The schedule is out 🗓️ for POSETTE: An Event for Postgres 2026!
Having a database staging environment that is as close to production as possible is key to being able to test your app. This applies to both your code and to your database. Far too often a staging database is a forgotten child in your stack—not getting the same love and attention as your production instance. For some teams, their staging database is years old, or worse yet, their staging database is a 10 GB sample of a 2 TB production database.
What if you could easily have a full staging environment to experiment with, that is an exact copy of your production database? Even if that production database is 50 TB?
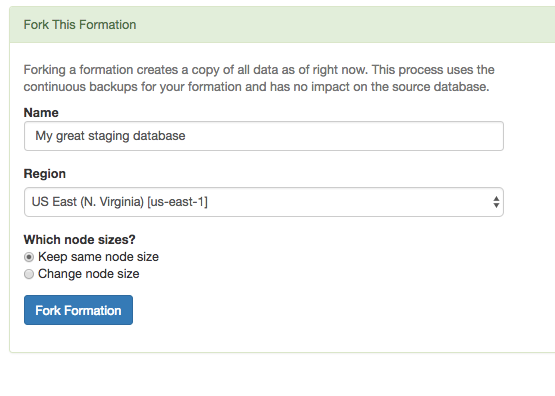
As of today on Citus Cloud—our fully-managed database as a service that is built to scale-out (and based on Postgres!)—you can get a full fork of your production database with the click of a button.
Let's dig in a little further on the ways you may want to use a fork of your database in Citus Cloud (called a ‘formation.’)
Database migrations are trivial except when they're not
 Database migrations may not happen daily, but they can happen weekly or monthly. Perhaps you are adding a whole new model, maybe it’s adding a field to an existing model. If you only have 10 GB of data on staging, your migration will only take seconds regardless of any database locks involved.
Database migrations may not happen daily, but they can happen weekly or monthly. Perhaps you are adding a whole new model, maybe it’s adding a field to an existing model. If you only have 10 GB of data on staging, your migration will only take seconds regardless of any database locks involved.
Pro-tip: When adding new columns to existing tables, it's always good to follow a multi-step process. First step allow nulls but set a default value, in the background update the previous values, then add your not null constraint as another migration. To learn more here’s a great post on best practices for database migrations in Rails.
The problem with your migration running fast in staging is in production it could take significantly longer if the data is larger.
On a production database, without following a multi-step migration like linked to above the database would take a lock and queue up all writes. Queuing up writes could cause the migration in cases to take up to hours on a very large table. Having a staging environment that is the same data set as production allows you to catch these issues before you run the database migration live on production. The same applies for table modifications, new indexes, or even to test Citus shard rebalancing.
Fork gives you a safe place for crazy experiments
What if it's not just a common database migration and instead you have a theory you want to test? Do you think that denormalizing that weird table would speed things up? What about creating a rollup table for the dashboard? How can you persuade your manager that you need more RAM in your coordinator, not in your data nodes?
All of those questions would be easier to explore and validate if you could test your hypotheses against production data.
In these cases, what you need is a temporary copy of the production database. But it would take forever to copy that 2 TB of data to a new instance. Not to mention that it would cause load on the production database. Thus common wisdom says it not a good idea to copy the production database. And the common wisdom used to be true. But now there’s a better way…
Because a fork fetches the data from S3 by leveraging wal-e, it has zero effect on the production load. Apply your changes to the fork, run your experiments, and then you can destroy the fork.
Fork creates a playground for "data people"
We’ve all been there, you want to run some long running report against production. You fire off the query, and then you wait until someone else comes running over to your desk telling you to cancel it. Sure the report you want is valuable, but it’s not worth risking production downtime.
What you really need is the ability to run complex analytical queries that may take hours, without bringing production down.
Sometimes, you may want to do even more than just run some reports. You may want to manipulate the data: denormalize tables, create aggregations, create an index, or even pull all the data into one machine.
Put a fork in it & get started exploring your data with Citus today
Inside your production database there are a wealth of insights. Historically there has been a trade-off between granting access so people can leverage the insights hidden within the data—versus keeping the keys to the kingdom safe to protect your uptime. Now, with our Citus database as a service and our new fork capability, *you can create a fork *of your production database and give it to whoever wants to play with real data!
For all Citus customers who use our fully-managed database as a service, the ability to fork your database cluster is live today. Give it a try for all of your staging, experimentation, and reporting needs. And if you have any questions on forking your data or in general working with Citus feel free to drop us a line, we’d be happy to chat with you and help.