📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
"Thirty years ago, my older brother was trying to get a report on birds written that he'd had three months to write. It was due the next day.
We were out at our family cabin in Bolinas, and he was at the kitchen table close to tears, surrounded by binder paper and pencils and unopened books on birds, immobilized by the hugeness of the task ahead. Then my father sat down beside him, put his arm around my brother's shoulder, and said, 'Bird by bird, buddy. Just take it bird by bird.'"
— Bird by Bird: Some Instructions on Writing and Life, by Anne LaMott
When we started working on Citus, our vision was to combine the power of relational databases with the elastic scale of NoSQL. To do this, we took a different approach. Instead of building a new database from scratch, we leveraged PostgreSQL’s new extension APIs. This way, Citus would make Postgres a distributed database and integrate with the rich ecosystem of tools you already use.
When PostgreSQL is involved, executing on this vision isn’t a simple task. The PostgreSQL manual offers 3,558 pages of features built over two decades. The tools built around Postgres use and combine these features in unimaginable ways.
After our Citus open source announcement, we talked to many of you about scaling out your relational database. In every conversation, we’d hear about different Postgres features that needed to scale out of the box. We’d take notes from our meeting and add these features into an internal document. The list would keep getting longer, and longer, and longer.
Like the child writing a report on birds, the task ahead felt insurmountable. So how do you take a solid relational database and make sure that all those complex features scale? You take it bird by bird. We broke down the problem of scaling into five hundred smaller ones and started implementing these features one by one.
Citus 7: Transactions, Framework Integration, and Postgres 10
Citus 7 marks a major milestone in our journey to scale out Postgres. Over the past year, many SaaS (B2B) businesses approached us to get help scaling out their databases, in order to get the performance they needed. Often, they were already using Postgres. And what they really wanted was to focus on their application—not their database infrastructure.
Three items are important in the SaaS (B2B) database context. First, a relational database should support ACID transactions on a single machine, and also across machines. The primary challenge related to multi-machine transactions is database deadlocks. When you run concurrent and distributed transactions in a relational database, they may result in a deadlock. How do you resolve those deadlocks in a distributed environment?
The second item: application and framework integration. Postgres enjoys rich framework support from Rails, Django, and many other frameworks. Pointing your favorite framework to Citus and having everything work was key. With 7, Rails and Django frameworks drop-in without you having to think about how distributed systems work.
Finally, a distributed database is only as good as the underlying database it builds on. Postgres 10 brings features around declarative partitioning, parallelism, and performance improvements. We’re so excited by these features that we’re rolling out Citus 7 with support for the upcoming Postgres 10 release.
Distributed Transactions and Distributed Deadlock Detection
Distributed transactions are a complex topic. Most articles on this topic focus on the more visible problem around data consistency and availability. These articles then discuss protocols such as 2PC, Paxos, or Raft.
In practice, data consistency is only one side of the coin. If you’re using a transactional database, your application benefits from another key feature: deadlock detection.
A deadlock happens when you have concurrent transactions that need to acquire the same set of locks, in different orders. For example, you have session 1 and session 2 modifying your database. The following scenario leads to a deadlock in PostgreSQL.
session #1: BEGIN; // session 1 starts transaction block
session #1: UPDATE table SET value = 5 WHERE key = ‘hello’; // takes ‘hello’ lock
session #2: BEGIN; // session 2 starts transaction block
session #2: UPDATE table SET value = 6 WHERE key = ‘world’; // takes ‘world’ lock
session #1: UPDATE table SET value = 6 WHERE key = ‘world’; // waits for ‘world’ lock held by #2
session #2: UPDATE table SET value = 5 WHERE key = ‘hello’; // deadlocks on ‘hello’ lock held by #1
In Postgres, if sessions are waiting on a lock for a predetermined time, the database will check whether those sessions are waiting for each other. If they are, Postgres will forcibly abort transactions until the deadlock is resolved.
In Citus, those deadlocks were harder to resolve because of their distributed nature. If you take the example transactions above, they will span across shards that live on different machines. The following diagram shows those two transactions spanning across worker A and worker B in a Citus cluster.
