The schedule is out 🗓️ for POSETTE: An Event for Postgres 2026!
Around 10 years ago I joined Amazon Web Services and that’s where I first saw the importance of trade-offs in distributed systems. In university I had already learned about the trade-offs between consistency and availability (the CAP theorem), but in practice the spectrum goes a lot deeper than that. Any design decision may involve trade-offs between latency, concurrency, scalability, durability, maintainability, functionality, operational simplicity, and other aspects of the system—and those trade-offs have meaningful impact on the features and user experience of the application, and even on the effectiveness of the business itself.
Perhaps the most challenging problem in distributed systems, in which the need for trade-offs is most apparent, is building a distributed database. When applications began to require databases that could scale across many servers, database developers began to make extreme trade-offs. In order to achieve scalability over many nodes, distributed key-value stores (NoSQL) put aside the rich feature set offered by the traditional relational database management systems (RDBMS), including SQL, joins, foreign keys, and ACID guarantees. Since everyone wants scalability, it would only be a matter of time before the RDBMS would disappear, right? Actually, relational databases have continued to dominate the database landscape. And here's why:
The most important aspect to consider when making trade-offs in a distributed system (or any system) is development cost.
The trade-offs made by your database software will have significant impact on the development cost of your application. Handling data in an advanced application that needs to be usable, reliable, and performant is a problem that is inherently complex to solve. The number of man hours required to successfully address every little subproblem can be enormous. Fortunately, a database can take care of many of these subproblems, but database developers face the cost problem as well. It actually takes many decades to build the functionality, guarantees, and performance that make a database good enough for most applications. That’s where time and again, established relational databases like PostgreSQL and MySQL come in.
At Citus Data, we’ve taken a different angle to addressing the need for database scalability. My team and I spent the past several years transforming an established RDBMS into a distributed database, without losing its powerful capabilities or forking from the underlying project. In doing so we found that an RDBMS is the perfect foundation for building a distributed database.
Lowering application development costs by building on top of an RDBMS
What makes an RDBMS so attractive for developing an application—especially an open source RDBMS, and especially a cloud RDBMS—is that you can effectively leverage the engineering investments that have been made into the RDBMS over a period of decades and utilise these RDBMS capabilities in your app, lowering your development cost.
An RDBMS provides you with:
- meaningful guarantees around data integrity and durability
- enormous flexibility to manipulate and query your data
- state-of-the-art algorithms and data structures for getting high performance under diverse workloads.
These capabilities matter to almost any non-trivial application, but take a long time to develop. On the other hand, some applications have a workload that is too demanding for a single machine and therefore require horizontal scalability.
Many new distributed databases are being developed and are implementing RDBMS functionality like SQL on top of distributed key-value stores (“NewSQL”). While these newer database can use the resources of multiple machines, they are still nowhere near the established relational database systems in terms of SQL support, query performance, concurrency, indexing, foreign keys, transactions, stored procedures, etc. Using such a database leaves you with many complex problems to solve in your application.
An alternative that has been employed by many big Internet companies is manual, application-layer sharding of an RDBMS—typically PostgreSQL or MySQL. Manual sharding means that there are many RDBMS nodes and the application decides which node to connect to based on some condition (e.g. the user ID). The application itself is responsible for how to handle data placement, schema changes, querying multiple nodes, replicating tables, etc—so if you’re doing manual sharding, you end up implementing your own distributed database within your application, which is perhaps even more costly.
Fortunately, there is a way around the development cost conundrum.
PostgreSQL has been under development for several decades, with an incredible focus on code quality, modularity, and extensibility. This extensibility offers a unique opportunity: to transform PostgreSQL into a distributed database, without forking it. That’s how we built Citus.
Citus: Becoming the world’s most advanced distributed database
When I joined a start-up called Citus Data around 5 years ago, I was humbled by the challenge of building an advanced distributed database in a competitive market without any existing infrastructure, brand recognition, go to market, capital, or large pool of engineers. The development cost alone seemed like it would be insurmountable. But in the same way that application developers leverage PostgreSQL to build a complex application, we leveraged PostgreSQL to build... distributed PostgreSQL.
Instead of creating a distributed database from scratch, we created Citus, an open source PostgreSQL extension that transparently distributes tables and queries in a way that provides horizontal scale, but with all the PostgreSQL features that application developers need to be successful.
