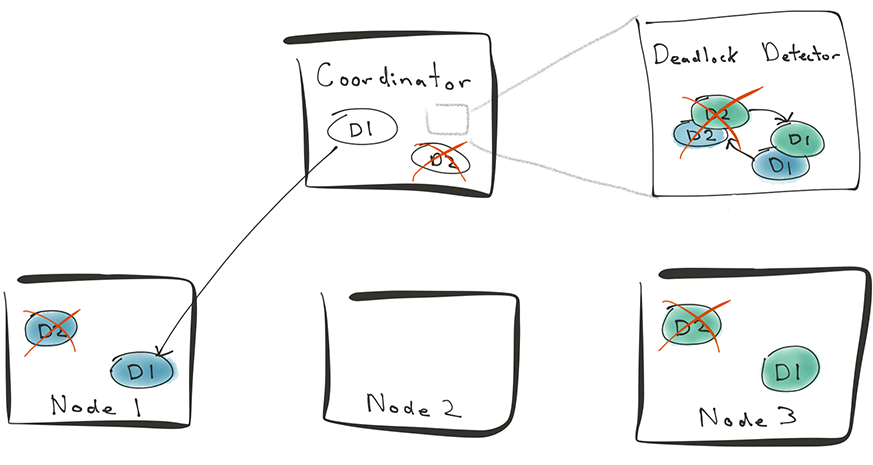
When D1 and D2 get blocked, the distributed deadlock detector gathers all lock tables from worker nodes and builds a distributed transaction graph. The deadlock detector then associates the local transactions with the distributed ones. Once it does that, the deadlock detector sees that the transactions on worker 1 and worker 3 are actually blocked on each other.
The deadlock detector can then cancel D2 on the coordinator. This will also abort D2’s transactions on worker 1 and worker 3. Then, D1 can acquire the lock on Bob’s row and complete the distributed transaction. This way, Citus can implement distributed transactions on a sharded database safely.
Why PostgreSQL provides a solid foundation for a distributed database?
Distributed transactions is one of the hardest problems in relational databases. When solving a complex problem, you can either build a solution from scratch, or extend an existing technology.
At Citus, we chose to make PostgreSQL a rock-solid distributed database. When implementing distributed transactions, Citus leverages the following modules:
- Stable storage on each node with a write-ahead log. The write-ahead log is crash safe. (requirement for 2PC)
- 2PC protocol
- Streaming replication for fast node recovery
- PostgreSQL local process and lock graphs
- Cancellation and rollback logic for all statements
This way, Citus uses Postgres components that are hardened over decades. So we can focus on building a relational database that seamlessly scales.
The good news for our customers is that they don’t even need to think about these challenges. We did all the hard work - so you can focus on your application and not worry about scaling your database.
