📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
Since Citus is a distributed database, we often hear questions about distributed transactions. Specifically, people ask us about transactions that modify data living on different machines.
So we started to work on distributed transactions. We then identified distributed deadlock detection as the building block to enable distributed transactions in Citus.
First some background: At Citus we focus on scaling out Postgres. We want to make Postgres performance & Postgres scale something you never have to worry about. We even have a cloud offering, a fully-managed database as a service, to make Citus even more worry-free. We carry the pager so you don’t have to and all that. And because we've built Citus using the PostgreSQL extension APIs, Citus stays in sync with all the latest Postgres innovations as they are released (aka we are not a fork.) Yes, we're excited for Postgres 10 like all the rest of you :)
Back to distributed deadlocks: As we began working on distributed deadlock detection, we realized that we needed to clarify certain concepts. So we created a simple FAQ for the Citus development team. And we found ourselves referring back to the FAQ over and over again. So we decided to share it here on our blog, in the hopes you find it useful.
What are locks and deadlocks?
Locks are a way of preventing multiple processes (read: client sessions) from accessing or modifying the same data at the same time. If a process tries to obtain a lock when that lock is already held by another process, it needs to wait until the first process releases the lock.
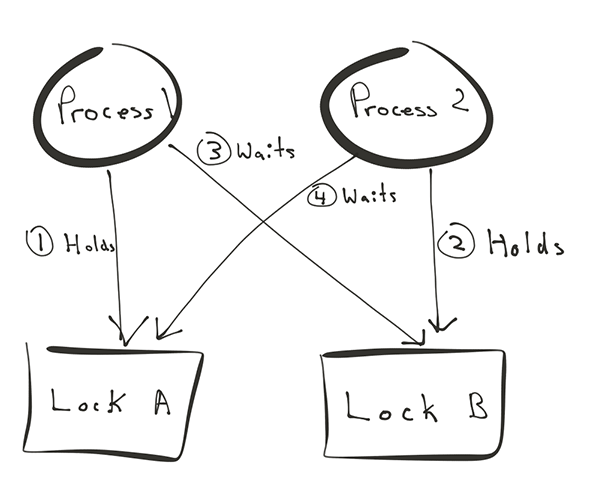
Waiting becomes problematic when processes obtain locks in a different order. Process 1 may by waiting for a lock held by process 2, while process 2 may be waiting for a lock held by process 1, or a chain of processes that ultimately wait on process 1. This is a deadlock.
When does PostgreSQL acquire locks?
Backing up further, PostgreSQL has various locks. In the context of deadlocks, the ones we're most concerned with are row-level locks that are acquired by statements prior to modifying a row and held until the end of the transaction. DELETE, UPDATE, INSERT..ON CONFLICT take locks on the rows that they modify and also on rows in other tables referenced by a foreign key. INSERT and COPY also acquire a lock when there is a unique constraint, to prevent concurrent writes with the same value.
So if a session does:
BEGIN;
UPDATE table SET value = 5 WHERE key = 'hello';
This session now holds row-level locks on all rows where key = 'hello'. If another session attempts to update rows where key = 'hello' at the same time, that command will block until session 1 sends commit or abort.
When do deadlocks occur in PostgreSQL?
In the following scenario, sessions 1 and 2 obtain locks in opposite order after sending BEGIN.
1: UPDATE table SET value = 1 WHERE key = 'hello'; A takes 'hello' lock
2: UPDATE table SET value = 2 WHERE key = 'world'; B takes 'world' lock
1: UPDATE table SET value = 1 WHERE key = 'world'; wait for 'hello' lock held by 2
2: UPDATE table SET value = 2 WHERE key = 'hello'; wait for 'world' lock held by 1
This situation on its own can’t be resolved. However, if sessions are waiting on a lock for a while, Postgres will check whether processes are actually waiting for each other. If that is the case, Postgres will forcibly abort transactions until the deadlock is gone.
Note that if both sessions followed the same order (first hello, then world), the deadlock would not have occurred since whichever session gets the 'hello' lock goes first. Modifications occurring in different order is a key characteristic of deadlocks.
What is a distributed deadlock (in Citus)?
In Citus, the scenario above becomes a bit more complicated if the rows are in different shards on different workers.
