📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
Seasons each have a different feel, a different rhythm. Temperature, weather, sunlight, and traditions—they all vary by season. For me, summer usually includes a beach vacation. And winter brings the smell of hot apple cider on the stove, days in the mountains hoping for the next good snowstorm—and New Year’s resolutions. Somehow January is the time to pause and reflect on the accomplishments of the past year, to take stock in what worked, and what didn’t. And of course there are the TOP TEN LISTS.
Spoiler alert, yes, this is a Top 10 list. If you’re a regular on the Citus Data blog, you know our Citus database engineers love PostgreSQL. And one of the open source responsibilities we take seriously is the importance of sharing learnings, how-to’s, and expertise. One way we share learnings is by giving lots of conference talks (seems like I have to update our Events page every week with new events.) And another way we share our learnings is with our blog.
So just in case you missed any of our best posts from last year, here is the TOP TEN list of the most popular Citus Data blogs published in 2018. Enjoy.
The Postgres 10 feature you didn't know about: CREATE STATISTICS
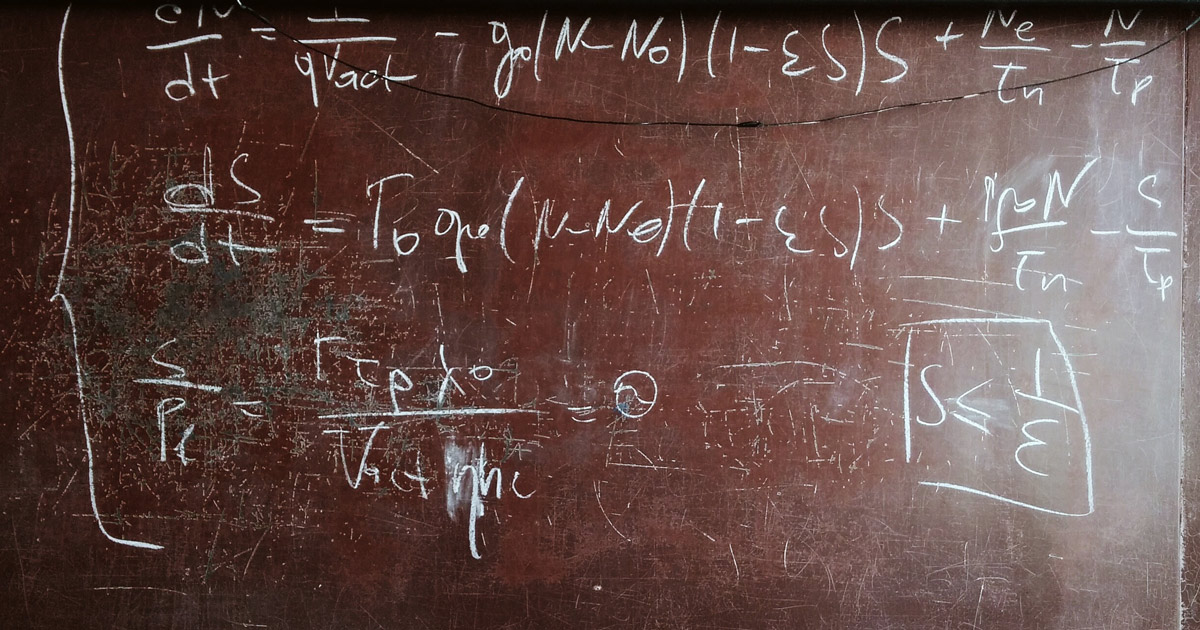
BY SAMAY SHARMA | Postgres stores a lot of statistics about your data in order to effectively retrieve results when you query your database. In this post, Samay dives deep into some of the statistics PostgreSQL stores and how you can leverage CREATE STATISTICS to improve query performance when different columns are related.
In Postgres, the EXPLAIN planner collects statistics to help it estimate how many rows will be returned after executing a certain part of the plan, which then influences which type of scan or join algorithm will be used. Before Postgres 10, there wasn’t an easy way to tell the planner to collect statistics which capture the relationship between columns. But since the release of Postgres 10, there’s a feature which is built to solve exactly this problem. And this feature has gotten even better in PostgreSQL 11, too. All about CREATE STATISTICS and how it can help you.
