📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
This post by Claire Giordano about Hyperscale (Citus) was originally published on the Azure Database for PostgreSQL Blog on Microsoft TechCommunity.
Update in October 2022: Citus has a new home on Azure! The Citus database is now available as a managed service in the cloud as Azure Cosmos DB for PostgreSQL. Azure documentation links have been updated throughout the post, to point to the new Azure docs.
If you've built your application on Postgres, you already know why so many people love Postgres.
And if you're new to Postgres, the list of reasons people love Postgres is loooong—and includes things like: 3 decades of database reliability baked in; rich datatypes; support for custom types; myriad index types from B-tree to GIN to BRIN to GiST; support for JSON and JSONB from early days; constraints; foreign data wrappers; rollups; the geospatial capabilities of the PostGIS extension, and all the innovations that come from the many Postgres extensions.
But what to do if your Postgres database gets very large?
What if all the memory and compute on a single Postgres server can't meet the needs of your application?
In this post, let's walk through when you might want to scale out Postgres horizontally. Specifically, when to use Hyperscale (Citus), a built-in deployment option in our Azure Database for PostgreSQL managed service. But first: what exactly is Hyperscale (Citus)?
What is Hyperscale (Citus) in Azure Database for PostgreSQL?
Citus is an open source extension to Postgres that transforms Postgres into a distributed database.
Citus uses sharding and replication to distribute your Postgres tables and queries across multiple machines—parallelizing your workload and enabling you to use the memory, compute, and disk of a multi-machine database cluster.
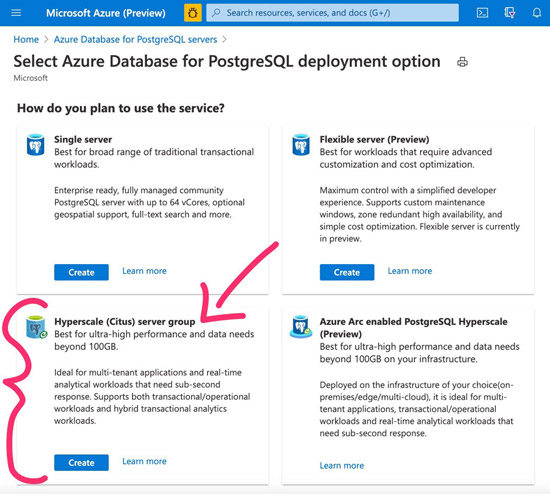
Hyperscale (Citus) is the integration of the Citus extension with our managed Postgres service on Azure. When you go to provision an Azure Database for PostgreSQL server on the Azure portal, you'll see Hyperscale (Citus) is one of the built-in deployment options available to you. (See Figure 1 below.) Under the covers, the Citus open source extension is at the core of Hyperscale (Citus).
In short: Hyperscale (Citus) = managed Postgres service on Azure + Citus
Why would you want to use Hyperscale (Citus) to scale out Postgres on Azure?
- Performance: Because your single node Postgres is not performant enough and cannot keep up with the peaks in your workload.
- Scale: Because your application is growing fast and you want to prepare your Postgres deployment to scale out before you run into performance issues, before you have to send your customers apology letters for poor performance.
- Migrating off Oracle: Because you're migrating off Oracle and you've determined that a scaled-out Postgres deployment will best meet your application's database requirements.
The beauty of Citus is that as far as your app is concerned, you're still running on top of Postgres. So if you decide to migrate from a single Postgres node to Citus, the good news is you don't have to re-architect your application. You can generally make the transition to Citus with minimal changes.[1] After all, an application running on Citus is still running on Postgres—just, distributed Postgres.
Why use a managed database service?
Why do so many people run their applications on top of a managed database service?
The primary reason is that by outsourcing database operations, you can focus your time on your application—in terms of new features, bug fixes, refactoring, and adding the kinds of capabilities that make your app more competitive.
I know it seems easy to set up a Postgres server, and it is. You can probably stand one up in 10 minutes or less. But setting up a resilient, production-ready Postgres server takes time and effort. "Production-ready" means you have to architect for backups, high availability, upgrades, hardware issues, security, and monitoring. And even if you have managed your own production Postgres server in the past—managing a distributed Citus cluster is a bit more complicated.
What do I mean? One example is backups. To manage your own backups in Postgres, you have to figure out where to back up to, how to make sure your backup storage is resilient, and how frequently you should backup to meet your RPO (Recovery Point Objective) and RTO (Recovery Time Objective)—and then you have to find a way to automate your backups, too. To manage backups in a distributed Citus cluster, you have to do even more, including making sure you have consistent versions of backups across all your Postgres nodes—hence, more complicated.