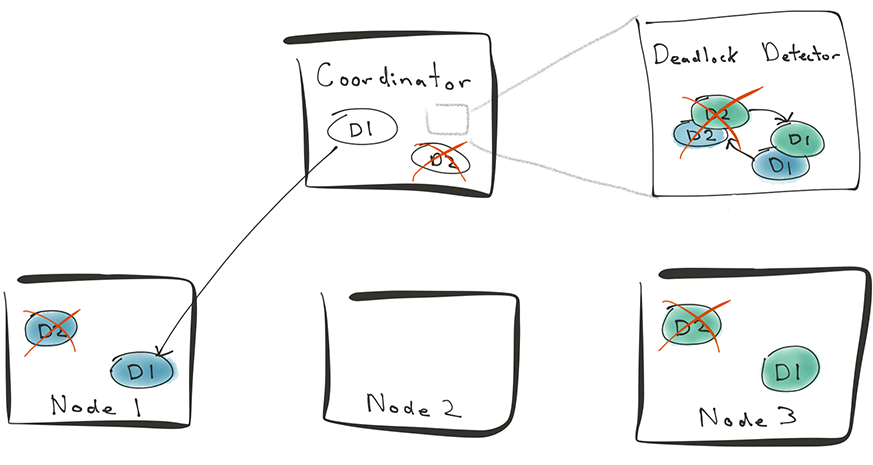
Neither PostgreSQL database on worker A or worker B sees a problem here, just one session waiting for the other one to finish. This scenario was the reason you needed to use workarounds when issuing transactions that spanned across machines [1].
Citus 7 comes with distributed deadlock detection, a critical component for distributed transactions. You can now insert data into multiple shards / machines within a transaction. Further, you can use issue transactions that span across distributed and reference tables. Both of these features make integrating your transactional application to Citus much easier.
Savepoint Support
An important feature related to transactions is savepoints. Savepoints allow you to create "bookmarks" within a transaction so that you don't have to rollback the entire transaction. Your application can do a partial rollback, to the bookmark you created earlier.
Savepoints are a common pattern in certain frameworks (e.g. ActiveRecord). In particular, unit testing frameworks use savepoints to model nested transactions. With Citus 7, you can now issue complex transactions that span across distributed tables and reference tables.
BEGIN;
SAVEPOINT active_record_1;
SELECT nextval('teams_id_seq'::regclass);
INSERT INTO "teams" ("name", "created_at", "updated_at", "id") VALUES ('Lukas, Fittl', '2017-04-13 07:25:48.591370', '2017-04-13 07:25:48.591370', 1) RETURNING "id";
SELECT DISTINCT "groups".* FROM "groups" INNER JOIN "steps" ON "steps"."step_group_id" = "groups"."id" AND "steps"."deleted" = 'f' AND "steps"."team_id" = 1 WHERE "groups"."team_id" = 1 AND "groups"."deleted" = 'f' AND "groups"."team_id" = 1 AND ("groups"."step_config_id" IS NOT NULL) ORDER BY "groups"."day" ASC, "groups"."order" ASC, "groups"."id" ASC;
RELEASE SAVEPOINT active_record_1;
SAVEPOINT active_record_1;
SELECT "users".* FROM "users" WHERE "users"."token" = '90xxf54d04db7' LIMIT 1;
INSERT INTO "users" ("first_name", "last_name", "email", "token", "created_at", "updated_at", "plugged_token") VALUES ('Sai', 'Srirampur', 'info@citusdata.com', 'aaa-6fbd4dd6be71', '2017-04-13 07:25:48.591370', '2017-04-13 07:25:48.591370', '5555aaaaddff566f54d04db7') RETURNING "id";
ROLLBACK TO SAVEPOINT active_record_1;
ROLLBACK;
Multi-Value Insert Statements
You not only want to issue transactional inserts to multiple shards. You also want to batch your inserts into one statement. This way, you can keep your data ingest pipeline as-is and also enjoy the performance benefits of issuing many inserts in one statement. Citus 7 supports multi-value inserts for better application integration.
