📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
One of the most common questions we get at Citus is how the rebalancer works–which is understandable. When you have an elastic scaled out database, how easy it is to scale is a key factor into how usable it will be. While we'll happily take time for anyone that's interested and live demo it, this walk through should give you a better idea of how it works for those of you that are curious.
Some initial context
First, lets start off with a little bit of terminology.
A shard in Citus is a Postgres table under the covers. When you insert data into Citus you'll have a shard key, for this case lets assume it's customer_id if we're following the multi-tenant data model, Citus will take a hash of that customer_id and then based on the hash value insert it into the appropriate table. Up front when creating your distributed tables Citus will automatically create the shards (or Postgres tables) for you, the default is 32, you can also customize this number.
The other key term is a node. A node is a running Postgres instance, in most cases it's a single machine or VM, though if you truly wanted it could all be the same physical instance. As you scale your database with Citus you have the option of scaling up the nodes or adding more, both of which should allow you to improve performance. And then as you add nodes to your system you can then rebalance the data which we'll get to in a moment.
So to recap tenants, shards, and nodes. Within a single shard you can have multiple tenants, and then within a single node you can have multiple shards.
Adding nodes
To add nodes you bring up your new Postgres instance, make sure Citus is installed, then on your coordinator you'd run:
SELECT * from master_add_node('node-name', 5432);
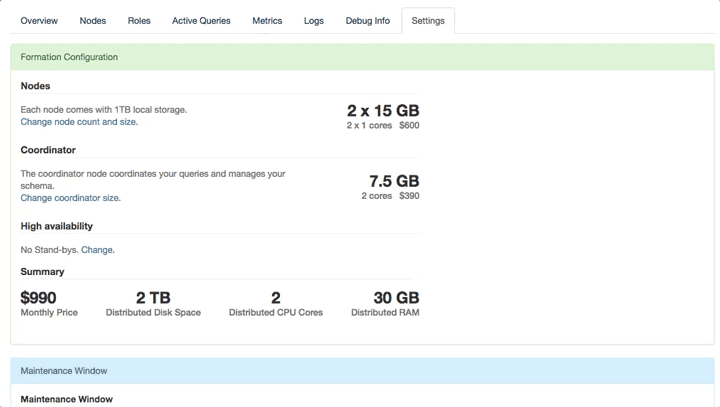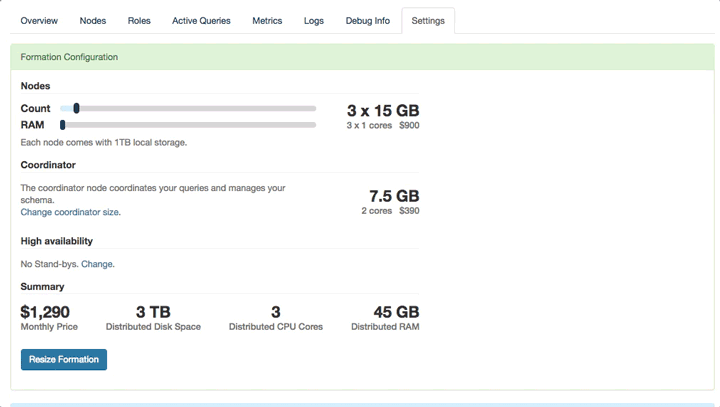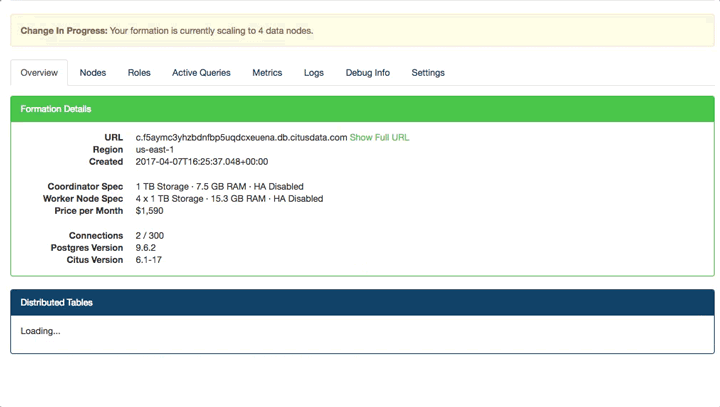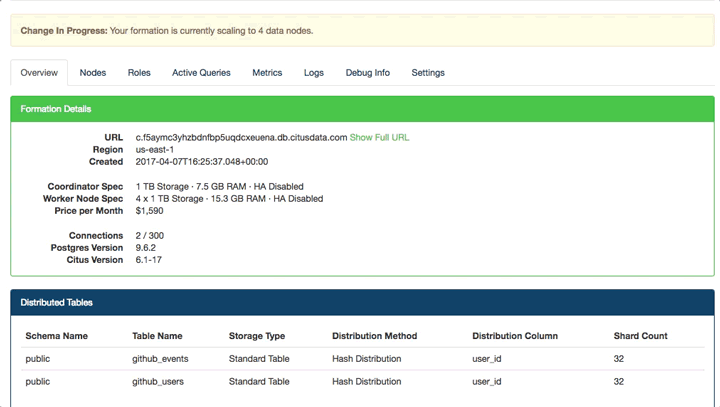
Or on Citus Cloud this is as simple as going to the settings tab clicking on Change node count and size and then selecting your new node count and hitting save.
Rebalancing
Once you've added your node it's not going to have done any magic yet to put existing shards on your new nodes. This is where the rebalancer comes in. The rebalancer works on each shard and other shards that relate to it at a time.
When the rebalancer runs under the covers it moves each table. While this move is happening it takes a standard Postgres advisory locks on the shard IDs, any write takes a share lock, and the shard rebalancer takes an exclusive lock. This allows us to have all reads flow through as normally expected. Writes during that time are queued up at the coordinator and then proceed through once completed. The rebalancer will conduct this operation for each colocation group within the cluster, so while writes will be queued up they'll do so for each shard individually as opposed to for the whole cluster. The rebalancer does run across all shards in the cluster, thus a full rebalance could take hours, but the effect on each shard being minutes.
SELECT rebalance_table_shards('github_events');
Let's go ahead and run this:
If you notice while it's running you get insights of which shard is being moved. During that operation we jumped over to another terminal session connected to the same database to run some queries. As you can see all queries are flowing through and performing as normal.
A note: Shard rebalancing is similar in nature to tenant isolation which is also a tool in your toolbox should you need to ensure performance and isolation for a single tenant
Get started
The rebalancer is part of Citus Enterprise edition, which is also run on top of Citus Cloud, our database-as-a-service offering on top of AWS. If you have a need to continue scaling your database beyond a single node with the elastic scaling of Citus sign-up for an account and give us a try today.