📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
PostgreSQL 11 is brewing and will be released soon. In the meantime, testing it with your own application is a great way to make sure the community catches all the remaining bugs before the dot-zero release.
One of the big changes in the next PostgreSQL release is the result of Andres Freund's work on the query executor engine. Andres has been working on this part of the system for a while now, and in the next release we are going to see a new component in the execution engine: a JIT expression compiler!
Benchmarks and TPC-H
One of the things I love about my engineering work at Citus Data working on scaling out PostgreSQL with the Citus extension is that I get to run benchmarks! Benchmarks are a great tool to show where performance improvements provide a benefit. The JIT expression compiler currently works best in the following situation:
- the query contains several complex expression such as aggregates.
- the query reads a fair amount of data but isn't starved on IO resources.
- the query is complex enough to warrant spending JIT efforts on it.
A query that fetches some information over a primary key surrogate id would not be a good candidate to see the improvements given by the new JIT infrastructure in PostgreSQL.
The TPC-H benchmark Q1 query is a good candidate for measuring the impact of the new executor stack at its best, so that's the one we're using here.
The specifications of the benchmark are available in a 137 pages PDF document named TPC Benchmark™ H. Each query in this specification comes with a business question, so here's Q1:
Pricing Summary Report Query (Q1)
This query reports the amount of business that was billed, shipped, and returned.
The Pricing Summary Report Query provides a summary pricing report for all lineitems shipped as of a given date. The date is within 60 - 120 days of the greatest ship date contained in the database. The query lists totals for extended price, discounted extended price, discounted extended price plus tax, average quantity, average extended price, and average discount. These aggregates are grouped by RETURNFLAG and LINESTATUS, and listed in ascending order of RETURNFLAG and LINESTATUS. A count of the number of lineitems in each group is included.
And here's what it looks like in SQL:
select
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count(*) as count_order
from
lineitem
where
l_shipdate <= date '1998-12-01' - interval ':1' day
group by
l_returnflag,
l_linestatus
order by
l_returnflag,
l_linestatus
:n -1
;
Also, the specification provides a comment about the query:
Comment: 1998-12-01 is the highest possible ship date as defined in the database population. (This is ENDDATE - 30). The query will include all lineitems shipped before this date minus DELTA days. The intent is to choose DELTA so that between 95% and 97% of the rows in the table are scanned.
For the query to qualify in showing the new PostgreSQL expression execution JIT compiler, we will pick a Scale Factor that fits into memory.
Results
When picking a Scale Factor of 10, we then get a database size of 22GB including the indexes created. The full schema used here is available at tpch-schema.sql with the indexes at tpch-pkeys.sql and tpch-index.sql.
In my testing, PostgreSQL 11 is about 29.31% faster at executing the TPCH Q1 query than PostgreSQL 10. When running the query in a loop for 10 minutes, it allowed PostgreSQL 11 to execute it 30 times when PostgreSQL 10 would execute the same query only 21 times.
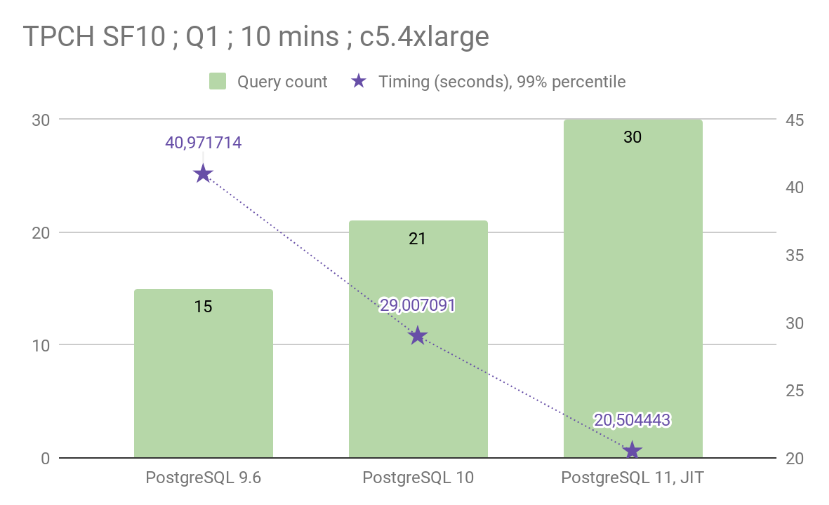
As we can see, Andres work in PostgreSQL 10 already did have a huge impact on this query. In this release, the executor evaluation of expressions was completely overhauled to take into account the CPU cache lines and instruction pipeline. In this benchmark we chose to disable parallel queries in PostgreSQL, so as to measure the improvements led mainly by the new executor. Parallel support in PostgreSQL 10 then 11 is able to enhance this query timing a lot on top of what we see here!
In PostgreSQL 11 the SQL expressions are transformed to machine code thanks to using LLVM compiler infrastructure at query planning time, which gives another very good impact on query performance!
Tooling
The benchmarking specifications are available in two files:
llvm-q1-infra.ini defines the AWS EC2 instances that have been used to run this test.
Here you can see that we selected
c5.4xlargeinstances to host our PostgreSQL database. They each have 30GB of RAM, so that our 22 GB data set and indexes fit nicely in RAM.Also, we picked the debian operating system, using packages from http://apt.postgresql.org, which provides PostgreSQL 11 development snapshot that we have been using here.
llvm-q1-schedule.ini defines our benchmark schedule, which is a very simple one here:
[schedule] full = initdb, single-user-stream, multi-user-streamIn the
initdbphase, load data for scale factor 10, in 8 concurrent processes, each doing a step at a time considering that we split the workload in 10 children.We are using TPC-H slang here. Also, in this TPC-H implementation for PostgreSQL that I worked on, I have added support for direct load mechanism, meaning that the
dbgentool connects to the database server and uses the COPY protocol.Then do a
single-user-streamwhich consists of running as many queries as we can from a single CPU on the client side, and for 10 mins.Then do a
multi-user-streamwhich consists of running as many queries as we can from all the 8 CPUs in parallel, and for 10 mins.
The benchmark tooling in use here is Open Source and freely available at https://github.com/dimitri/tpch-citus. It's a simple application that automates running TPCH in a dynamic on-purpose AWS EC2 infrastructure.
The idea is that after having created a couple of configuration files, it's possible to drive a full benchmark on several systems in parallel, and retrieve the results in a consolidated database for later analysis.
Also, the project includes a version of the TPCH C code that is adapted for PostgreSQL and implements direct load using the COPY protocol. Then, the project uses both the dbgen tool to generate the data, and also the qgen tool to generate a new query streams per client, as per specification.
Looking forward for future Postgres
PostgreSQL 11 introduces a new PostgreSQL execution engine that compiles your SQL code down to machine code, thanks to the LLVM framework. For queries that are expensive enough, those which are running through a lot of rows and evaluates the expressions over and over again, the benefits can be substantial!
To help PostgreSQL make the best possible release for version 11, consider using the beta version in your testing and CI environments, and report any bugs or performance regression you might find, with an easy way to reproduce them. See PostgreSQL 10.5 and 11 Beta 3 Released for the announcement and the details for how to report relevant findings.
In our benchmarking, PostgreSQL 11 JIT is an awesome piece of technology and provides up to 29.31% speed improvements, executing TPC-H Q1 at scale factor 10 in 20.5s instead of 29s when using PostgreSQL 10.
Here at Citus we’ve been busy testing the Citus extension against PostgreSQL for several months. Because Citus is a pure extension to Postgres and not a fork means that when the time comes you should be able to upgrade to get all the new benefits from Postgres 11 to help you keep scaling.
