📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
This post by Postgres committer Andres Freund about analyzing Postgres connection scalability was originally published on the Azure Database for PostgreSQL Blog on Microsoft TechCommunity.
One common challenge with Postgres for those of you who manage busy Postgres databases, and those of you who foresee being in that situation, is that Postgres does not handle large numbers of connections particularly well.
While it is possible to have a few thousand established connections without running into problems, there are some real and hard-to-avoid problems.
Since joining Microsoft last year in the Azure Database for PostgreSQL team—where I work on open source Postgres—I have spent a lot of time analyzing and addressing some of the issues with connection scalability in Postgres.
In this post I will explain why I think it is important to improve Postgres' handling of large number of connections. Followed by an analysis of the different limiting aspects to connection scalability in Postgres.
In an upcoming post, I will show the results of the work we’ve done to improve connection handling and snapshot scalability in Postgres—and go into detail about the identified issues and how we have addressed them in Postgres 14.
- Why connection scalability in Postgres is important
- Surveying connection scalability issues
- Memory usage
- Constant connection overhead
- Cache bloat
- Query memory usage
- Snapshot scalability
- Connection model & context switches
- Conclusion: Start by improving snapshot scalability in Postgres
Why connection scalability in Postgres is important
In some cases problems around connection scalability are caused by unfamiliarity with Postgres, broken applications, or other issues in the same vein. And as I already mentioned, some applications can have a few thousand established connections without running into any problems.
A frequent counter-claim to requests to improve Postgres' handling of large numbers of connection counts is that there is nothing to address. That the desire/need to handle large numbers of connection is misguided, caused by broken applications or similar. Often accompanied by references to the server only having a limited number of CPU cores.
There certainly are cases where the best approach is to avoid large numbers of connections, but there are—in my opinion—pretty clear reasons for needing larger number of connections in Postgres. Here are the main ones:
Central state and spikey load require large numbers of connections: It is common for a database to be the shared state for an application (leaving non-durable caching services aside). Given the cost of establishing a new database connection (TLS, latency, and Postgres costs, in that order) it is obvious that applications need to maintain pools of Postgres connections that are large enough to handle the inevitable minor spikes in incoming requests. Often there are many servers running [web-]application code using one centralized database.
To some degree this issue can be addressed using Postgres connection poolers like PgBouncer or more recently Odyssey. To actually reduce the number of connections to the database server such poolers need to be used in transaction (or statement) pooling modes. However, doing so precludes the use of many useful database features like prepared statements, temporary tables, …
Latency and result processing times lead to idle connections: Network latency and application processing times will often result in individual database connections being idle the majority of the time, even when the applications are issuing database requests as fast as they can.
Common OLTP database workloads, and especially web applications, are heavily biased towards reads. And with OLTP workloads, the majority of SQL queries are simple enough to be processed well below the network latency between application and database.
Additionally the application needs to process the results of the database queries it sent. That often will involve substantial work (e.g. template processing, communication with cache servers, …).
To drive this home, here is a simple experiment using pgbench (a simple benchmarking program that is part of Postgres). In a memory-resident, read-only pgbench workload (executed on my workstation1, 20/40 CPU cores/threads) I am comparing the achievable throughput across increasing client counts between a non-delayed pgbench and a pgbench with simulated delays. For the simulated delays, I used a 1ms network delay and a 1ms processing delay. The non-delayed pgbench peaks around 48 clients, the delayed run around 3000 connections. Even comparing on-machine TCP connections to a 10GBe between two physically close machines moves the peak from around 48 connections closer to 500 connections.
Scaling out to allow for higher connection counts can increase cost: Even in cases where the application's workload can be distributed over a number of Postgres instances, the impact of latency combined with low maximum connection limits will often result in low utilization of the database servers, while exerting pressure to increase the number of database servers to handle the required number of connections. That can increase the operational costs substantially.
Surveying connection scalability issues
My goal in starting this project was to improve Postgres' ability to handle substantially larger numbers of connections. To do that—to pick the right problem to solve—I first needed to understand which problems were most important, otherwise it would have been easy to end up with micro-optimizations without improving real-world workloads.
