📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
AWS is the leader when it comes to the cloud, and for good reason. AWS is well ahead in the quality and breadth of services they offer.
However, when a service is running at the scale of AWS, it is natural to expect some failures to occur. According to AWS EBS availability is designed for 99.999%.
The annual failure rate (AFR) is 0.1% - 0.2%, where failure means a complete or partial failure. For example, if you had 1,000 EBS discs, you should expect 1 or 2 to have a failure per year. In our experience, partial failure is significantly more common than a complete loss. Even so, a partial loss can take a lot of time to resolve and can still be debilitating to a business.
Over the years, there have been some AWS failures that made news headlines due to havoc caused for both companies and their users. These incidents put a spotlight on AWS’ imperfections.
In 2011, a major AWS failure took down hundreds of sites including Quora and Reddit. From this outage, Netflix learnt to always be prepared by intentionally simulating failures with a service called Chaos Monkey. In 2013, one of the biggest failures happened when the AWS U.S. East data center went down, affecting Netflix, Airbnb, Instagram and Amazon.com itself. Just weeks ago on February 28th, AWS S3 storage had a major outage due to high error rates, again in the U.S. East data center. Prominent companies including Atlassian, Slack and Expedia were hit.
Introduction to High Availability and Disaster Recovery
In the real world, insurance is used to manage risk when a natural disaster such as a hurricane or flood strikes. In the database world, there are two critical methods of insurance. High Availability (HA) replicates the latest database version virtually instantly. Disaster Recovery (DR) offers continuous protection by saving every database change, allowing database restoration to any point in time.
In what follows, we’ll dig deeper as to what disaster recovery and high availability are, as well as how we’ve implemented them for Citus Cloud.
What is High Availability and Disaster Recovery?
High availability and disaster recovery are both forms of data backups that are mutually exclusive and inter-related. The difference between them, is that HA has a secondary reader database replica (often referred to as stand-by or follower) ready to take over at any moment, but DR just writes to cold storage (in the case of Amazon that’s S3) and has latency in the time for the main database to recover data.
Overview of High Availability
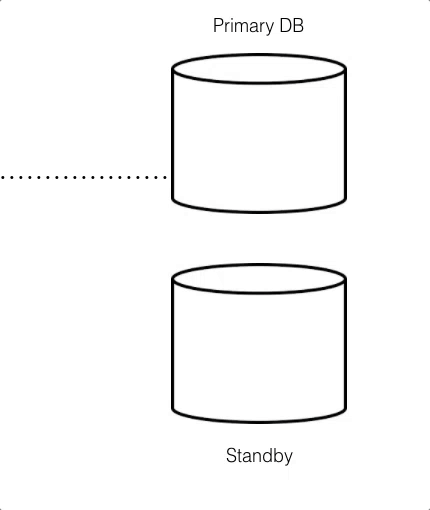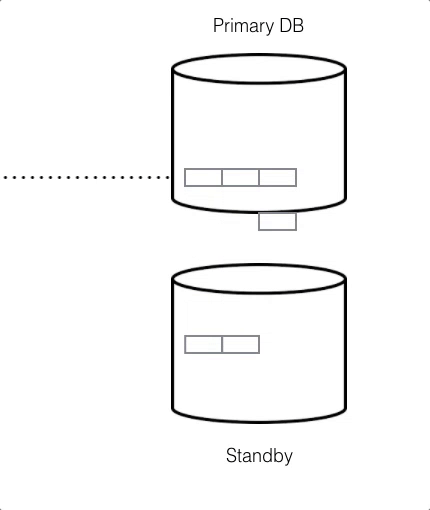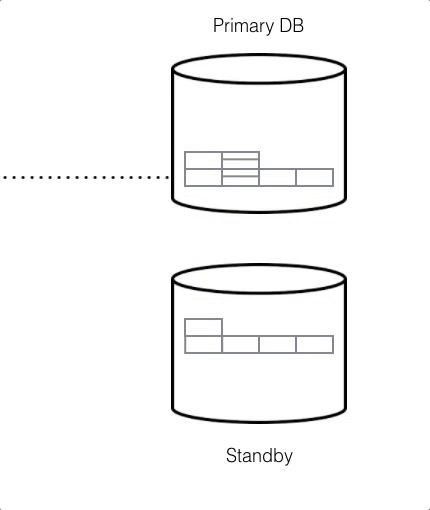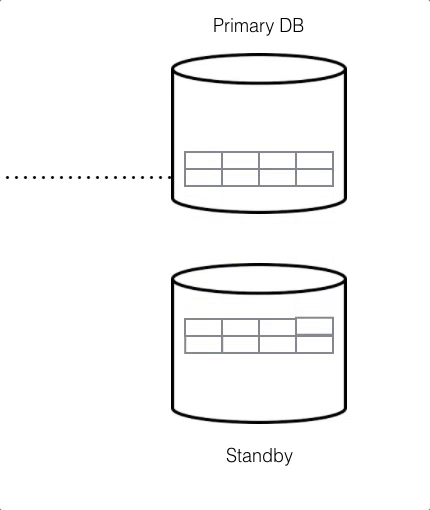
For HA, any data that is written to a primary database called the Writer is instantly replicated onto a secondary database called the Reader in real-time, through a stream called a WAL or Write-Ahead-Log.