INSERT INTO limit_orders VALUES (12037, ‘GOOG’, 5634, ‘2001-04-16 03:37:28’, ‘buy’, 0.50,
12038, ‘GOOG’, 5634, ‘2001-04-16 03:37:28’, ‘buy’, 2.50,
12039, ‘GOOG’, 5634, ‘2001-04-16 03:37:28’, ‘buy’, 1.50);
Rails/AR and Django Integration: Silver Bullet Edition
When it comes to integrating a sharded database with your ORM, there are no silver bullets. Just lots of lead bullets. Over the past year, many of you asked for features to make ORM integration easier. These features related to migrations, integration with your test suites, or making frameworks (such as Database Cleaner) fast.
Some of those features had easy workarounds. Some others, such as the UPDATE … FROM query below, were more important when scaling SaaS (B2B) applications.
UPDATE foobar
SET
distinct_viewers = metrics.viewers
FROM
(SELECT contactable_id foobar_id,
count(DISTINCT (CASE WHEN event_type='View' then visitor_token end)) as viewers
FROM events
WHERE account_id=12 group by contactable_id) metrics
WHERE
id=metrics.foobar_id AND
account_id=12;
Citus 7 implements remaining features around Rails/AR and Django integration. These include UPDATE .. FROM queries that touch a single machine, IN (...) queries with proper shard pruning, removing pg_dump warnings, and handling all types of 1=0 conditions. With these features, we completed all eleven features related to ORM integration.
All the things about Citus 7, including release notes
Citus 7 adds even more features you’ve been asking for. In any other release, many of these features would have made their own headlines. In this release, we’re grouping them together. This isn’t because the feature below are any less important, but because of the long list of improvements in Citus 7.
- Citus 7 documents repeatable benchmark steps for INSERT and UPDATE performance. We found that a small Citus Cloud cluster can ingest 1B inserts per day.
- This release also improves INSERT and UPDATE performance by 10-30%.
- Citus 7 expands our SQL coverage for interactive analytical queries. If you have complex analytical queries, you can now include reference tables within those queries.
- You have been also asking for INSERT INTO … SELECT from local tables into distributed tables. Citus 7 now supports this feature and makes the boundary between local and distributed tables even thinner.
You can find the complete set of changes in GitHub.
PostgreSQL 10 Support
Citus 7 adds key features to its distributed functionality.
That said, a distributed database is only as good as the database it builds on: Postgres. Citus is unique in that it uses the PostgreSQL extension APIs. This allows Citus 7 to make Postgres 10 features available to our customers.
The full set of Postgres 10 features are available in the release notes and they deserve their own blog post. Still, we want to highlight three features that make both Postgres and Citus more powerful at scale:
- Parallel index scans and merge joins: If you have a multi-tenant application, you can now shard on the tenant id and have your analytical queries run in parallel as well.
- Declarative partitioning: With these changes, you can shard your tables on their customer or user id, and then partition those tables by time
- Query performance: Postgres 10 & 11 make notable improvements to analytical query performance. In Postgres 10, TPC-H query 1 runs 50% faster on a single core. Postgres 11 will take a giant step in analytical query performance by adding Just in Time Compilation (JIT). These JIT changes will improve analytical query performance by another 2-3x.
With Citus, Never Worry About Scaling Your Database Again
When we started working on Citus, our vision was to combine the power of relational databases with the elastic scale of NoSQL. This way, you’d never have to worry about scaling your database again.
Citus 7 sets a major milestone in that journey. After our open source announcement, we were humbled by your reaction and the ideas many of you had for making our Citus database even more useful. The task ahead looked daunting. So we broke down the task into hundreds of smaller ones, and started implementing them one of one. The result of all our efforts: Citus 7 and a whole lot of happy customers.
Today, the task ahead of us still puts a smile on our face. Citus 7 makes key improvements around distributed transaction support and framework integration. We’re also excited by the upcoming (and awesome) Postgres 10.0 release and plan to support Postgres 10 out of the box (because, as you know, we’re not a fork, rather, Citus is an extension to Postgres. It makes it easy to stay current.)
If you’re interested in trying Citus, download Citus today or try Citus in the cloud. (Update in October 2022: The Citus managed service is available as Azure Cosmos DB for PostgreSQL. Learn more.