So my first software engineering task was to survey the different aspects of connection scalability limitations in Postgres, specifically:
By the end of this deep dive into the connection scalability limitations in Postgres, I hope you will understand why I concluded that snapshot scalability should be addressed first.
Memory usage
There are 3 main aspects to problems around memory usage of a large numbers of connections:
- Constant connection overhead, the amount of memory an established connection uses
- Cache bloat, the increase in memory usage due to large numbers of database objects
- Query memory usage, memory used by query execution itself
Constant connection overhead
Postgres, as many of you will know, uses a process-based connection model. When a new connection is established, Postgres' supervisor process creates a dedicated process to handle that connection going forward. The use of a "full blown process" over the use of of threads has some advantages like increased isolation/robustness, but also some disadvantages.
One common complaint is that each connection uses too much memory. That is, at least partially, a common observation because it is surprisingly hard to measure the increase in memory usage by an additional connection.
In a recent post about measuring the memory overhead of a Postgres connection I show that it is surprisingly hard to accurately measure the memory overhead. And that in many workloads, and with the right configuration—most importantly, using huge_pages—the memory overhead of each connection is below 2 MiB.
Conclusion: connection memory overhead is acceptable
When each connection only has an overhead of a few MiB, it is quite possible to have thousands of established connections. It would obviously be good to use less memory, but memory is not the primary issue around connection scalability.
Cache bloat
Another important aspect of memory-related connection scalability issues can be that, over time, the memory usage of a connection increases, due to long-lived resources. This particularly is an issue in workloads that utilize long-lived connections combined with schema-based multi-tenancy.
Unless applications implement some form of connection <-> tenant association, each connection over time will access all relations for all tenants. That leads to Postgres' internal catalog metadata caches growing beyond a reasonable size, as currently (as of version 13) Postgres does not prune its metadata caches of unchanging rarely-accessed contents.
Problem illustration
To demonstrate the issue of cache bloat, I created a simple test bed with 100k tables, with a few columns and single primary serial column index2. Takes a while to create.
With the recently added pg_backend_memory_contexts view it is not too difficult to see the aggregated memory usage of the various caches (although it would be nice to see more of the different types of caches broken out into their own memory contexts). See 3.
In a new Postgres connection, not much memory is used:
| name | parent | size_bytes | size_human | num_contexts |
|---|---|---|---|---|
| CacheMemoryContext | TopMemoryContext | 524288 | 512 kB | 1 |
| index info | CacheMemoryContext | 149504 | 146 kB | 80 |
| relation rules | CacheMemoryContext | 8192 | 8192 bytes | 1 |
But after forcing all Postgres tables we just created to be accessed4, this looks very different:
| name | parent | size_bytes | size_human | num_contexts |
|---|---|---|---|---|
| CacheMemoryContext | TopMemoryContext | 621805848 | 593 MB | 1 |
| index info | CacheMemoryContext | 102560768 | 98 MB | 100084 |
| relation rules | CacheMemoryContext | 8192 | 8192 bytes | 1 |
As the metadata cache for indexes is created in its own memory context, num_contexts for the "index info" contexts nicely shows that we accessed the 100k tables (and some system internal ones).
Conclusion: cache bloat is not the major issue at this moment
A common solution for the cache bloat issue is to drop "old" connections from the application connection pooler after a certain age. Many connection pooler libraries/web frameworks support that.
As there is a feasible workaround, and as cache bloat is only an issue for databases with a lot of objects, cache bloat is not the major issue at the moment (but worthy of improvement, obviously).
Query memory usage
The third aspect is that it is hard to limit memory used by queries. The work_mem setting does not control the memory used by a query as a whole, but only of individual parts of a query (e.g. sort, hash aggregation, hash join). That means that a query can end up requiring work_mem several times over5.
That means that one has to be careful setting work_mem in workloads requiring a lot of connections. With larger work_mem settings, practically required for analytics workloads, one can't reasonably use a huge number of concurrent connections and expect to never hit memory exhaustion related issues (i.e. errors or the OOM killer).
