📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
Managing time series data at scale can be a challenge. PostgreSQL offers many powerful data processing features such as indexes, COPY and SQL—but the high data volumes and ever-growing nature of time series data can cause your database to slow down over time.
Fortunately, Postgres has a built-in solution to this problem: Partitioning tables by time range.
Partitioning with the Postgres declarative partitioning feature can help you speed up query and ingest times for your time series workloads. Range partitioning lets you create a table and break it up into smaller partitions, based on ranges (typically time ranges). Query performance improves since each query only has to deal with much smaller chunks. Though, you’ll still be limited by the memory, CPU, and storage resources of your Postgres server.
The good news is you can scale out your partitioned Postgres tables to handle enormous amounts of data by distributing the partitions across a cluster. How? By using the Citus extension to Postgres. In other words, with Citus you can create distributed time-partitioned tables. To save disk space on your nodes, you can also compress your partitions—without giving up indexes on them. Even better: the latest Citus 10.2 open-source release makes it a lot easier to manage your partitions in PostgreSQL.
This post is your “how-to” guide to using Postgres with Citus and pg_cron for time series data—effectively transforming PostgreSQL into a distributed time series database. By using Postgres and Citus together, your application will be more performant at handling the ever-coming massive amounts of time series data—making your life easier.
Time series database capabilities explained in this post
- Partitioning: how to use Postgres native partitioning to split large timeseries tables into smaller time partitions
- Easy Partition Management: how to use new functions in Citus to simplify management of partitions
- Compression: how to use Citus Columnar to compress older partitions, save on storage, and improve query performance
- Automation: how to use the
pg_cronextension to schedule and automate partition management - Sharding: how to shard Postgres partitions on single-node Citus
- Distributing across nodes: how to distribute sharded partitions across nodes of a Citus database cluster, for high performance and scale
How to use Postgres’ built-in partitioning for time series data
Postgres’ built-in partitioning is super useful for managing time series data.
By partitioning your Postgres table on a time column by range (thereby creating a time-partitioned table), you can have a table with much smaller partition tables and much smaller indexes on those partitions—instead of a single huge table.
- Smaller tables and smaller indexes usually mean faster query responses.
- Having partitions for different time spans makes it more efficient to drop/delete/expire old data.
To partition your Postgres tables, you first need to create a partitioned table. Partitioned tables are virtual tables and have no storage of their own. You must create partitions to store a subset of the data as defined by its partition bounds, using the PARTITION BY RANGE syntax. Once you ingest data into the partitioned table, Postgres will store the data in the appropriate partition, based on the partitioning key you defined.
-- create a parent table partitioned by range
CREATE TABLE time_series_events (event_time timestamp, event int, user_id int)
PARTITION BY RANGE (event_time);
-- create partitions for that partitioned table
CREATE TABLE time_series_events_p2021_10_10 PARTITION OF time_series_events FOR VALUES FROM ('2021-10-10 00:00:00') TO ('2021-10-11 00:00:00');
CREATE TABLE time_series_events_p2021_10_11 PARTITION OF time_series_events FOR VALUES FROM ('2021-10-11 00:00:00') TO ('2021-10-12 00:00:00');
CREATE TABLE time_series_events_p2021_10_12 PARTITION OF time_series_events FOR VALUES FROM ('2021-10-12 00:00:00') TO ('2021-10-13 00:00:00');
-- insert rows into a partitioned table
INSERT INTO time_series_events VALUES('2021-10-10 12:00:00', 1, 2);
INSERT INTO time_series_events VALUES('2021-10-11 12:00:00', 1, 2);
INSERT INTO time_series_events VALUES('2021-10-12 12:00:00', 1, 2);
If you don’t need a partition anymore, you can manually drop it like dropping a normal Postgres table.
-- drop partitions
DROP TABLE time_series_events_p2021_10_10;
DROP TABLE time_series_events_p2021_10_11;
DROP TABLE time_series_events_p2021_10_12;
By using Postgres’ built-in partitioning, you can utilize resources of the node you are running Postgres on more wisely, but you'll need to spend time to manage those partitions by yourself. Unless you take advantage of the new Citus UDFs that simplify Postgres partition management, read on…
How to use new Citus functions to simplify partition management
Citus 10.2 adds two new user-defined functions (UDFs) to simplify how you can manage your Postgres time partitions: create_time_partitions and drop_old_time_partitions. Using these 2 new Citus UDFs, you no longer need to create or drop time partitions manually.