A managed database service can make all of this so much easier.
In addition to wanting to outsource the work of managing Postgres in production, another reason why teams use a managed service like Azure Database for PostgreSQL—is time.
Time is, after all, our scarcest resource. Think about it: if you're lucky, you have about 30K days on this planet.
I point this out because so often when people talk about the value of managed database services, the benefit of a PaaS that often gets overlooked is the opportunity cost. What else could you be doing with your time instead of managing database infrastructure?
Signs you could benefit from Hyperscale (Citus)
Ok, so now you know the primary reasons to scale out Postgres with Hyperscale (Citus) are 1) scale and 2) performance. Often both. But problems with performance and scale manifest in different ways depending on the nature of your workloads. So how do you know if you could benefit from Hyperscale (Citus)?
Here are the 7 signs we often see among teams adopting Hyperscale (Citus):
- Database Size is Big: Your database has gotten big, with 100+ GBs of data.[2]
- Application is Growing: Your application is growing fast in terms of things like number of users, amount of data, amount of concurrent activity, and rollout of new features in your application that add to the workload for your database. Or perhaps you are planning to grow 10X, so you want to prepare for scale now, in advance of the onslaught.
- Queries are Getting Slow: Your queries are taking longer and longer. Especially with concurrency. (Note: some of you might run into query performance problems even when you don't yet have a lot of data. This often happens if you have queries that are compute intensive.)
- Nearing Resource Limits of Single Node: Your database resources like memory, CPU, and disk IOPs are getting full—perhaps you're already on the 2nd largest box, starting to encroach on the limits of what a single Postgres node can do. Think about it: currently, the 2nd-largest Esv3 series VM on Azure has 48 cores with 384GB of memory. By instead provisioning just a 2-node Hyperscale (Citus) cluster with max cores, you can get a total of 128 cores and 864 GB of RAM—plus the ability to add more nodes to your Hyperscale (Citus) cluster when you need to, with zero downtime for the subsequent shard rebalancing.
- Affinity for Postgres: You love Postgres. Your team loves Postgres. Or maybe your team is already skilled with Postgres. We also see some users who stick with Postgres because of the Postgres extensions—such as PostGIS for geospatial use cases and HyperLogLog as an approximation algorithm.
- Want to buy, and not to build: You want your team to work on the features & capabilities of your application—not on sharding at the application layer, with all of its long-term maintenance costs and headaches.
- Want the Benefits of PaaS: You want to adopt a managed database service. And you don't want to manage hardware, backups, failures, resiliency, updates, upgrades, security, and scaling for a cluster of database servers. If you've checked some/many of the boxes above—then adopting Citus as part of a managed database service might be a good fit.
4 examples of common Hyperscale (Citus) use cases
You might be wondering: Is my use case a good fit for Hyperscale (Citus)? Here are 4 example use cases—not an exhaustive list, just a few examples—where Hyperscale (Citus) can help you to improve the scale and performance of your application.
One key characteristic for the first 3 of these use cases is that with Hyperscale (Citus) you can handle a mixture of both transactional & analytical workloads within the same database—at scale. To see how Hyperscale (Citus) performs for mixed workloads (sometimes called HTAP, or hybrid transactional analytical processing), check out this ~15 minute Hyperscale (Citus) demo. The demo uses the HammerDB benchmark to simulate a transactional workload and uses rollups to speed up analytics queries[3].
4 examples of use cases that are a fit for Hyperscale (Citus):
- Real-time operational analytics (including time series)
- Multi-tenant SaaS applications
- IOT workloads (that need UPDATEs & JOINs)
- High-throughput transactional apps
Real-time operational analytics (including time series)
One of our users described Citus as insanely fast for real-time analytics.
But what does that mean? When we talk about "real-time analytics", we're talking about applications that power customer-facing analytics dashboards. Some example applications include things like web and mobile analytics; behavioral analytics via funnel analysis and segmentation; anomaly and fraud detection; and geospatial analytics. The data being analyzed is generally event data or time series data; this time component is why some of these are also called "time series" use cases.
When I first started working with Citus, the key insight for me was to realize that the "customer-facing" aspect is what drives the "real-time" requirement of these dashboards. Because these analytics dashboards are customer-facing, and because the customers are not willing to wait for coffee (and certainly not overnight!) to get responses to their queries, the data needs to be ingested and made available in the dashboard for analysis in real-time. Or at least, in human real-time, which is usually single digit seconds, or sub-second, or even milliseconds.