To ensure HA is functioning properly, Citus Cloud runs health checks every 30 seconds. If the primary fails and data can’t be accessed after six consecutive attempts, a failover is initiated. This means the primary node will be replaced by the standby node and a new standby will be created.
Overview of Disaster Recovery
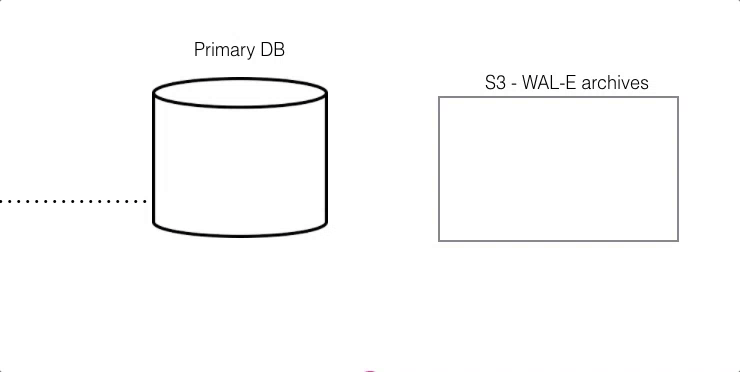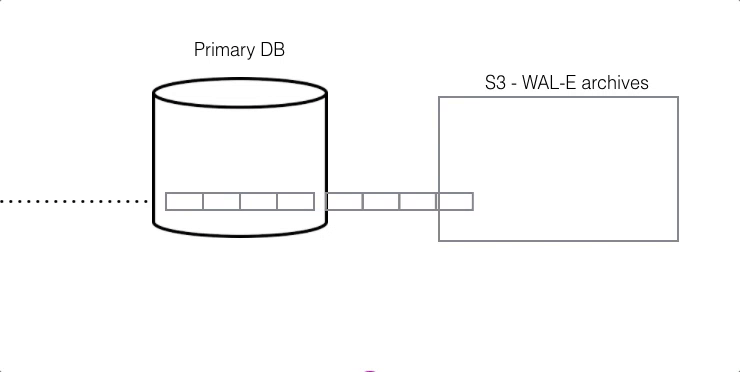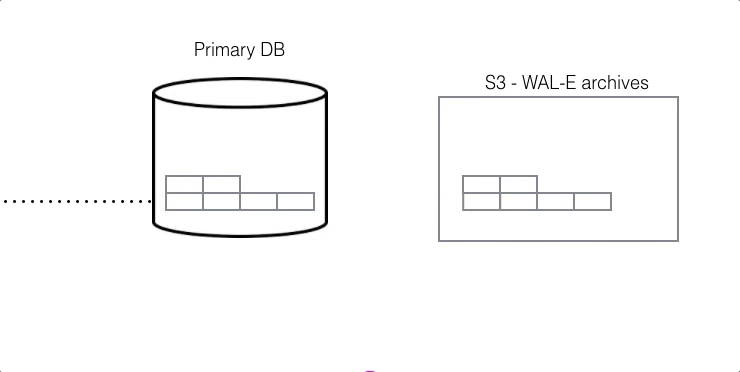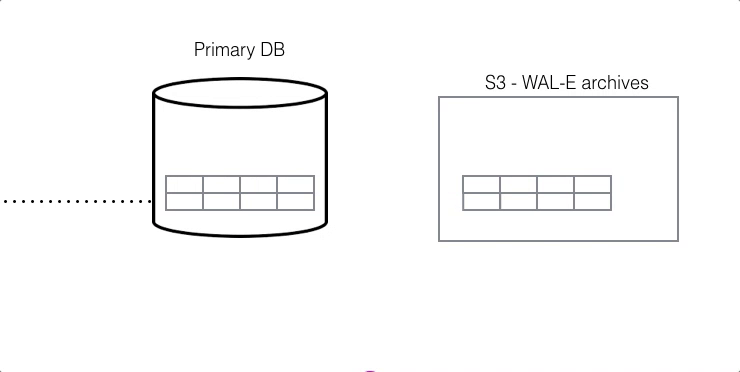
For DR, read-only data is replayed from colder storage. On AWS this is from S3, and for Postgres this is downloaded in 16 MB pieces. On Citus Cloud this happens via WAL-E, using precisely the same procedure as creating a new standby for HA. WAL-E is an open source tool initially developed by our team, for archiving PostgreSQL WAL (Write Ahead Log) files quickly, continuously and with a low operational burden.