Using internal hooks that Postgres calls when planning a query, we were able to add the concept of a distributed table to Postgres.
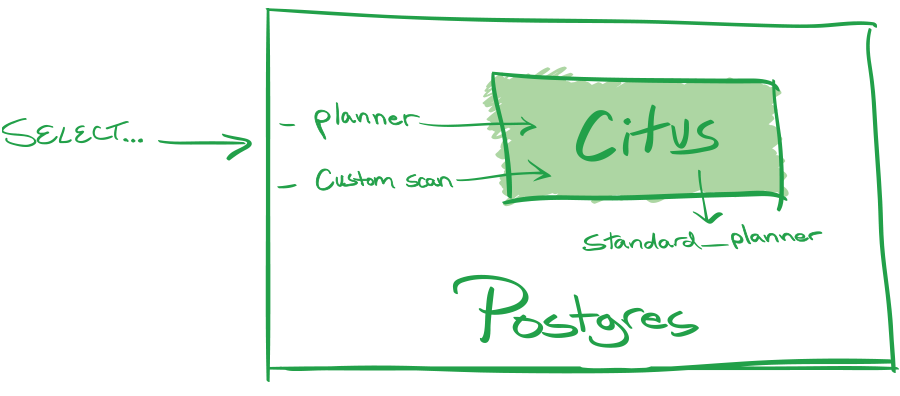
The shards of a distributed table are stored in regular PostgreSQL nodes with all their existing capabilities, and Citus sends regular SQL commands to query the shards and then combines the results. We also added the concept of a reference table, which is replicated across all nodes and can therefore be joined with the distributed tables by any column. By further adding support for distributed transactions, query routing, distributed subqueries and CTEs, sequences, upserts and more, we got to a point where most advanced PostgreSQL features just work, but now at scale.
Citus is still relatively young but is already one of the most advanced distributed databases in the world by building on top of PostgreSQL. While comparing to the full feature set of PostgreSQL is humbling and there is still a lot to do, the capabilities that Citus provides today and the way it scales out, make it largely unique in the distributed database landscape. Many current Citus users initially built their business on a single node PostgreSQL server, using many of the advanced capabilities in Postgres, and then migrated to Citus with only a few weeks of development effort to convert their database schema to distributed and reference tables. With any other database, such a migration from a single-node database to a distributed database could have taken months—or even years.
Turning Postgres features into superpowers using Citus
An RDBMS like PostgreSQL has an almost endless array of features and a mature SQL engine, which lets you query your data in infinitely many ways. Of course, these features are only useful to an application if they are also fast. Fortunately, PostgreSQL is fast and keeps getting faster with new features such as just-in-time query compilation, but when you have so much data or traffic that a single machine is too slow then those powerful features aren’t quite as useful anymore... unless you can combine the computing power of many machines. That’s where features become superpowers.
By taking PostgreSQL features and scaling them out, Citus has a number of superpowers that enables users to grow their database to any size while maintaining high performance and all its functionality.
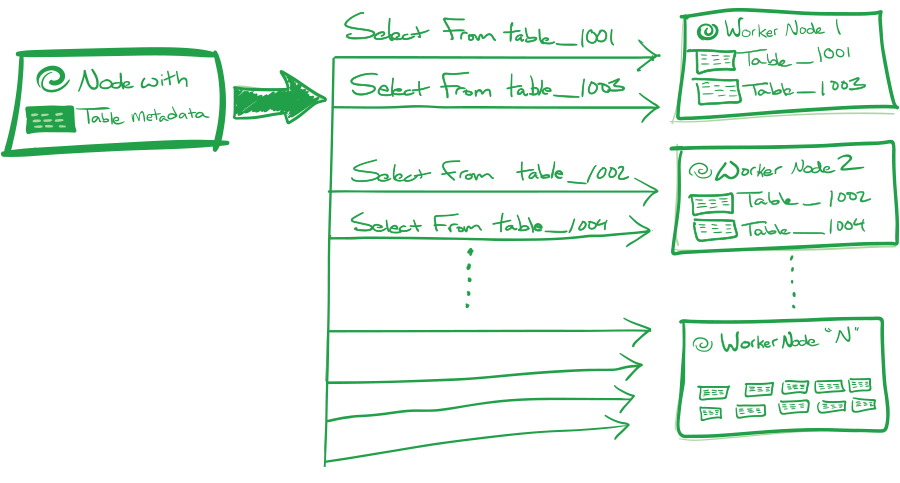
Query routing means taking (part of) the query and letting the RDBMS node that stores the relevant shards handle the query instead of gathering or reshuffling the intermediate results, which is possible when the query filters and joins by the distribution column. Query routing allows Citus to support all the SQL functionality of the underlying PostgreSQL servers at scale for multi-tenant (SaaS) applications, which typically filter by tenant ID. This approach has minimal overhead in terms of distributed query planning time and network traffic, which enables high concurrency and low latency.