Both new Citus UDFs can be used with both regular Postgres tables and distributed Citus tables.
create_time_partitions(table_name regclass, partition_interval interval, end_at timestamp with time zone, start_from timestamp with time zone DEFAULT now()): For the given table and interval, create as many partitions as necessary for the given time range.drop_old_time_partitions(table_name regclass, older_than timestamp with time zone): For the given table, drop all the partitions that are older than the given timestamp
-- create partitions per day from 2021-10-10 to 2021-10-30
SELECT create_time_partitions(table_name:= 'time_series_events',
partition_interval:= '1 day',
end_at:= '2021-10-30',
start_from:= '2021-10-10');
You can use the Citus time_partitions view to get details of time-partitioned tables on your cluster.
-- check the details of partitions from time_partitions view
SELECT partition, from_value, to_value, access_method FROM time_partitions;
partition | from_value | to_value | access_method
--------------------------------+---------------------+---------------------+---------------
time_series_events_p2021_10_10 | 2021-10-10 00:00:00 | 2021-10-11 00:00:00 | heap
time_series_events_p2021_10_11 | 2021-10-11 00:00:00 | 2021-10-12 00:00:00 | heap
time_series_events_p2021_10_12 | 2021-10-12 00:00:00 | 2021-10-13 00:00:00 | heap
time_series_events_p2021_10_13 | 2021-10-13 00:00:00 | 2021-10-14 00:00:00 | heap
time_series_events_p2021_10_14 | 2021-10-14 00:00:00 | 2021-10-15 00:00:00 | heap
time_series_events_p2021_10_15 | 2021-10-15 00:00:00 | 2021-10-16 00:00:00 | heap
time_series_events_p2021_10_16 | 2021-10-16 00:00:00 | 2021-10-17 00:00:00 | heap
time_series_events_p2021_10_17 | 2021-10-17 00:00:00 | 2021-10-18 00:00:00 | heap
time_series_events_p2021_10_18 | 2021-10-18 00:00:00 | 2021-10-19 00:00:00 | heap
time_series_events_p2021_10_19 | 2021-10-19 00:00:00 | 2021-10-20 00:00:00 | heap
time_series_events_p2021_10_20 | 2021-10-20 00:00:00 | 2021-10-21 00:00:00 | heap
time_series_events_p2021_10_21 | 2021-10-21 00:00:00 | 2021-10-22 00:00:00 | heap
time_series_events_p2021_10_22 | 2021-10-22 00:00:00 | 2021-10-23 00:00:00 | heap
time_series_events_p2021_10_23 | 2021-10-23 00:00:00 | 2021-10-24 00:00:00 | heap
time_series_events_p2021_10_24 | 2021-10-24 00:00:00 | 2021-10-25 00:00:00 | heap
time_series_events_p2021_10_25 | 2021-10-25 00:00:00 | 2021-10-26 00:00:00 | heap
time_series_events_p2021_10_26 | 2021-10-26 00:00:00 | 2021-10-27 00:00:00 | heap
time_series_events_p2021_10_27 | 2021-10-27 00:00:00 | 2021-10-28 00:00:00 | heap
time_series_events_p2021_10_28 | 2021-10-28 00:00:00 | 2021-10-29 00:00:00 | heap
time_series_events_p2021_10_29 | 2021-10-29 00:00:00 | 2021-10-30 00:00:00 | heap
(20 rows)
In time series workloads, it is common to drop (or delete, or expire) old data once they are not required anymore. Having partitions, it becomes very efficient to drop old data as Postgres does not need to read all the data it drops. To make dropping partitions older than a given threshold easier, Citus 10.2 introduced the UDF drop_old_time_partitions.