Luckily most workloads requiring a lot of connection don't need a high work_mem setting, and it can be set on the user, database, connection, and transaction level.
Snapshot scalability
There are a lot of recommendations out there strongly recommending to not set max_connections for Postgres to a high value, as high values can cause problems. In fact, I've argued that myself many times.
But that is only half the truth.
Setting max_connections to a very high value alone only leads at best (worst?) to a very small slowdown in itself, and wastes some memory. E.g. on my workstation1 there is no measurable performance difference for a read-only pgbench between max_connections=100 and a value as extreme max_connections=100000 (for the same pgbench client count, 48 in this case). However the memory required for Postgres does increase measurable with such an extreme setting. With shared_buffers=16GB max_connections=100 uses 16804 MiB, max_connections=100000 uses 21463 MiB of shared memory. That is a large enough difference to potentially cause a slowdown indirectly (although most of that memory will never be used, therefore not allocated by the OS in common configurations).
The real issue is that currently Postgres does not scale well to having a large number of established connections, even if nearly all connections are idle.
To showcase this, I used two separate pgbench6 runs. One of them just establishes connections that are entirely idle (using a test file that just contains \sleep 1s, causing a client-side sleep). Another to run a normal pgbench read-only workload.
This is far from reproducing the worst possible version of the issue, as normally the set of idle connections varies over time, which makes this issue considerably worse. This version is much easier to reproduce however.
This is a very useful scenario to test, because it allows us to isolate the cost of additional connections pretty well isolated. Especially when the count of active connections is low, the system CPU usage is quite low. If there is a slowdown when the number of idle connections increases, it is clearly related to the number of idle connections.
If we instead measured the throughput with a high number of active connections, it'd be harder to pinpoint whether e.g. the increase in context switches or lack of CPU cycles is to blame for slowdowns.
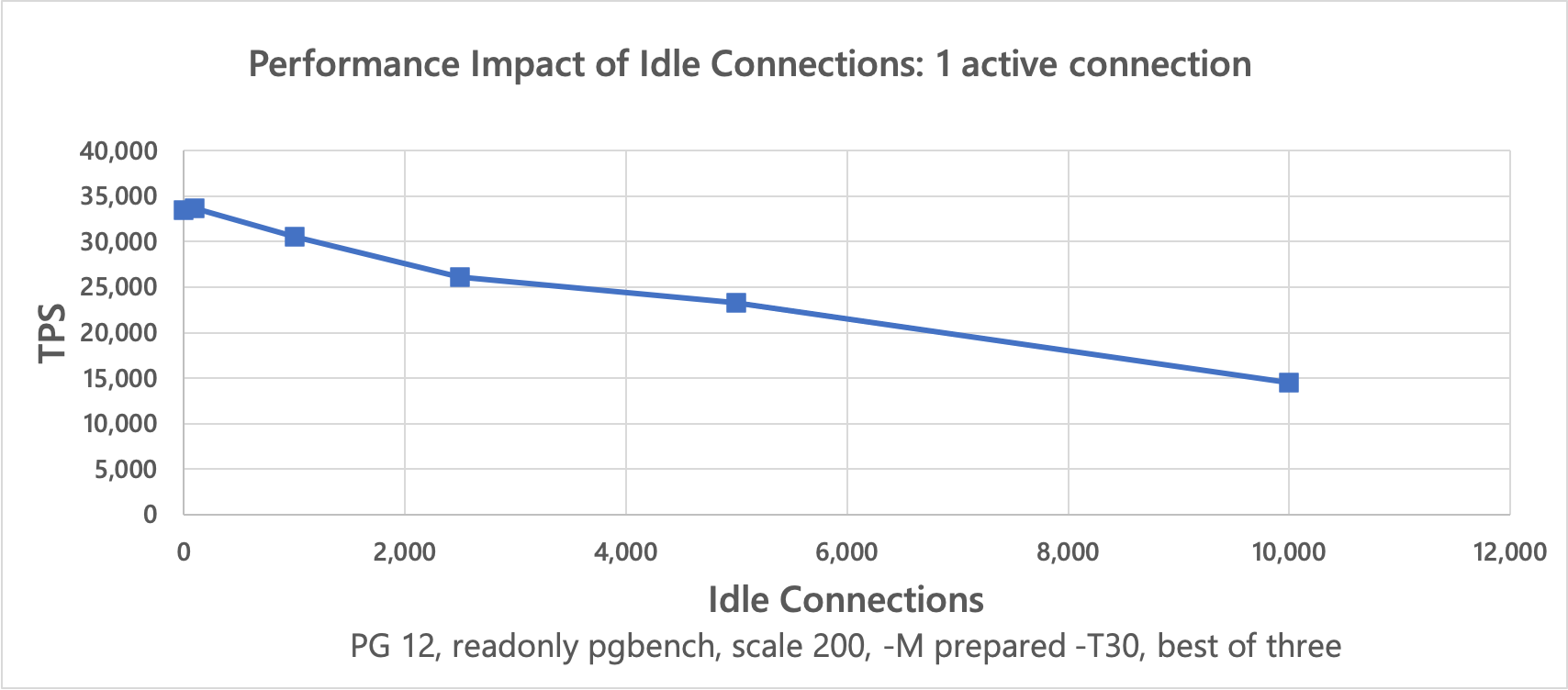
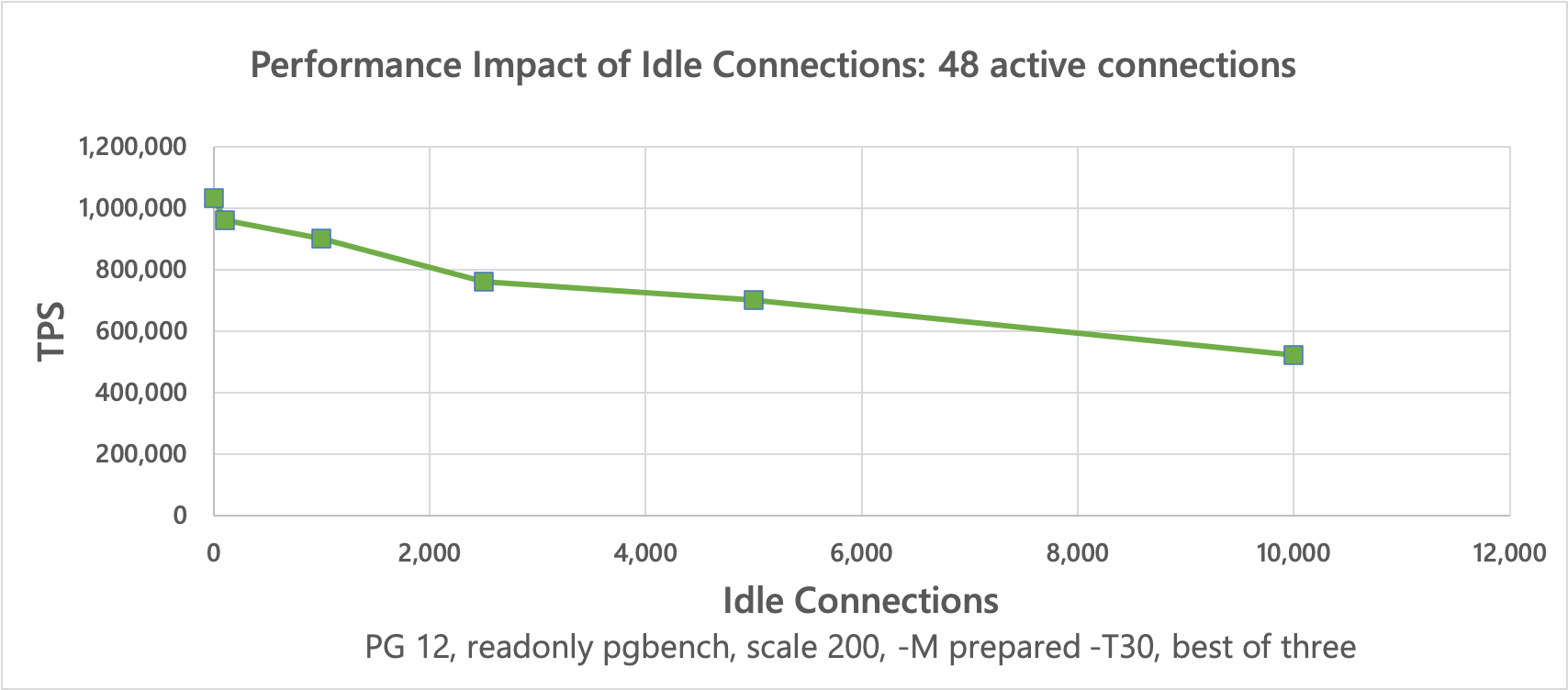
These results7 clearly show that the achievable throughput of active connections decreases significantly when the number of idle connections increases.