This means we can restore your database by fetching the base backup and replaying all of the WAL files on a fresh install in the event of hardware failure, data corruption or other failure modes
On Citus Cloud prior to kicking off the DR recovery process, the AWS EC2 instance is automatically restarted. This process usually takes 7±2 minutes. If it restarts without any issues, the setup remains the same. If the EC2 instance fails to restart, a new instance is created. This happens at a rate of at least 30MB/second, so 512GB of data would take around 5 hours.
How High Availability and Disaster Recovery fit together
While some may be familiar many are not acutely aware of the relationship between HA and DR.
Although it’s technically possible to have one without the other, they are unified in that the HA streaming replication and DR archiving transmit the same bytes.
For HA the primary “writer” database replicates data through streaming replication to the secondary “reader” database. For DR, the same data is read from S3. In both cases, the “reader” database downloads the WAL and applies it incrementally.
Since DR and HA gets regularly used for upgrades and side-grades, the DR system is maintained with care. We ourselves rely on it for releasing new production features.
Disaster Recovery takes a little extra work but gives greater reliability
You might think that if HA provides virtually instant backup reliability, so ‘Why bother with DR?’ There are some compelling reasons to use DR in conjunction with HA including cost, reliability and control.
From a cost efficiency perspective, since HA based on EBS and EC2 is a mirrored database, you have to pay for every layer of redundancy added. However, DR archives in S3 are often 10-30% of the monthly cost of a database instance. And with Citus Cloud the S3 cost is already covered for you in the standard price of your cluster.
From reliability perspective, S3 has proven to be up to a thousand times more reliable than EBS and EC2, though a more reasonable range is ten to a hundred times. S3 archives also have the advantage of immediate restoration, even while teams try to figure out what’s going on. Conversely, sometimes EBS volume availability can be down for hours with uncertainty it will completely restore.
From a control perspective, using DR means a standby database can be created while reducing the impact on the primary database. It also has the capability of being able to recover a database from a previous version.
Trade-offs between latency and reliability
There is a long history of trade-offs between latency and reliability, dating back to when the gold standard for backups were on spools of tape.
Writing data to and then reading data from S3 offers latencies that are 100 to 1,000 times longer than streaming bytes between two computers as seen in streaming replication. However, S3's availability and durability are both in excess of ten times better than an EBS volume.
On the other hand, the throughput of S3 is excellent: with parallelism, and without downstream bottlenecks, one can achieve multi-gigabit throughput in backup and WAL reading and writing.
How High Availability and Disaster Recovery is used for crash recovery
When many customers entrust your company with their data, it is your duty to keep it safe under all circumstances. So when the most severe database crashes strike, you need to be ready to recover.
Our team is battle-hardened from years of experience as the original Heroku Postgres team, managing over 1.5 million databases. Running at that scale with constant risks of failure, meant that it was important to automate recovery processes.
Such crashes are a nightmare. But crash recovery is a way to make sure you sleep well at night by making sure none of your or your customers data is lost and your downtime is minimal.
How High Availability and Disaster Recovery is used for upgrades and side-grades
Here at Citus, our customers use the same HA and DR plumbing that we rely on when we upgrade hardware or sidegrade Citus versions.
A common example of this is when we run upgrades. In these cases we create a new “reader” database which will get caught up to the “writer” then we’ll pause writes to the “writer”, run the necessary upgrade on the “reader” which could be a Citus version upgrade or even a Postgres major version upgrade. Once that is completed we then conduct the same failover process as we do during HA to turn the “reader” into the “writer”.
In conclusion
We’ve covered a lot on the topic of HA and DR. Yet there is even more we could unpack. In the future, we’ll look deeper into these topics and others around how we manage and operate databases.
If you are unfamiliar with Citus Cloud, Citus Cloud is a managed service delivered on top of AWS that allows you to scale out your storage, memory and compute–horizontally scaling your database. If you’re starting to outgrow single node Postgres and need help scaling it out, feel free to contact us if you have any questions.