-- drop partitions older than 2021-10-15
CALL drop_old_time_partitions(table_name:= 'time_series_events', older_than:= '2021-10-15');
-- check the details of partitions from time_partitions view
SELECT partition, from_value, to_value, access_method FROM time_partitions;
partition | from_value | to_value | access_method
--------------------------------+---------------------+---------------------+---------------
time_series_events_p2021_10_15 | 2021-10-15 00:00:00 | 2021-10-16 00:00:00 | heap
time_series_events_p2021_10_16 | 2021-10-16 00:00:00 | 2021-10-17 00:00:00 | heap
time_series_events_p2021_10_17 | 2021-10-17 00:00:00 | 2021-10-18 00:00:00 | heap
time_series_events_p2021_10_18 | 2021-10-18 00:00:00 | 2021-10-19 00:00:00 | heap
time_series_events_p2021_10_19 | 2021-10-19 00:00:00 | 2021-10-20 00:00:00 | heap
time_series_events_p2021_10_20 | 2021-10-20 00:00:00 | 2021-10-21 00:00:00 | heap
time_series_events_p2021_10_21 | 2021-10-21 00:00:00 | 2021-10-22 00:00:00 | heap
time_series_events_p2021_10_22 | 2021-10-22 00:00:00 | 2021-10-23 00:00:00 | heap
time_series_events_p2021_10_23 | 2021-10-23 00:00:00 | 2021-10-24 00:00:00 | heap
time_series_events_p2021_10_24 | 2021-10-24 00:00:00 | 2021-10-25 00:00:00 | heap
time_series_events_p2021_10_25 | 2021-10-25 00:00:00 | 2021-10-26 00:00:00 | heap
time_series_events_p2021_10_26 | 2021-10-26 00:00:00 | 2021-10-27 00:00:00 | heap
time_series_events_p2021_10_27 | 2021-10-27 00:00:00 | 2021-10-28 00:00:00 | heap
time_series_events_p2021_10_28 | 2021-10-28 00:00:00 | 2021-10-29 00:00:00 | heap
time_series_events_p2021_10_29 | 2021-10-29 00:00:00 | 2021-10-30 00:00:00 | heap
(15 rows)
Now, let's have a look at some more advanced features you can use once you've partitioned your Postgres table—particularly if you are dealing with challenges of scale
How to compress your older partitions with Citus columnar (now supports indexes too)
Starting with Citus 10, you can use columnar storage to compress your data in a Postgres table. Combining columnar compression with Postgres time partitioning, you can easily decrease the disk usage for your older partitions. Having partitions stored in a columnar fashion can also increase your analytical query performance as queries can skip over columns they don't need! If you haven't checked out columnar compression for Postgres yet, you can start with Jeff's columnar post for a detailed explanation. Or check out this demo video about how to use Citus columnar compression.
Using the UDF alter_old_partitions_set_access_method you can compress your partitions older than the given threshold by converting the access method from heap to columnar—or vice versa, you can also uncompress by converting the access method from columnar to heap.
alter_old_partitions_set_access_method(parent_table_name regclass, older_than timestamp with time zone, new_access_method name): For the given table, compress or uncompress all the partitions that are older than the given threshold.
-- compress partitions older than 2021-10-20
CALL alter_old_partitions_set_access_method('time_series_events', '2021-10-20', 'columnar');
-- check the details of partitions from time_partitions view
SELECT partition, from_value, to_value, access_method FROM time_partitions;
partition | from_value | to_value | access_method
--------------------------------+---------------------+---------------------+---------------
time_series_events_p2021_10_15 | 2021-10-15 00:00:00 | 2021-10-16 00:00:00 | columnar
time_series_events_p2021_10_16 | 2021-10-16 00:00:00 | 2021-10-17 00:00:00 | columnar
time_series_events_p2021_10_17 | 2021-10-17 00:00:00 | 2021-10-18 00:00:00 | columnar
time_series_events_p2021_10_18 | 2021-10-18 00:00:00 | 2021-10-19 00:00:00 | columnar
time_series_events_p2021_10_19 | 2021-10-19 00:00:00 | 2021-10-20 00:00:00 | columnar
time_series_events_p2021_10_20 | 2021-10-20 00:00:00 | 2021-10-21 00:00:00 | heap
time_series_events_p2021_10_21 | 2021-10-21 00:00:00 | 2021-10-22 00:00:00 | heap
time_series_events_p2021_10_22 | 2021-10-22 00:00:00 | 2021-10-23 00:00:00 | heap
time_series_events_p2021_10_23 | 2021-10-23 00:00:00 | 2021-10-24 00:00:00 | heap
time_series_events_p2021_10_24 | 2021-10-24 00:00:00 | 2021-10-25 00:00:00 | heap
time_series_events_p2021_10_25 | 2021-10-25 00:00:00 | 2021-10-26 00:00:00 | heap
time_series_events_p2021_10_26 | 2021-10-26 00:00:00 | 2021-10-27 00:00:00 | heap
time_series_events_p2021_10_27 | 2021-10-27 00:00:00 | 2021-10-28 00:00:00 | heap
time_series_events_p2021_10_28 | 2021-10-28 00:00:00 | 2021-10-29 00:00:00 | heap
time_series_events_p2021_10_29 | 2021-10-29 00:00:00 | 2021-10-30 00:00:00 | heap
(15 rows)
Since you can’t update or delete data on a compressed partition (at least not yet) you may want to use alter_table_set_access_method—which is another Citus’ UDF to compress/uncompress a table—to first uncompress your partition by providing heap as the last parameter. Once your partition is uncompressed and back in row-based storage (aka heap), you can update or delete your data. Then you can compress your partition again by calling alter_table_set_access_method and specifying columnar as the last parameter.