In reality "idle" connections are not entirely idle, but send queries at a lower rate. To simulate that I've used the the below to simulate clients only occasionally sending queries:
\sleep 100ms
SELECT 1;
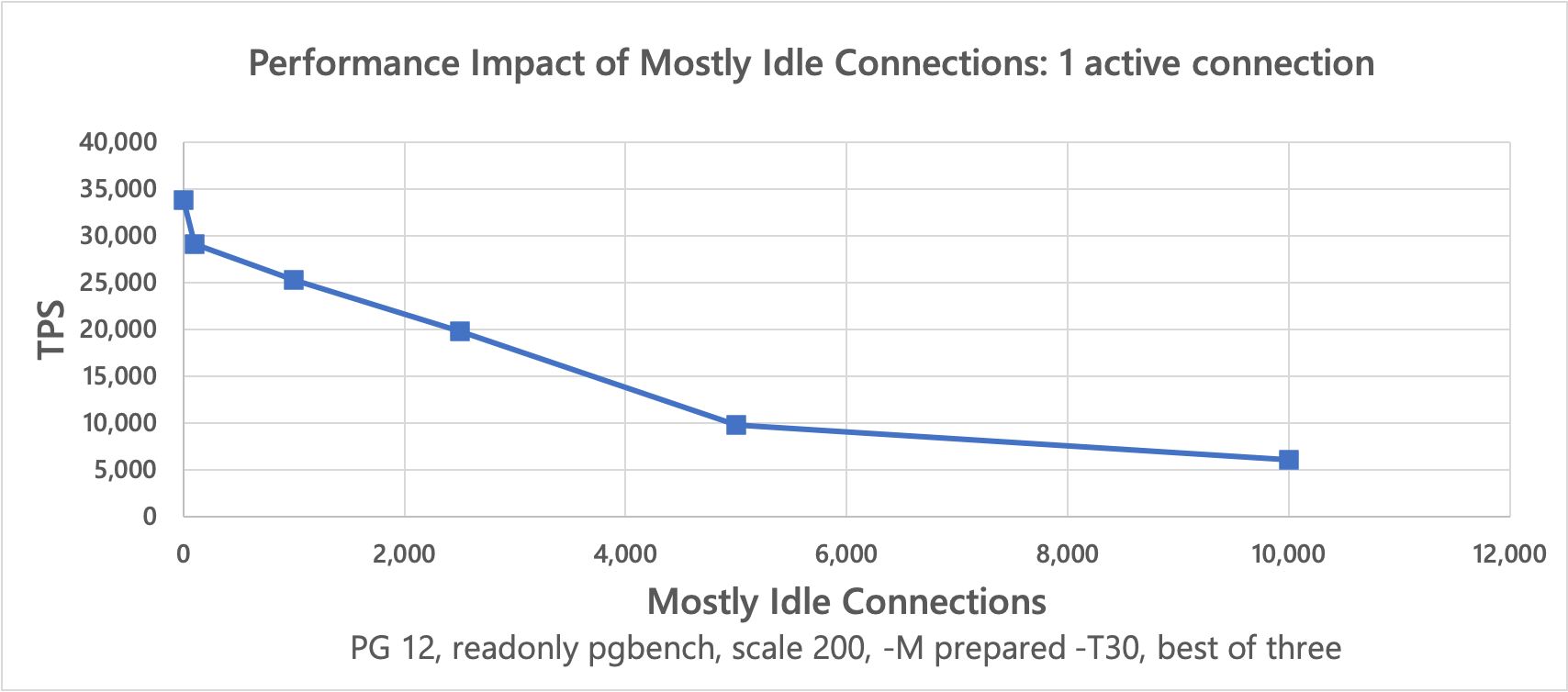
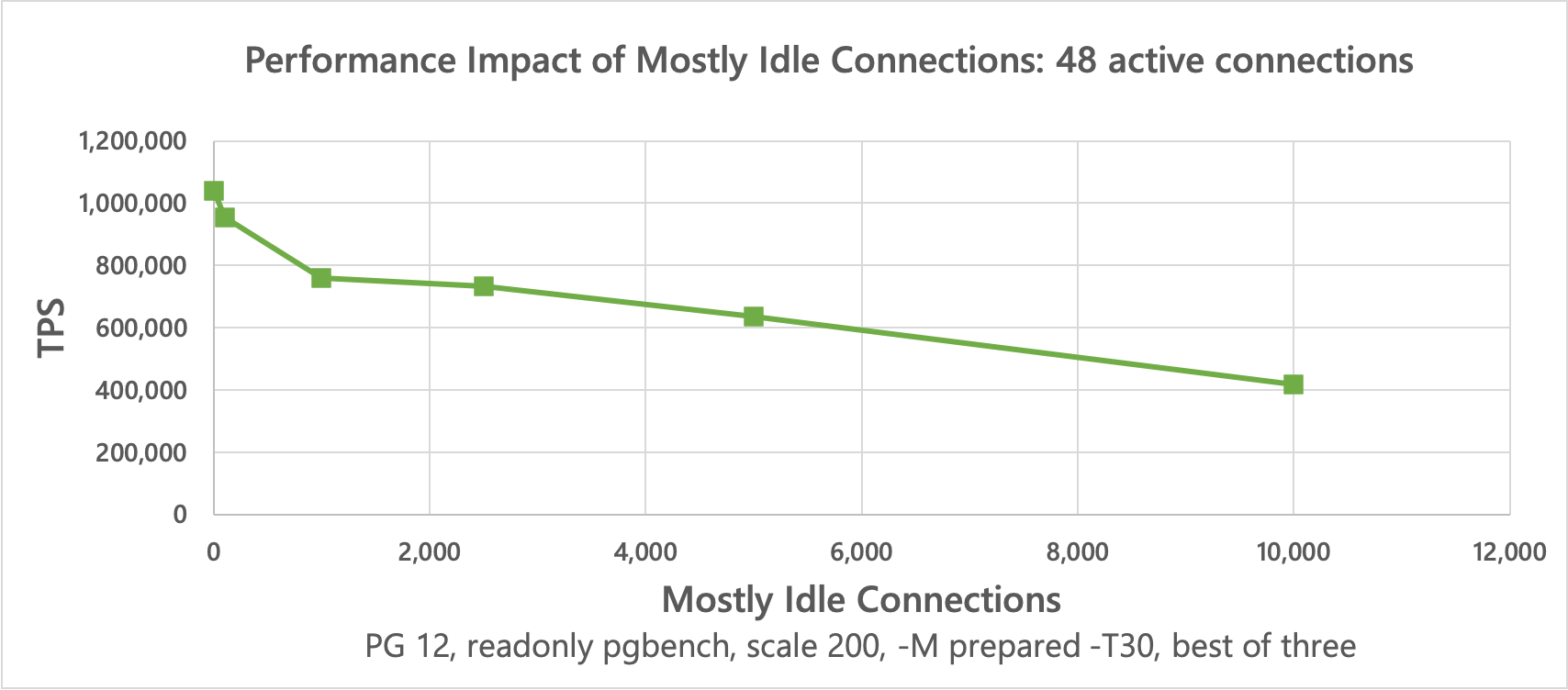
The results8 show that the slightly more realistic scenario causes active connections to slow down even worse.