PostgreSQL rocks, except when it blocks: Understanding locks

BY MARCO SLOT | When Marco first published this post, it was a hit right away... and has continued to garner lots of reads, month after month. Why? Because while the open source Postgres database is really good at running multiple operations at the same time, there are some cases in which Postgres needs to block an operation using a lock—and so people want to understand locking behaviors in Postgres. Not all locks are bad of course, some are millisecond and don’t actually hold things up in your database.
This post is all about demystifying locking behaviors. Along with advice on how to avoid common problems, based on all the learnings Marco has accumulated in his work with Citus database users over the years.
Database sharding explained in plain English
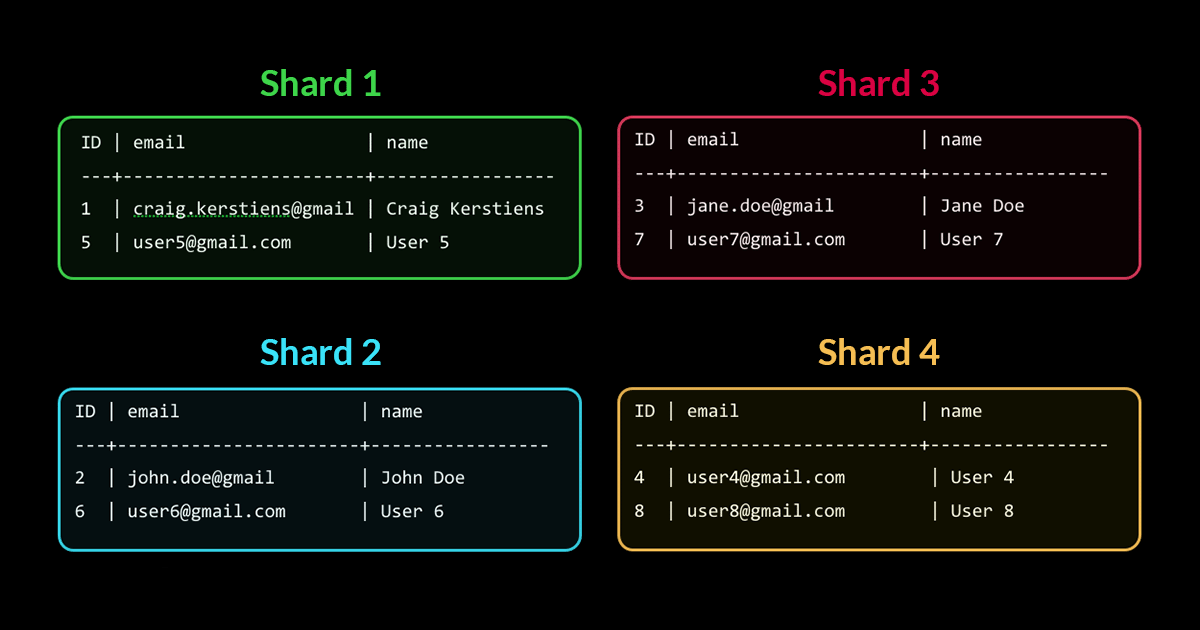
BY CRAIG KERSTIENS | Craig’s sharding in plain English post has become a go-to guide for understanding how sharding works for relational databases, and how it can be used to transform a single node database into a distributed one. Based on his experience leading the product team for the Citus Cloud database as a service (plus his Heroku Postgres experience before Citus), Craig found himself explaining how sharding works over and over again. So he finally put pen to paper, to explain sharding once and for all, in plain English. This post gives you an overview of the common misconceptions about sharding, partition keys, and key challenges.
When Postgres blocks: 7 tips for dealing with locks

BY MARCO SLOT | Marco highlights 7 do’s and don’ts that developers face when dealing with Postgres locks. Marco derived these tips from his work with developers building applications on top of Postgres and Citus, building both multi-tenant SaaS applications, and real-time analytics dashboards with time series data. Be sure to follow his advice not to freeze your database for hours with a VACUUM FULL.