As of Citus 10.2, you can now have indexes1 on the compressed tables. Yes, you can now add indexes to your partitioned tables, even if some partitions of the table are compressed.
-- create index on a partitioned table with compressed partitions
CREATE INDEX index_on_partitioned_table ON time_series_events(user_id);
With these UDFs that make it easier to manage your time partitions—create_time_partitions, drop_old_time_partitions and alter_old_partitions_set_access_method—you can now fully automate partition management using pg_cron.
How to automate partition management with pg_cron
To automate partition management altogether, you can use pg_cron, an open source extension created and maintained by our team. pg_cron enables you to schedule cron-based jobs on Postgres.
You can use pg_cron to schedule these Citus functions for creating, dropping, and compressing partitions—thereby automating your Postgres partition management. Check out Marco’s pg_cron post for a detailed explanation of its usage and evolution over time.
Below is an example of using pg_cron to fully automate your partition management.
-- schedule cron jobs to
-- create partitions for the next 7 days
SELECT cron.schedule('create-partitions',
'@daily',
$$SELECT create_time_partitions(table_name:='time_series_events',
partition_interval:= '1 day',
end_at:= now() + '7 days') $$);
-- compress partitions older than 5 days
SELECT cron.schedule('compress-partitions',
'@daily',
$$CALL alter_old_partitions_set_access_method('time_series_events',
now() - interval '5 days', 'columnar') $$);
-- expire partitions older than 7 days
SELECT cron.schedule('expire-partitions',
'@daily',
$$CALL drop_old_time_partitions('time_series_events',
now() - interval '7 days') $$);
Note that UDFs scheduled above will be called once per each day since the second parameter of the cron.schedule is given as @daily. For other options you can check the cron syntax.
After scheduling those UDFs, you don’t need to think about managing your partitions anymore! Your pg_cron jobs will leverage Citus and Postgres to automatically:
- create your partitions for the given time span,
- compress partitions older than given compression threshold, and
- drop partitions older than given expiration threshold while you are working on your application.
If you want to dive deeper, the use case guide for time series data in our Citus docs will give you a more detailed explanation.
Using Citus’ UDFs to manage partitions and automating them using pg_cron, you can handle your time-series workload on a single Postgres node, hassle-free. Though, you might start to run into performance problems as your database gets bigger. This is where sharding comes in—as well as distributing your database across a cluster—as you can explore in the next two sections.
How to use Citus to shard partitions on a single node
To handle the high data volumes of time series data that cause the database to slow down over time, you can use sharding and partitioning together, splitting your data in 2 dimensions. Splitting your data in 2 dimensions gives you even smaller data and index sizes. To shard Postgres, you can use Citus. And as of Citus 10, you can now use Citus to shard Postgres on a single node—taking advantage of the query parallelism you get from Citus, and making your application “scale out ready”. Or you can use Citus in the way you might be more familiar with, to shard Postgres across multiple nodes.
Here let’s explore how to use Citus to shard your partitions on a single Citus node. And in the next section you’ll see how to use Citus to distribute your sharded partitions across multiple nodes.