Cause
Together these results very clearly show that there is a significant issue handling large connection counts, even when CPU/memory are plentiful. The fact that a single active connection slows down by more than 2x due to concurrent idle connections points to a very clear issue.
A CPU profile quickly pinpoints the part of Postgres responsible: 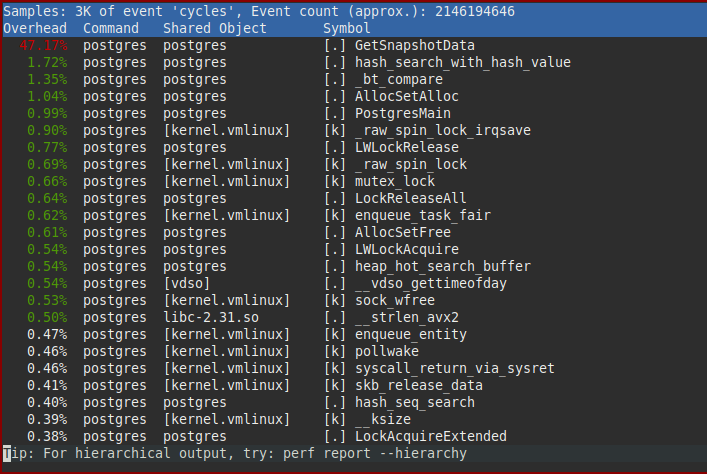
GetSnapshotData()
Obviously the bottleneck is entirely in the GetSnapshotData() function. That function performs the bulk of the work necessary to provide readers with transaction isolation. GetSnapshotData() builds so called "snapshots" that describe which effects of concurrent transactions are visible to a transaction, and which are not. These snapshots are built very frequently (at least once per transaction, very commonly more often).
Even without knowing its implementation, it does make some intuitive sense (at least I think so, but I also know what it does) that such a task gets more expensive the more connections/transactions need to be handled.
Two blog posts by Brandur explain the mechanics and issues surrounding this in more detail: - How Postgres Makes Transactions Atomic - How to Manage Connections Efficiently in Postgres, or Any Database
Conclusion: Snapshot scalability is a significant limit
A large number of connections clearly reduce the efficiency of other connections, even when idle (which as explained above, is very common). Except for reducing the number of concurrent connections and issuing fewer queries, there is no real workaround for the snapshot scalability issue.
Connection model & context switches
As mentioned above, Postgres uses a one-process-per-connection model. That works well in a lot of cases, but is a limiting factor for dealing with 10s to 100s of thousands of connections.
Whenever a query is received by a backend process, the kernel needs to perform a context switch to that process. That is not cheap. But more importantly, once the result for the query has been computed, the backend will commonly be idle for a while—the query result has to traverse the network, be received and processed by the application, before the application sends a new query. That means on a busy server another process/backend/connection will need to be scheduled—another context switch (cross-process context switches are more expensive than doing process-kernel-same process, e.g. as part of a syscall).
Note that switching to a one-thread-per-connection model does not address this issue to a meaningful degree: while some of the context switches may get cheaper, context switches still are the major limit. There are reasons to consider switching to threads, but connection scalability itself is not a major one (without additional architectural changes, some of which may be easier using threads).
To handle huge numbers of connections a different type of connection model is needed. Instead of using a process/thread-per-connection model, a fixed/limited number of processes/threads need to handle all connections. By waiting for incoming queries on many connections at once and then processing many queries without being interrupted by the OS CPU scheduler, efficiency can very significantly be improved.
This is not a brilliant insight by me. Architectures like this are in wide use, and have widely been discussed. See e.g. the C10k problem, coined in 1999.
Besides avoiding context switches, there are many other performance benefits that can be gained. E.g. on higher core count machines, a lot of performance can be gained by increasing locality of shared memory, e.g. by binding specific processes/threads and regions of memory to specific CPU cores.
However, changing Postgres to support a different kind of connection model like this is a huge undertaking. That does not just require carefully separating many dependencies between processes and connections, but also user-land scheduling between different queries, support for asynchronous IO, likely a different query execution model (to avoid needing a separate stack for each query), and much more.