Parallel, distributed SELECT across all shards in a distributed table allows you to query large amounts of data in a fraction of the time compared to sequential execution, which means that you can build applications that have consistent response times even as your data and number of customers grow by scaling out your database. The Citus query planner converts SELECT queries that read data from multiple shards into one or more map-reduce-like steps, where each shard is queried in parallel (map) and then the results are merged or reshuffled (reduce). For linear scale, most work should be done in the map steps, which is typically the case for queries that join or group by the distribution column.
Joins are an essential part of SQL for two reasons: 1) they give enormous flexibility to query your data in different ways allowing you to avoid complex data processing logic in your application, 2) they allow you to make your data representation a lot more compact. Without joins, you need to store a lot of redundant information in every row, which drastically increases the amount of hardware your need to store or scan the table, or keep it in memory. With joins, you can store a compact opaque ID and do advanced filtering without having to read all the data.
Reference tables appear like any other table but they are transparently replicated across all the nodes in the cluster. In a typical star schema all your dimension tables would be reference tables and your facts table a distributed table. The facts table can then be joined (in parallel!) with any of the dimension tables on any column without moving any data over the network. In multi-tenant applications, reference tables can be used to hold data that is shared among tenants.
Subquery pushdown is the marriage between parallel, distributed SELECT, query routing and joins. Queries across all shards that include advanced subquery trees (e.g. joins between subqueries) can be parallelised in a single round through subquery pushdown as long as they join all distributed tables on the distribution column (while reference tables can be joined on any column). This enables very advanced analytical queries that still exhibit linear scalability. Citus can recognise pushdownable subqueries by leveraging the transformations that the PostgreSQL planner already does for all queries, and generate separate plans for all remaining subqueries. This allows all kinds of subqueries and CTEs to be efficiently distributed.
Indexes are like the legs of a table. Without them, it’s going to take a lot of effort to get things from the table, and it’s not really a table. PostgreSQL in particular provides very powerful indexing features such as partial indexes, expression indexes, GIN, GiST, BRIN, and covering indexes. This allows queries (including joins!) to remain fast even at massive scale. It’s worth remembering that an index lookup is usually faster than a thousand cores scanning through the data. Citus supports all PostgreSQL index types by indexing individual shards. Power users like Heap and Microsoft especially like to use partial indexes to handle diverse queries over many different event types.
Distributed transactions allow you to make a set of changes at once or not at all, which greatly adds to the reliability of your application. Citus can delegate transactions to PostgreSQL nodes using a method that is similar to query pushdown, inheriting its ACID properties. For transactions across shards, Citus uses PostgreSQL’s built-in 2PC machinery and adds a distributed deadlock detector that uses internal PostgreSQL functions to get lock tables from all the nodes.
Parallel, distributed DML allows very large amounts of data to be transformed and maintained in relatively little time and in a transactional manner. A common application of distributed DML is an INSERT...SELECT command which aggregates rows from a raw data table into a rollup table. By parallelising the INSERT...SELECT over all available cores, the database will always be fast enough to aggregate the incoming events, while the application (e.g. dashboard) queries the compact, heavily indexed rollup table. Another example is a Citus user who ingested 26 billion rows of bad data and fixed it using distributed updates that modified over 700k rows/sec on average.
Bulk loading is an essential feature for applications that analyse large volumes of data. Even on a single node, PostgreSQL’s COPY command can append hundreds of thousands of rows per second to a table, which already beats most distributed database benchmarks. Citus can fan out the COPY stream to append and index many rows in parallel across many PostgreSQL servers, which scales to millions of rows per second.
