📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
For those considering Citus, if your use case seems like a good fit, we often are willing to spend some time with you to help you get an understanding of the Citus database and what type of performance it can deliver. We commonly do this in a roughly two hour pairing session with one of our engineers. We'll talk through the schema, load up some data, and run some queries. If we have time at the end it is always fun to load up the same data and queries into single node Postgres and see how we compare. After seeing this for years, I still enjoy seeing performance speed ups of 10 and 20x over a single node database, and in cases as high as 100x.
And the best part is it didn't take heavy re-architecting of data pipelines. All it takes is just some data modeling, and parallelization with Citus.
The first step is sharding
We've talked about this before but the first key to these performance gains is that Citus splits up your data under the covers to smaller more manageable pieces. These are shards (which are standard Postgres tables) are spread across multiple physical nodes. This means that you have more collective horsepower within your system to pull from. When you're targetting a single shard it is pretty simple: the query is re-routed to the underlying data and once it gets results it returns them.
Thinking in MapReduce
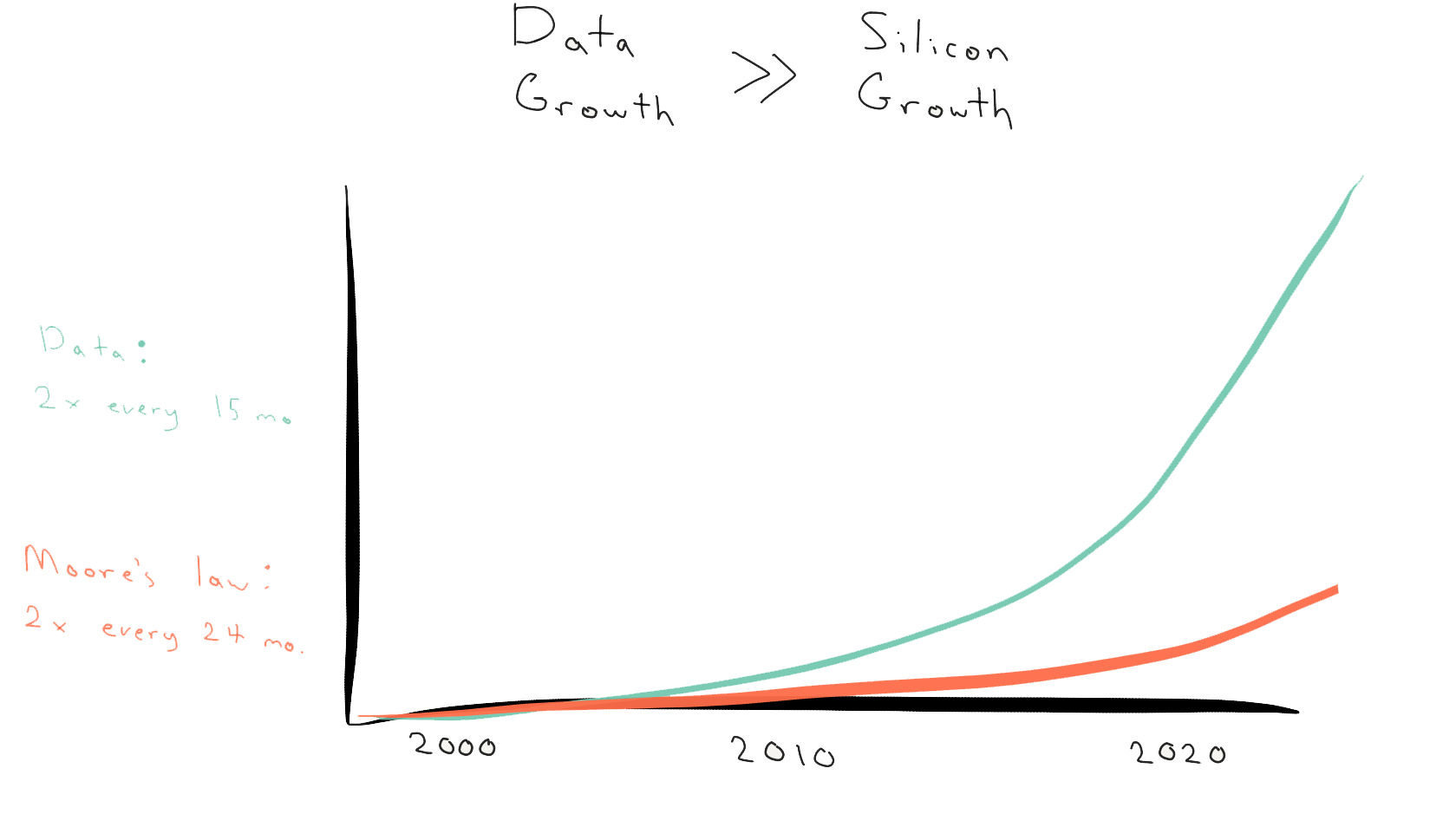
MapReduce has been around for a number of years now, and was popularized by Hadoop. The thing about large scale data is in order to get timely answers from it you need to divide up the problem and operate in parallel. Or you find an extremely fast system. The problem with getting a bigger and faster box is that data growth is outpacing hardware improvements.
MapReduce itself is a framework for splitting up data, shuffling the data to nodes as needed, and then performing the work on a subset of data before recombining for the result. Let's take an example like counting up total pageviews. If we wanted leverage MapReduce on this we would split the pageviews into 4 separate buckets. We could do this like:
for i = 1 to 4:
for page in pageview:
bucket[i].append(page)
Now we would have 4 buckets each with a set of pageviews. From here we could perform a number of operations, such as searching to find the 10 most recent in each bucket, or counting up the pageviews in each bucket:
for i = 1 to 4:
for page in bucket:
bucket_count[i]++
Now by combining the results we have the total number of page views. If we were to farm out the work to four different nodes we could see a roughly 4x performance improvement over using all the compute of one node to perform the count.
MapReduce as a concept
MapReduce is well known within the Hadoop ecosystem, but you don't have to jump into Java to leverage. Citus itself has multiple different executors for various workloads, our real-time executor is essentially synonomous with being a MapReduce executor.
If you have 32 shards within Citus and run SELECT count(*) we split it up and run multiple counts then aggregate the final result on the coordinator. But you can do a lot more than count (*), what about average. For average we get the sum from all the nodes and the counts. Then we add together the sums and counts and do the final math on the coordinator, or you could average together the average from each node. Effectively it is:
SELECT avg(page), day
FROM pageviews_shard_1
GROUP BY day;
average | date
---------+----------
2 | 1/1/2019
4 | 1/2/2019
(2 rows)
SELECT avg(page), day
FROM pageviews_shard_2
GROUP BY day;
average | date
---------+----------
8 | 1/1/2019
2 | 1/2/2019
(2 rows)
When we feed the above results into a table then average them we get:
average | date
---------+----------
5 | 1/1/2019
3 | 1/2/2019
(2 rows)
Note within Citus you don't actually have to run multiple queries. Under the covers our real-time executor just handles it, it really is as simple as running:
SELECT avg(page), day
FROM pageviews
GROUP BY day;
average | date
---------+----------
5 | 1/1/2019
3 | 1/2/2019
(2 rows)
For large datasets thinking in MapReduce gives you a path to get great performance without Herculean effort. And the best part may be that you don't have to write 100s of lines to accomplish it, you can do it with the same SQL you're used to writing. Under the covers we take care of the heavy lifting, but it is nice to know how it works under the covers.