The schedule is out 🗓️ for POSETTE: An Event for Postgres 2026!
The Citus distributed database scales out PostgreSQL through sharding, replication, and query parallelization. For replication, our database as a service (by default) leverages the streaming replication logic built into Postgres.
When we talk to Citus users, we often hear questions about setting up Postgres high availability (HA) clusters and managing backups. How do you handle replication and machine failures? What challenges do you run into when setting up Postgres HA?
The PostgreSQL database follows a straightforward replication model. In this model, all writes go to a primary node. The primary node then locally applies those changes and propagates them to secondary nodes.
In the context of Postgres, the built-in replication (known as "streaming replication") comes with several challenges:
- Postgres replication doesn’t come with built-in monitoring and failover. When the primary node fails, you need to promote a secondary to be the new primary. This promotion needs to happen in a way where clients write to only one primary node, and they don’t observe data inconsistencies.
- Many Postgres clients (written in different programming languages) talk to a single endpoint. When the primary node fails, these clients will keep retrying the same IP or DNS name. This makes failover visible to the application.
- Postgres replicates its entire state. When you need to construct a new secondary node, the secondary needs to replay the entire history of state change from the primary node. This process is resource intensive—and makes it expensive to kill nodes in the head and bring up new ones.
The first two challenges are well understood. Since the last challenge isn’t as widely recognized, we’ll examine it in this blog post.
Three approaches to replication in PostgreSQL