In that case, Citus worker A sees:
1: UPDATE table_123 SET value = 5 WHERE key = 'hello';
2: UPDATE table_123 SET value = 6 WHERE key = 'hello'; waits for 'hello' lock held by 1
Citus worker B sees:
2: UPDATE table_234 SET value = 6 WHERE key = 'world';
1: UPDATE table_234 SET value = 5 WHERE key = 'world'; waits for 'world' lock held by 2
Distributed Deadlock
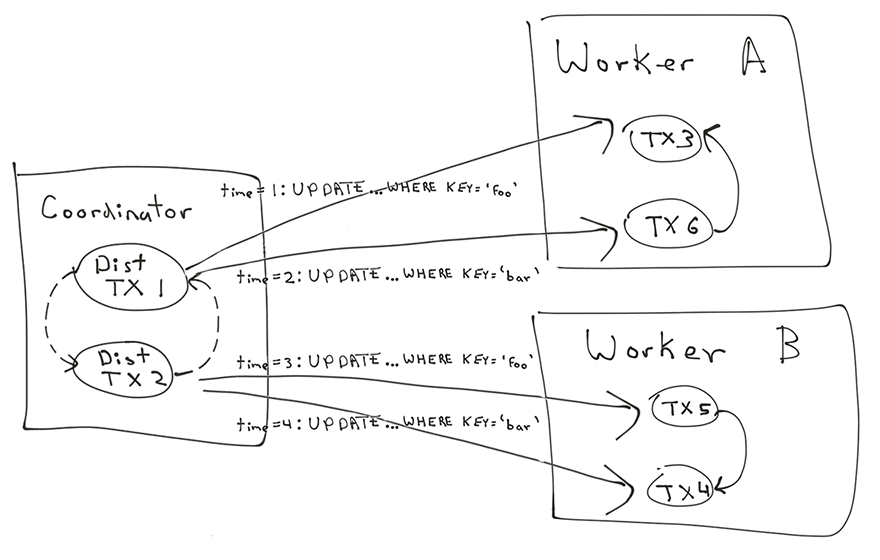
Neither PostgreSQL database on worker A or worker B sees a problem here, just one session waiting for the other one to finish. From the outside, we can see that neither session can finish. In fact, this situation will last until the client disconnects or the server restarts. This situation where two sessions on different worker nodes are both waiting for each other is called a distributed deadlock.
Why are (distributed) deadlocks really bad?
The rows held by the two sessions that are in a deadlock can no longer be modified while the sessions lasts, but that's far from the worst part. Other sessions may take locks and then get blocked on session 1 or 2 and those locks will prevent yet more sessions from completing and might also make them more likely to form other deadlocks. This can escalate to a full system outage.
How can a distributed database detect and stop distributed deadlocks?
To detect a distributed deadlock, Citus needs to continuously monitor all nodes for processes that are waiting for locks for a non-negligible amount of time (e.g. 1 second). When this occurs, we collect the lock tables from all nodes and construct a directed graph of the processes that are waiting for each other across all the nodes. If there is a cycle in this graph, then there is a distributed deadlock. To end the deadlock, we need to proactively kill processes or cancel transactions until the cycle is gone.
How can a distributed database prevent distributed deadlocks?
Deadlock detection and prevention are related but different topics. Deadlock prevention is an optimisation problem.
The simplest solution is to only allow one multi-shard transaction at a time. At Citus, we find we can do better by using whatever information we have available, most notably the query and the current time.
Predicate Locks A common technique for deadlock prevention is predicate locks. When we see two concurrent transactions performing an UPDATE .. WHERE key = 'hello' then we know that they might modify the same rows, while a concurrent UPDATE .. WHERE key = 'world' won't. We could therefore take a lock based on filter conditions (a predicate lock) on the coordinator. This would allow parallel, multi-shard UPDATEs to run concurrently without risk of deadlock, provided they filter by the same column with a different value.
The predicate locking technique can also detect deadlocks caused by multi-statement transactions across multiple shards if there is one coordinator node. Before a distributed deadlock can form across workers, the predicate locks would have already formed a deadlock on the coordinator, which is detected by PostgreSQL.
Spanner/F1 uses predicate locks to prevent deadlocks within a shard. Spanner could do this because it disallows interactive transaction blocks, meaning it knows all the commands upfront and can take the necessary predicate locks in advance. This is a useful model, but it doesn’t fit well into the PostgreSQL protocol that allows interactive transaction blocks.
Wait-Die or Wound-Wait Another prevention technique is to assign priorities (transaction IDs) to distributed transactions in the form of timestamps. We then try to ensure that a transaction A with a low transaction ID does not get blocked by a transaction B with a higher transaction ID (priority inversion). Whenever this happens, we should either cancel/restart A (wait-die) and try again later, or cancel/restart B (wound-wait) in order to let A through. The latter is generally more efficient.
In PostgreSQL, savepoints might allow us to restart part of a transaction. What's nice about the wound-wait technique is that it works even when there are multiple coordinators. As long as clocks are reasonably well-synchronised, priority inversion is not that common. In practice, since a transaction that starts earlier typically acquires locks earlier, most transactions don't experience any cancellation due to priority inversion. The ones that do are the ones that are likely to form a deadlock. Spanner/F1 also uses wound-wait for preventing multi-shard deadlocks.
You can read more on concurrency control in distributed databases here:
https://people.eecs.berkeley.edu/~kubitron/cs262a/handouts/papers/concurrency-distributed-databases.pdf
At Citus we love tackling complex distributed systems problems
Distributed transactions are a complex topic. Most articles on this topic focus on the more visible problem around data consistency. These articles then discuss protocols such as 2PC, Paxos, or Raft.
In practice, data consistency is only one side of the coin. If you’re using a relational database, your application benefits from another key feature: deadlock detection. Hence our work in distributed deadlock detection—and this FAQ.
We love tackling these types of complex distributed systems problems. Not only are the engineering challenges fun—but it is satisfying when our customers tells us that they no longer have to worry about scale and performance because of the work we’ve done scaling out Postgres. And if you’ve been reading our blog for a while, you know we like sharing our learnings, too. Hopefully you’ve found this useful! Let us know on twitter your thoughts and feedback.