Here's a quick checklist you can use to see if you have a real-time analytics workload that is a good fit for Hyperscale (Citus). If you check most of these boxes—not necessarily all, just most—then the answer is YES.
HYPERSCALE (CITUS) CHECKLIST FOR REAL-TIME OPERATIONAL ANALYTICS
- Interactive analytics dashboard: You have an interactive analytics dashboard that helps your users visualize and query data.
- Lots of concurrent activity: You have lots of users querying the dashboard at the same time (hence: concurrently.) And ingestion and querying are also concurrent—your users need to query the data while you're simultaneously ingesting new data in real-time.
- Demanding performance expectations: Your users need sub-second response times for queries (sometimes millisecond response times) even when handling hundreds of analytical queries per second.
- Data needs to be "fresh": This is the "real-time" bit. Your dashboard needs to continuously ingest and write new data (aka "fresh" data), often at very high throughput to keep up with a stream of events as they happen. Waiting a few days, overnight, or even a few minutes to query data is just not OK for your users.
- Large stream of data: Your dashboard needs to ingest and analyze a large stream of data, with millions of events (sometimes billions of events) per day.
- Event or time series data: Your data captures the many things that have happened (events) along with their associated timestamps, and you want to analyze the data. Some people call this event data, others call it time series data.
Notable customer stories from teams using Citus for analytics use cases
Helsinki Region Transport Authority: This technical story from the Helsinki Region Transport Authority (HSL) shows what scaling out Postgres horizontally with Hyperscale (Citus) can do. The team at HSL has a pretty interesting application that needed to log real-time location data for thousands of vehicles, match it with timetable data, and display it on a map—in order to enforce SLAs and make sure the people of Helsinki weren't stranded with unreliable service or unpredictable wait times.
Windows team at Microsoft: Another proof point? The story of the Windows team here at Microsoft who use Citus to scale out Postgres on Azure in order to assess the quality of upcoming Windows releases. The team's analytics dashboard runs on Citus database clusters with 44 nodes, tracking over 20K types of metrics from over 800M devices (and growing!), fielding over 6 million queries per day, with hundreds of concurrent users querying the dashboard at the same time.
Oh, and there is a comprehensive technical use case guide for real-time analytics dashboards you might find super useful.
Multi-tenant SaaS applications
Many Software as a Service (SaaS) applications are multi-tenant. And it turns out that multi-tenant applications can be a really good fit for sharding with Citus, because the customer ID (sometimes called the tenant_id, or account_id) makes for a natural distribution key.[4] The notion of tenancy is already built into your data model!
Multi-tenant data models generally require your database to keep all tenant data separate from each other. But if you're a SaaS provider, you often need to run queries across all the tenants, to understand the behavior of your application and what features are working well or not. Sharding your Postgres database with something like Hyperscale (Citus) gives you the best of both worlds: your customer's data is kept isolated from other customer data and yet you can still monitor/observe how your application is behaving across all of your customers's activities.
Here's a checklist to determine if your SaaS application is a good fit for Hyperscale (Citus). If you check most of these items (you don't need to check them all) then your SaaS app is likely a fit for Citus.
HYPERSCALE (CITUS) CHECKLIST FOR MULTI-TENANT SAAS:
- Tenants need to be kept separate: Your SaaS customers only need to read/write their own data and should not have access to data from your other SaaS customers.
- Application is growing fast: Your application is growing fast, in terms of number of users, size of database, or amount of activity—hence the number of monthly active users (MAU) or daily active users (DAU) is increasing.) More specifically, your database is 100s of GBs and growing, your SaaS app has 1000s of customers, you have 100,000+ users (or more.) But these numbers don't mean that Hyperscale (Citus) is only for large enterprise customers—rather, these numbers mean that Hyperscale (Citus) is for SaaS companies who need to scale, who need to manage growth.
- Performance issues, especially with concurrency: You're starting to run into performance issues during times with lots of concurrency. Perhaps you find yourself turning off some of your analytics features during peak workloads in order to ensure that critical customer transactions are handled right.
- Will soon hit resource limits of a single Postgres server: You're running on a single Postgres server today but it's the next-to-largest instance size—and you realize you will soon hit the resource limits of a single Postgres server.
- Need for cross-tenant queries: You don't want to give up the ability to run cross-tenant queries for internal monitoring purposes—therefore you don't want to start using multiple separate databases for different tenants, nor do you want to give up the ability to do JOINS by flipping to a NoSQL database system.