Most people think that when you have a primary and secondary architecture, there’s only one way to set up replication and backups. In practice, Postgres deployments follow one of three approaches.
- PostgreSQL streaming replication to replicate data from primary to secondary node. Back up to S3 / Blob storage.
- Volume level replication to replicate at the storage layer from primary to secondary node. Back up to S3 / Blob storage.
- Take incremental backups from the primary node to S3. Reconstruct a new secondary node from S3. When secondary is close enough to primary, start streaming from primary.
There’s also an easy way to identify which approach you’re using. Let’s say you added a new secondary node. How do you reconstruct the new secondary node’s state?
Approach 1: Streaming replication in PostgreSQL (with local storage)
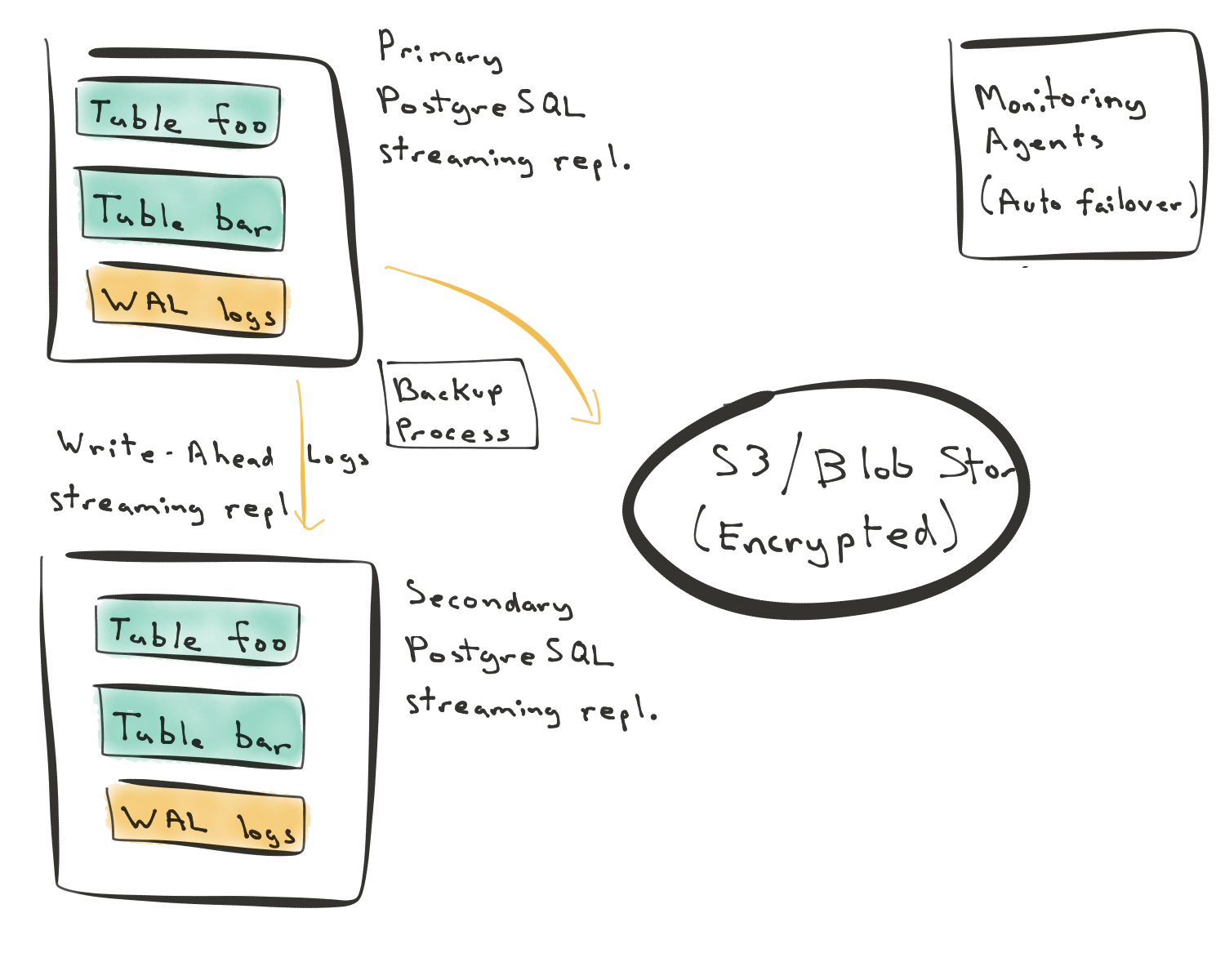
This first approach is the most common one. You have a primary node. The primary node has the tables’ data and write-ahead logs (WAL). (When you modify a row in Postgres, the change first gets committed to an append-only redo log. This redo log is known as a write-ahead log, or WAL.) This Postgres WAL log then gets streamed over to a secondary node.
In this first approach, when you build a new secondary node, the new secondary needs to replay the entire state from the primary node—from the beginning of time. The replay operation may then introduce a significant load on the primary node. This load becomes more important if your database’s primary node serves live traffic.
In this approach, you can use local disks or attach persistent volumes to your instances. In the diagram above, we’re using local disks because that’s the more typical setup.
Approach 2: Replicated Block Device
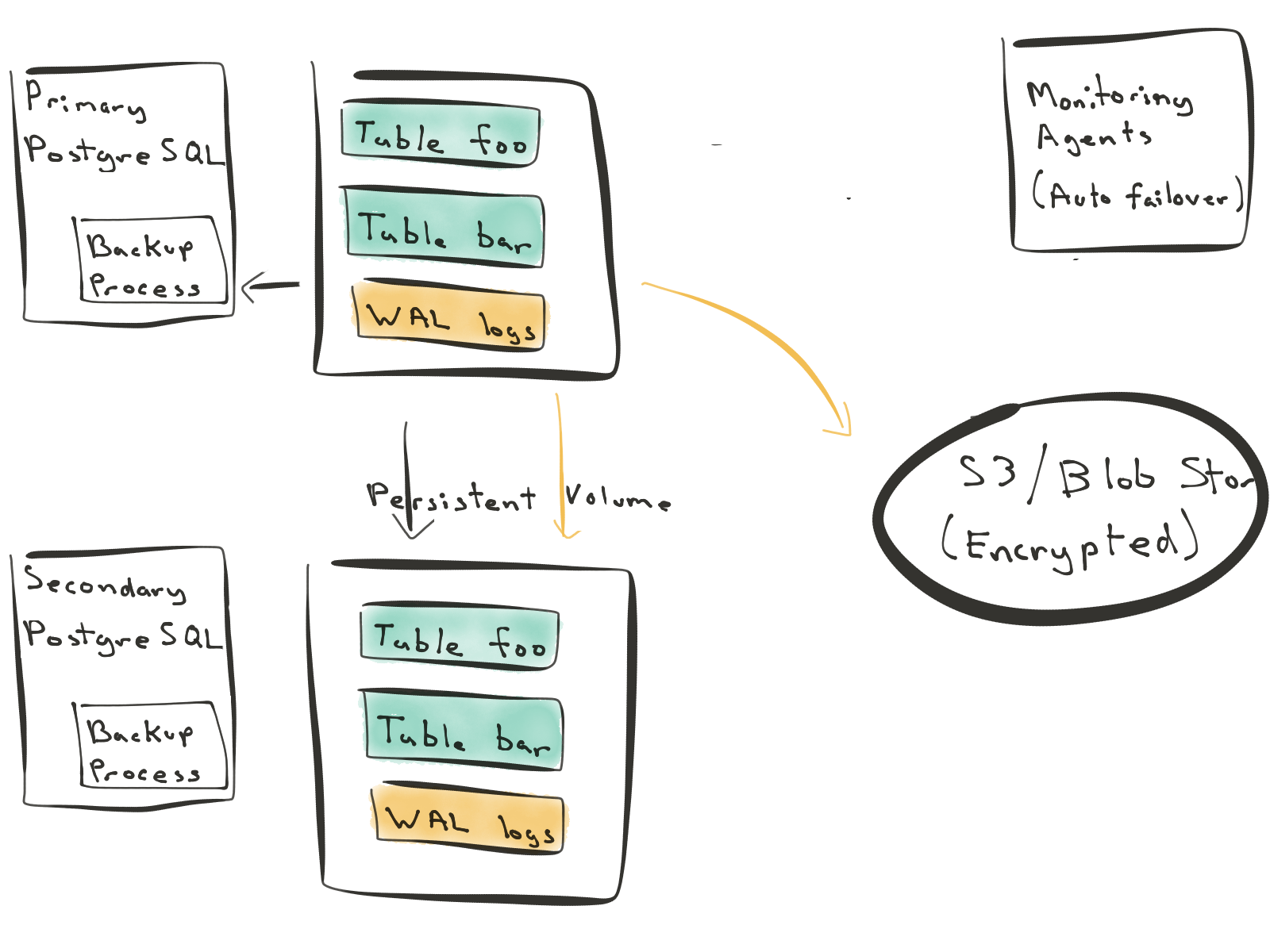