Citus and pg_partman: Creating a scalable time series database on Postgres
BY CRAIG KERSTIENS | This post shows how you can leverage native time partitioning in Postgres via pg_partman, in combination with the Citus extension to Postgres. The result: a pretty awesome distributed relational time series database. pg_partman is best in class for improving time partitioning in Postgres—and by using pg_partman and Citus together, you can create tables that are distributed across nodes by ID and partitioned by time on disk.
Multi-tenant web apps with ASP.NET Core and Postgres

BY NATE BARBETTINI | This guest post gives you a step-by-step guide to building and architecting multi-tenant web applications for scale, using a combination of the open source, cross-platform ASP.NET Core framework, the awesome Postgres database, and the Citus extension to Postgres that transforms Postgres into a distributed database.
ASP.NET is used to build web applications and APIs, similar to other popular web frameworks like Express and Django. And it powers one of the biggest Q&A networks on the web: Stack Exchange. We wholeheartedly agree with Nate: it’s never too early to design for scale.
Why the RDBMS is the future of distributed databases

BY MARCO SLOT | Marco has a PhD in distributed systems, so he learned early on in life about the trade-offs between consistency and availability (aka the CAP theorem.) But in distributed systems, there are also trade-offs between latency, concurrency, scalability, durability, maintainability, functionality, operational simplicity, and other aspects of the system. And all these trade-offs have an impact on the features and user experience of applications.
In this post, Marco explains why the RDBMS is the future of distributed databases and how a distributed RDBMS like Citus can lower development costs for application developers. My favorite bit is the section on superpowers.
Three Approaches to PostgreSQL Replication and Backup
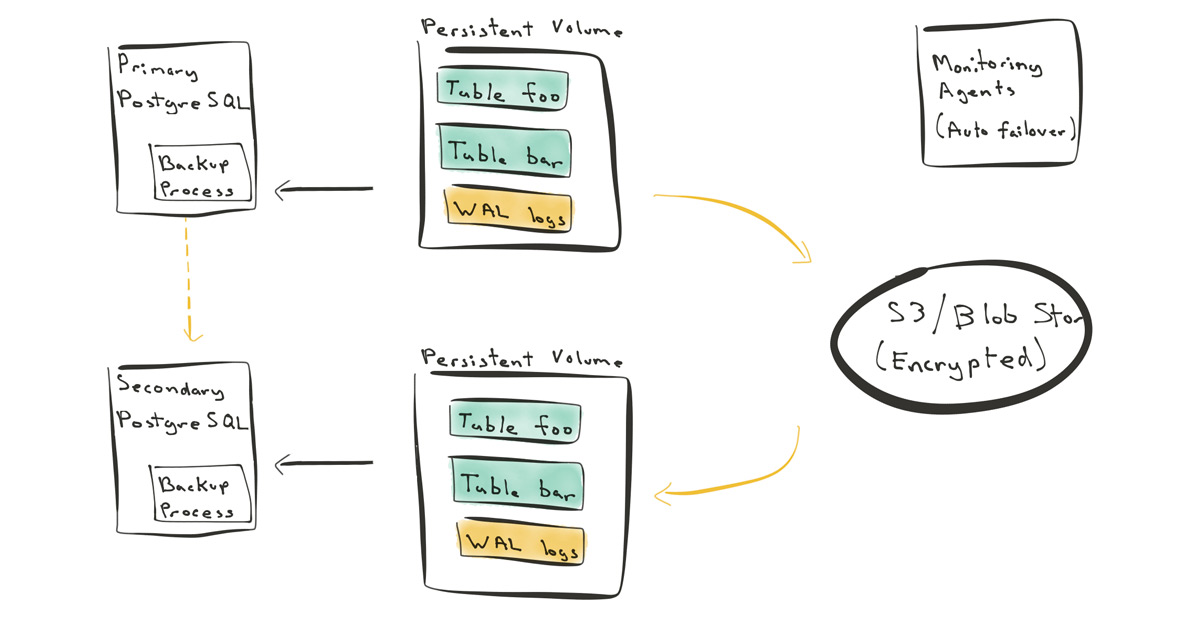
BY OZGUN ERDOGAN | Ozgun’s exploration of the three different approaches to PostgreSQL replication and backups got a lot of attention. This post explores streaming replication, volume replication via disk mirroring, WAL logs aka write-ahead logs, plus daily and incremental backups.