- Want to keep relational database semantics: You don't want to give up foreign keys for referential integrity, nor give up things like database constraints or secondary indexes. So the cost of migrating to a NoSQL data store to get scale is just not worth it to you.
If docs are what you're looking for, there is a comprehensive technical use case guide for Multi-tenant applications that should be useful to you.
IOT workloads (that need UPDATEs & JOINs)
It's been over 20 years since the term "Internet of Things" (IOT) became part of our lexicon. So long that it's hard to remember what the world was like before we had sensors everywhere, from doorbells to manufacturing lines to elevators to windmills.
Bottom line all these devices generate a ton of data these days, and all that data needs to be monitored and analyzed. Often with these IOT workloads, the sharding key (aka the distribution column in Citus) ends up being the device ID.
Some IOT applications focus only on the most up-to-date working state of each device (what is the current temperature? when was the last login?) Those IOT applications use UPDATEs in the database, where current state of things ("last known values") can be continuously updated. Other IOT applications need to store and query historic events (how many device failures happened in the last 3 hours?) and can use append-only databases.
Enabling your IOT application to query both historic events and the current working state of the device (how many failures happened when last known temperature was greater than 90 degrees?) makes for a powerful experience. That means your database needs to handle both updates and JOINs—between, say, your devices table and your events table. Some of the different types of IOT queries you might have:
- Aggregate queries, across devices: what's the total # of devices with a particular attribute or state?
- Activity queries for a device: get all the current and historical activity for a given device?
- Hierarchical queries: show all the disconnected devices in Building 7
- Geospatial queries: show all the devices within a given geographic fenced area?
Why Hyperscale (Citus) for these IOT workloads? Well, first because a relational database like Postgres gives you relational features such as JOINs. And, because Hyperscale (Citus) lets you ingest and query concurrently and at scale. If you've read through the other use cases in this post, then you probably see the pattern: by distributing Postgres across multiple servers, Hyperscale (Citus) enables you to parallelize your queries and take advantage of the combined compute, memory, and disk resources of all the servers in the Hyperscale (Citus) server group.
How do you know if your IOT application is a good fit for Hyperscale (Citus)? Here's a checklist you can start with:
HYPERSCALE (CITUS) CHECKLIST FOR IOT WORKLOADS:
- Large numbers of devices: we've seen customers with tens of thousands of devices, as well as millions of devices.
- Need real-time, high-throughput ingest: In order to manage what's going on with your fleet of devices, you need the data now. Which means you need a database that can ingest and write with high throughput and low-latency. Example: 2 billion measurements per hour, which equates to roughly ~500,000 measurements ingested per second.
- Need concurrency: You may have hundreds of users who need to run queries on this IOT data at the same time.
- Query response times in the single digit seconds—or milliseconds: Whether you are managing wind farms or manufacturing devices or fleets of smart meters, one sign that your IOT application could benefit from Hyperscale (Citus) is when your users need their query responses (on fresh data) in the single digit seconds or even in milliseconds. Now. Not in a half hour.
- Large database size: Is your database is 100 GB or more (and growing)? We see IOT customers with database sizes from hundreds of GBs to tens of TBs.
High-throughput transactional apps
Some transactional applications are so big in terms of the sheer amount of data, the number of transactions, and the performance expectations—that a single Postgres server cannot meet their needs. But these applications still need the consistency of transactions (not eventual consistency, but strong consistency.) We call these types of applications "high-throughput transactional applications" or "high-throughput OLTP." It's not a perfect name, I know—and truth be told some of our developers use a different name to describe this type of workload: "high-performance CRUD."
Because many of these workloads involve semi-structured data such as JSON—and because Postgres is well known for its JSON capabilities—these high-throughput transactional apps are a good fit for Postgres. Particularly now that Postgres can be distributed with Hyperscale (Citus).
What are the signs that your high-throughput transactional application might be a good fit for Hyperscale (Citus)? Here's a checklist. If you can check most of these boxes—not necessarily all, just some—then your app is likely a good fit.
HYPERSCALE (CITUS) CHECKLIST FOR HIGH-THROUGHPUT TRANSACTIONAL APPS:
- Primarily transactional application: Your app is primarily transactional in nature, with creates, reads, updates, and deletes—without the need for many complex queries.
- Semi-structured data like JSON: The objects you're managing are semi-structured formats like JSON (which Postgres has robust support for.)