The second approach relies on disk mirroring (sometimes called volume replication.) In this approach, changes get written to a persistent volume. This volume then gets synchronously mirrored to another volume. The nice thing about this approach is that it works for all relational databases. You can use it for MySQL, PostgreSQL, or SQL Server.
However, the disk mirroring approach to replication in Postgres also requires that you replicate both table and WAL log data. Further, each write to the database now needs to synchronously go over the network. You can’t miss a single byte because that could leave your database in a corrupt state.
Approach #3: Reconstruct from WAL (and switch to streaming replication)
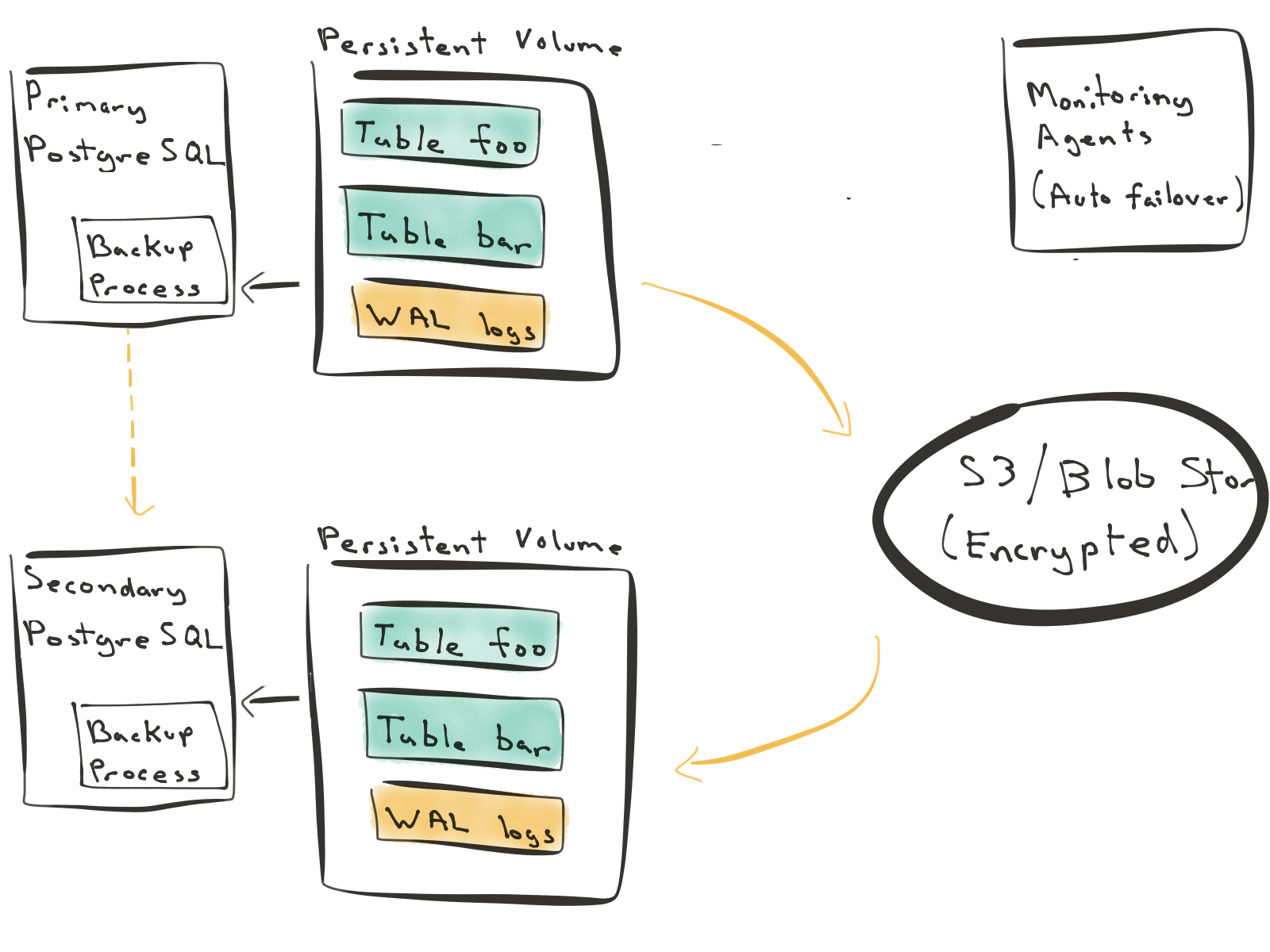
The third approach turns the replication and disaster recovery process inside out. You write to the primary node. The primary node does a full database backup every day, and incremental backups every 60 seconds.
When you need to construct a new secondary node, the secondary reconstructs its entire state from backups. This way, you don’t introduce any load on the primary database. You can bring up new secondary nodes and reconstruct them from S3 / Blob storage. When the secondary node is close enough to the primary, you can start streaming WAL logs from the primary and catch up with it. In normal state, the secondary node follows the primary node.
In this approach, write-ahead logs are first class citizens. This design lends itself to a more cloud-native architecture. You can bring up or shoot down replicas at will without impacting your relational database’s performance. You can also use synchronous or asynchronous replication depending on your requirements.
How do these different approaches to Postgres replication compare?
Here’s a simple table that compares these approaches to each other. For each approach, you can think of its benefits as drawbacks for the other approaches.
| Type of Postgres | Who does this? | Primary benefits |
|---|---|---|