To shard with Citus, the first thing you need to do is decide what your distribution column is (sometimes called a sharding key.) To split your data in 2 dimensions and make use of both Postgres partitioning and Citus sharding, the distribution column cannot be the same as the partitioning column. For time series data, since most people partition by time, you just need to pick a distribution column that makes sense for your application. The choosing distribution column guide in the Citus docs gives some useful guidance to help you out here.
Next, to tell Citus to shard your table, you need to use the Citus create_distributed_table function. Even if you are running Citus on a single node, partitions of your table will be sharded on the distribution column you choose. For the purposes of this example, we’ll use user_id as the distribution column.
-- shard partitioned table to have sharded partitioned table
SELECT create_distributed_table('time_series_events', 'user_id');
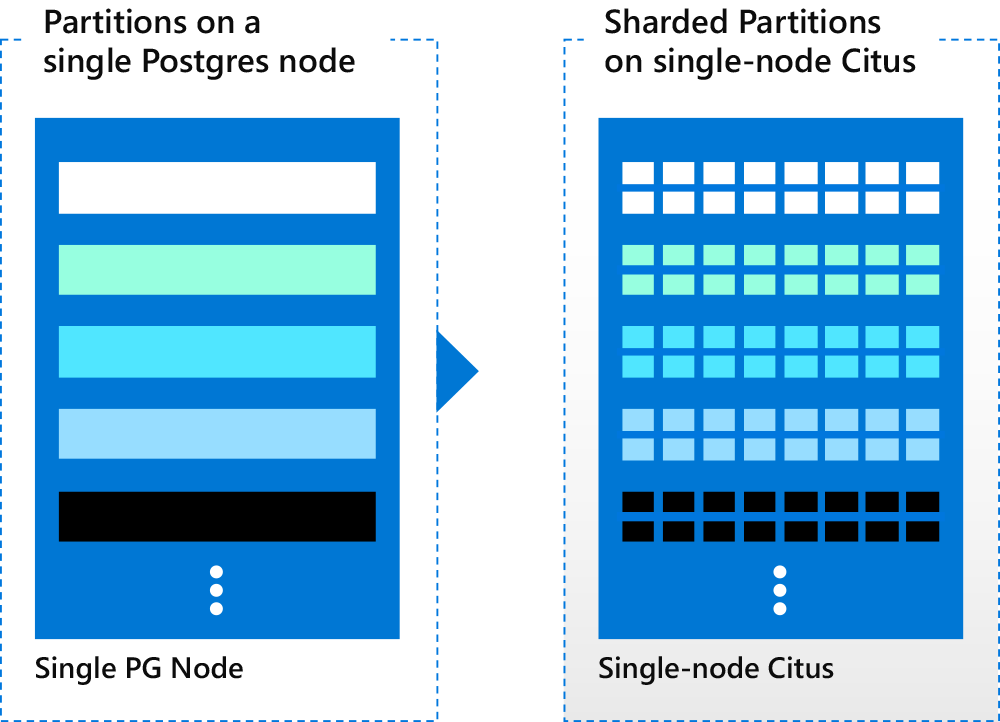
Once you shard your partitioned table on a single Citus node, you can easily distribute the table across multiple nodes by scaling out your Citus cluster.
How to use Citus to distribute your sharded partitions across multiple nodes
As your application needs to scale to manage more and more data, the resources (CPU, memory, disk) of the node can become a bottleneck. This is when you will want to shard and distribute Postgres across multiple nodes.
If you’ve already sharded your partitions on single-node Citus, you can easily distribute them by adding more Citus nodes and then rebalancing your tables across the cluster. Let's explore how to do this below.
To add a new node to the cluster, you first need to add the DNS name (or IP address of that node) and port to the pg_dist_node catalog table using citus_add_node UDF. (If you are running Citus on Azure as part of the managed service, you would just need to increase the worker node count in the Azure portal to add nodes to the cluster.)
-- Add new node to Citus cluster
SELECT citus_add_node('node-name', 5432);
Then, you need to rebalance your tables to move existing shards to a newly added node. You can use rebalance_table_shards to rebalance shards evenly among the nodes.