- Single key: Your workload is mostly based on a single key, which you just have to create, read, update, and delete. (Therefore the majority of your transactions will only need to go to a single shard in the distributed Citus cluster.)
- High throughput: Your throughput requirements are demanding and cannot be met by a single database server, on the order of 1000s or 10s of thousands of transactions per second.
- Need relational database features: Some teams use NoSQL key-value stores for these types of semi-structured data-intensive workloads—but if you find yourself unwilling to go to NoSQL because there are relational database features you need, then Hyperscale (Citus) might be a good fit. Examples of key relational database features you might want to retain are strong consistency (not that eventual consistency compromise), foreign keys for referential integrity, triggers, and secondary indexes.
Is Hyperscale (Citus) a good fit for you & your application?
When it comes to delivering performance and scale to data-intensive apps, the phrase "it depends" is often bandied about. For good reason. There is no panacea, and it's always about tradeoffs. I'm hoping the walk through some of the Hyperscale (Citus) use cases—and the checklists—make it easier for you to answer the question of "when to use Hyperscale (Citus) to scale out Postgres?"
In summary, Hyperscale (Citus) gives you the performance and scalability superpowers of the Citus extension combined with all the PaaS benefits of a managed Postgres database service.
And if you're wondering when you should not use Hyperscale (Citus), well, there are definitely situations where Hyperscale (Citus) is not a fit. The most obvious scenario is when a single Postgres server is sufficient to meet the needs of your application, i.e. when your database fits in memory, performance is snappy, and you're not faced with the challenges of growth. Another scenario that is not a fit: offline data warehousing—where you run batch offline data loads with lots of complex and custom analytics queries, where you need to analyze TBs of data in a single query, where your data model is not very sharding friendly because you have so many different types of tables and no two tables use the same key. Another scenario where Hyperscale (Citus) is not a fit: where your analytics app doesn't need to support concurrency.
So if Postgres is your poison and you need more performance and scale than you can eek out of a single Postgres server, you should consider Hyperscale (Citus). Especially if your application is a real-time analytics dashboard, multi-tenant SaaS application, IOT application, or high-throughput OLTP app.
Ways to learn more about Hyperscale (Citus)
To figure out if Hyperscale (Citus) on Azure Database for PostgreSQL is right for you and your app, here are some ways to roll up your sleeves and get started. Since many of you have different learning modes, I'm including a mix of doing, reading, and watching options below. Pick what works best for you!
- Download Citus open source packages to try it out locally
- Read the Citus open source docs at docs.citusdata.com, especially:
- Try some tutorials for multi-tenant SaaS and real-time analytics dashboards.
- Watch this ~15 min Hyperscale (Citus) demo from SIGMOD about scaling out Postgres to achieve high performance transactions & analytics
- Create a Hyperscale (Citus) server group on Azure Database for PostgreSQL to try it out. (And if you don't yet have an Azure subscription, just create a free Azure account first.)
Oh, and if you want to stay connected, you can follow our @AzureCosmosDB and @citusdata accounts on Twitter. Plus, we ship a monthly technical Citus Newsletter to our open source community. It's pretty useful. Here's an archive of past Citus Newsletters: you can sign up here, too.
If you need help figuring out whether Citus on Azure is a good fit for your workload, you can always reach out to our Citus on Azure product team—the team that helped to create Citus on Azure—via email at Ask Azure Cosmos DB. We'd love to hear from you. :)

Footnotes
- To distribute Postgres with Citus, there are 2 primary things you need to take care of up front: a) decide on your sharding strategy i.e. what your distribution column will be, and b) make changes to implement that sharding strategy, which could involve updating some of your tables to add the sharding/distribution key on some tables, or could involve deciding which tables to distribute and which tables should become reference tables, or perhaps changing some foreign keys. YMMV but for many people, the amount of change is minimal—and the amount of change is substantially less than trying to shard at the application layer. ↩
- What constitutes a large database size for you may not be large for another application. Your mileage may vary. Sometimes even small’ish Postgres databases have such compute-intensive queries that they outgrow the resources of even the beefiest Postgres servers. ↩
- Marco Slot (lead of our Citus engineering team) created the demo and I did all the video editing on the demo bits, so I can vouch for the usefulness of this Hyperscale (Citus) demo. ↩
- There are a few different names for this puppy. Distribution key, distribution column, sharding key—they all refer to the same thing. Choosing the distribution column is one of the most important decisions you make when you decide to distribute Postgres with Citus, because the distribution column determines how Citus will distribute the data (how Citus will shard the data) across nodes in the cluster. ↩