| Simply streaming replication (local disk) | On-prem Manual EC2 | Simpler to setup High I/O performance and large storage |
| Replicated block device | RDS Azure Postgres | Works for MySQL, PostgreSQL Data duratbility in cloud environments |
| Reconstruct from WAL (and switch to streaming replication) | HerokuCitus Cloud | Node reconstruction in background Enables fork and PITR |
Simple streaming replication is the most common approach. Most on-prem deployments follow this approach. It’s easy to set up. Further, when you set it up using local disks, you can store 10s of TBs of data.
Comparatively, the disk mirroring approach abstracts away the storage layer from the database. In this approach, when you lose an instance, you don’t lose your ephemeral disk with it. This approach also works across database technologies, for example with MySQL and Postgres.
In the third method, when you have a new machine, you reconstruct that machine’s state from WAL logs. Since you’re treating your WAL logs as a first class citizen, certain features become trivial. For example, let’s say you wanted to performance test your application against production data, but not against the production database. In the third method, you can "fork" your database from a particular point in time in WAL logs without impact to production, and test your app against the forked database.
Which PostgreSQL replication method is more "cloud-native"?
PostgreSQL comes with three different replication methods. As with so many things, each replication method has its pros and cons.
The third approach reconstructs a new secondary node by replaying write-ahead logs (WAL) from blob storage such as S3. As a result, reconstructing a new replica doesn’t introduce any additional load on the primary node. This enables a high-availability (HA) solution where you can easily bring up or shoot down database nodes—a property that’s beneficial in cloud-native environments.