Stored procedures and functions (incl. triggers) provide a programming environment inside your database for implementing business logic that cannot be captured by a single SQL query. The ability to program your database is especially beneficial when you need a set of operations to be transactional, but you have no need to go back-and-forth between your application server and the database. Using a stored procedure simplifies your app and makes the database more efficient since you avoid keeping transactions open while making network round-trips. While it may put slightly more load on your database, this becomes much less of an issue when your database scales.
While most of these features seem essential to develop a complex application which needs to scale, far from all distributed databases support them. Below we give a comparison of some popular distributed databases based on publicly available documentation.
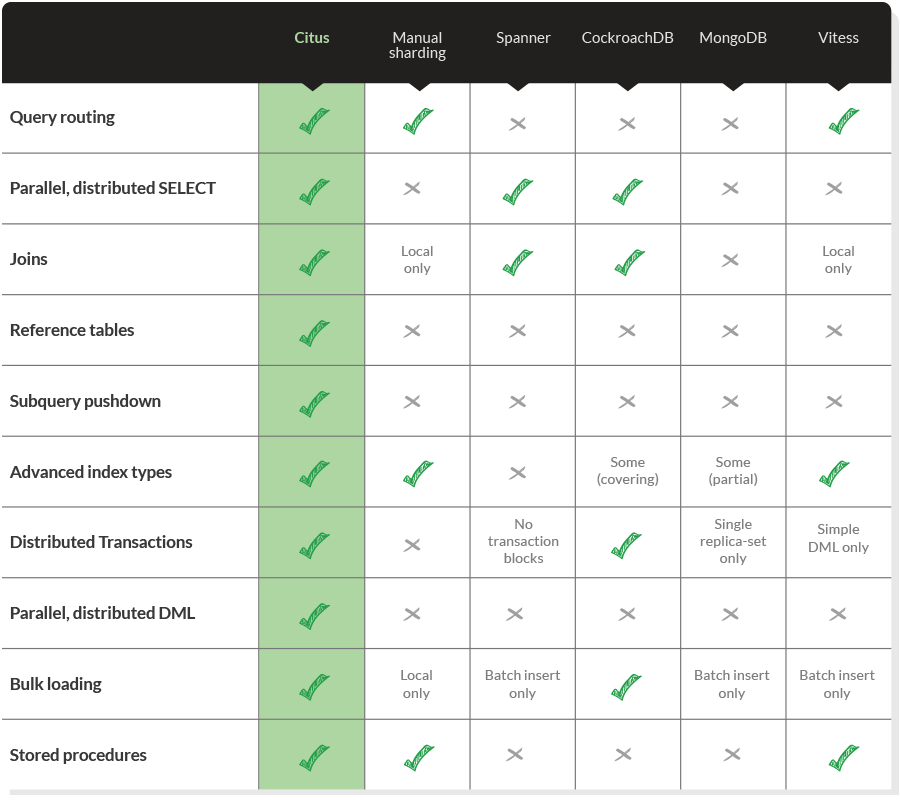
Let our powers combine...
What’s even more important than having superpowers in your distributed database is being able to combine your database superpowers in order to solve a complex use case.

Support for query routing, reference tables, indexes, distributed transactions and stored procedures makes even the most advanced multi-tenant OLTP apps such as Copper able to scale beyond a single PostgreSQL node using Citus without making any sacrifices in their application.
If you use subquery pushdown in combination with parallel, distributed DML, then you can transform large volumes data inside the database. A common example is building a rollup table using INSERT...SELECT, which can be parallelised to keep up with any kind of data volume. Combined with bulk loading through COPY, indexes, joins, and partitioning, you have a database that is supremely suitable for time series data and real-time analytics applications like the Algolia dashboard at scale.
As Min Wei from Microsoft pointed out in his talk about how Microsoft uses Citus and PostgreSQL to analyse Windows data: Citus enables you to solve large scale OLAP problems using distributed OLTP.
GoodOldSQL
Citus is a little different from other distributed databases, which are often developed from scratch. Citus does not introduce any functionality that wasn’t already in PostgreSQL. The Citus database makes existing functionality scale in a way that satisfies use cases that require scale. What’s important is that most of the PostgreSQL functionality has been developed and battle-tested over decades for a wide range of use cases, and the functional requirements for today’s use cases are ultimately not that different; it’s primarily the scale and size of data that’s different. That is why a distributed database like Citus, that’s built on top of the world’s most advanced open source RDBMS (PostgreSQL!), can be the most powerful tool in your arsenal when building a modern application.