And while each PostgreSQL replication method has pros and cons, it turns out that one of the approaches is better in cloud-native environments, giving you both high availability (HA) and the ability to easily bring up or shoot down database nodes.
PostgreSQL 11 and Just In Time Compilation of Queries
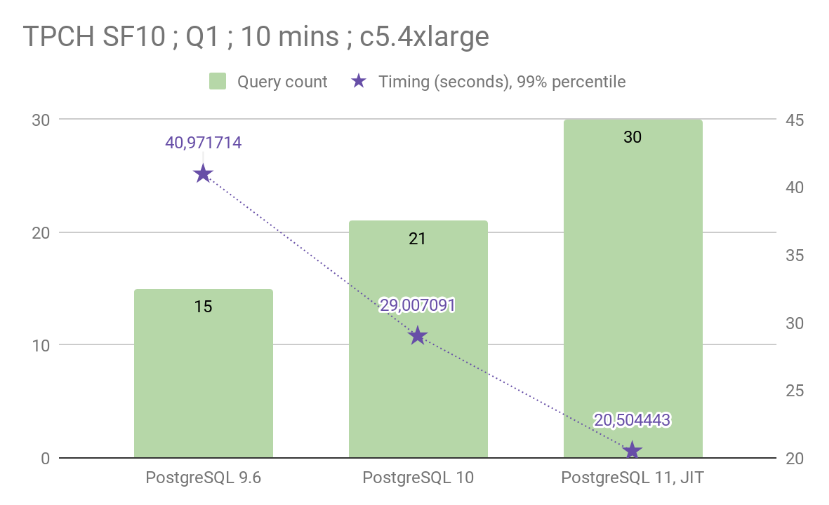
BY DIMITRI FONTAINE | Right before PostgreSQL 11 released, Dimitri blogged about this new component in the Postgres execution engine: a JIT expression compiler. And Dim shared compelling benchmark results that show up to 29.31% speed improvements in PostgreSQL 11 using the JIT expression compiler, executing TPC-H Q1 at scale factor 10 in 20.5s—vs. 29s when using PostgreSQL 10.
The new Postgres 11 JIT expression compiler is useful for long-running queries that are cpu-bound, such as queries with several complex expressions (think: aggregates.) Turns out that generating more efficient code that can run natively on the cpu (rather than passing queries through the Postgres interpreter) can sometimes be a good thing. :)
How Postgres is more than a relational database: Extensions

BY CRAIG KERSTIENS | The PostgreSQL Extension APIs have enabled so much innovation in the Postgres database world. Did you know PostGIS is an extension? (Of course you did.) HyperLogLog is an extension, too. And last year we created TopN, an extension to Postgres which Algolia uses. And then of course there’s Citus. :)
So it’s not a surprise when Craig observes that Postgres has shifted from being just a relational database to more of a “data platform”. The largest driver for this shift is Postgres extensions. This post gives you a tour of extensions and how they can transform Postgres into much more than a relational database.
Do you have a favorite? Let us know what type of Citus blog posts you’d like to see more of in 2019

Which one of these posts is your favorite? What type of Citus Data blog posts would you like to see more of in 2019? If you have ideas or feedback, we’d love to hear it: you can always tweet us @citusdata or you can send Craig Kerstiens or me a message on our Citus slack and let us know.
Turns out I don’t actually have a favorite among last year’s Top 10: each time I review one of our new blogs to edit them, I find myself grateful for this talented team I get to work with, and delighted to be learning something new. :)