-- rebalance shards evenly among the nodes
SELECT rebalance_table_shards();
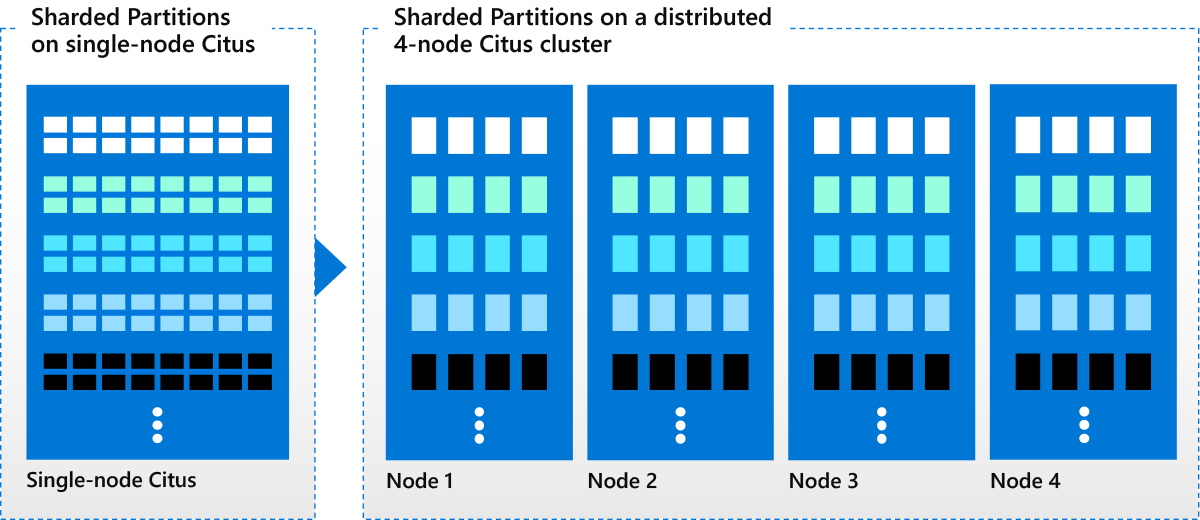
- Alternately, if you already have a multi-node Citus cluster and want to shard a partitioned table across the nodes in the cluster, you will need to use
create_distributed_tableto do so. Partitions will then be sharded across the nodes, on the distribution column that you specified.
You can check the Citus documentation for an even more detailed explanation of cluster management.
Other time partitioning extensions for PostgreSQL
Before we introduced the time-partitioning UDFs, the common approach to time-partitioning in Citus was to use the pg_partman extension. For some advanced scenarios, using pg_partman can still be beneficial. In particular, pg_partman supports creating a “template table”. You can use “template table” to have different indexes on different partitions. You can even create unique indexes not covering partitioning column with “template tables”. You can check pg_partman's documentation for all other functionalities.
Another time-partitioning extension for PostgreSQL is TimescaleDB. Unfortunately, Citus and TimescaleDB are currently not compatible. Importantly, Citus has a very mature distributed query engine that scales from a single node to petabyte scale time series workloads. Citus is also fully compatible with PostgreSQL 14, which has new features for handling time series data such as the date_bin function.
Citus as a distributed relational time series database
This post shows you how to manage your time series data in a scalable way. By combining the partitioning capabilities of Postgres, the distributed database features of Citus, and the automation of pg_cron—you get a distributed relational time series database. The new Citus user-defined functions for creating and dropping partitions make things so much easier, too.
| Capability | Description of Time series database features in Postgres with Citus |
|---|---|
| Partitioning | Use Postgres native range partitioning feature to split larger tables into smaller partitions, using time periods as the “range” |
| Partition Management | Use new functions in Citus to simplify management of time partitions |
| Compression | Use Citus Columnar to compress older partitions, saving on storage as well as improving query performance |
| Automation | Use the Postgres pg_cron extension to schedule partition creation, deletion and compression |
| Sharding | Use Citus to shard Postgres tables and increase query performance, either on single-node Citus or across a cluster |
| Distributing across nodes | Use Citus to distribute shards across multiple nodes; to enable parallel, distributed queries; & to use memory, CPU, and storage from multiple nodes |
If you want to try using Postgres with the Citus extension, you can download Citus packages or provision Citus in the cloud as a managed database service. You can learn about the latest Citus release in Onder’s 10.2 blog post or check out the time series use case guide in docs.
And if you have questions about scaling your time series workload or Citus in general, feel free to ping us via our public slack channel. To dig in further and try out Citus, our getting started page is a useful place to start.
Footnotes