Conclusion: Start by improving snapshot scalability in Postgres
In my opinion, the memory usage issues are not as severe as the other issues discussed. Partially because the memory overhead of connections is less big than it initially appears, and partially because issues like Postgres' caches using too much memory can be worked around reasonably.
We could, and should, make improvements around memory usage in Postgres, and there are several low enough hanging fruits. But I don't think, as things currently are, that improving memory usage would, on its own, change the picture around connection scalability, at least not on a fundamental level.
In contrast, there is no good way to work around the snapshot scalability issues. Reducing the number of established connections significantly is often not feasible, as explained above. There aren't really any other workarounds.
Additionally, as the snapshot scalability issue is very localized, it is quite feasible to tackle it. There are no fundamental paradigm shifts necessary.
Lastly, there is the aspect of wanting to handle many tens of thousands of connections, likely by entirely switching the connection model. As outlined, that is a huge project/fundamental paradigm shift. That doesn't mean it should not be tackled, obviously.
Addressing the snapshot scalability issue first thus seems worthwhile, promising significant benefits on its own.
But there's also a more fundamental reason for tackling snapshot scalability first: While e.g. addressing some memory usage issues at the same time, switching the connection model would not at all address the snapshot issue. We would obviously still need to provide isolation between the connections, even if a connection wouldn't have a dedicated process anymore.
Hopefully now you understand why I chose to focus on Postgres snapshot scalability first. More about that in my next blog post on improving Postgres connection scalability.
Footnotes
- 2x xeon gold 5215, 192GiB of RAM, kernel 5.8.5, debian Sid ↩︎
Creating 100k tables with psql:
↩︎postgres[2627319][1]=# SELECT format('begin;create table foo_%1s(id serial primary key, data1 int, data2 text, data3 json);commit;', g.i) FROM generate_series(1, 100000) g(i) \gexec COMMIT COMMIT …Query cache memory usage:
↩︎WITH RECURSIVE contexts AS ( SELECT * FROM pg_backend_memory_contexts), caches AS ( SELECT * FROM contexts WHERE name = 'CacheMemoryContext' UNION ALL SELECT contexts.* FROM caches JOIN contexts ON (contexts.parent = caches.name) ) SELECT name, parent, sum(total_bytes) size_bytes, pg_size_pretty(sum(total_bytes)) size_human, count(*) AS num_contexts FROM caches GROUP BY name, parent ORDER BY SUM(total_bytes) DESC;Query to access all tables named
foo*:
↩︎DO $$ DECLARE cnt int := 0; v record; BEGIN FOR v IN SELECT * FROM pg_class WHERE relkind = 'r' and relname LIKE 'foo%' LOOP EXECUTE format('SELECT count(*) FROM %s', v.oid::regclass::text); cnt = cnt + 1; IF cnt % 100 = 0 THEN COMMIT; END IF; END LOOP; RAISE NOTICE 'tables %1', cnt; END;$$;Even worse, there can also be several queries in progress at the same time, e.g. due to the use of cursors. It is however not common to concurrently use many cursors. ↩︎
This is with pgbench modified to wait until all connections are established. Without that pgbench modification, sometimes a subset of clients may not be able to connect, particularly before the fixes described in this article. See this mailing listpost for details. ↩︎
Idle Connections vs Active Connections:
↩︎PG Version Idle Connections Active Connections TPS 12 0 1 33457 12 100 1 33705 12 1000 1 30558 12 2500 1 26075 12 5000 1 23284 12 10000 1 14496 12 0 48 1032435 12 100 48 960847 12 1000 48 902109 12 2500 48 759723 12 5000 48 702680 12 10000 48 521558 Mostly Idle Connections vs Active Connections:
↩︎PG Version Less active Connections Active Connections TPS 12 0 1 33773 12 100 1 29074 12 1000 1 25327 12 2500 1 19752 12 5000 1 9807 12 10000 1 6049 12 0 48 1040616 12 100 48 953755 12 1000 48 759366 12 2500 48 733000 12 5000 48 636057 12 10000 48 416819 