The schedule is out 🗓️ for POSETTE: An Event for Postgres 2026!
Today, we’re excited to announce the latest release of our distributed database, Citus 7.4! Citus scales out PostgreSQL through sharding, replication, and query parallelization.
Ever since we open sourced Citus as a Postgres extension, we have been incorporating your feedback into our database. Over the past two years, our release cycles went down from six to four to two months. As a result, we have announced 10 new Citus releases, where each release came with notable new features.
Shorter release cycles and more features came at a cost however. In particular, we added new distributed planner and executor logic to support different use cases for multi-tenant applications and real-time analytics. However, we couldn’t find the time to refactor this new logic. We found ourselves accumulating technical debt. Further, our distributed SQL coverage expanded over the past two years. With each year, we ended spending more and more time on testing each new release.
In Citus 7.4, we focused on reducing technical debt related to these items. At Citus, we track our development velocity with each release. While we fix bugs in every release, we found that a full release focused on addressing technical debt would help to maintain our release velocity. Also, a cleaner codebase leads to a happier and more productive engineering team.
Refactoring distributed query planners in Citus
When you shard a relational database, you’re taking diverse features built over decades and applying them onto a distributed system. The challenge here is that these diverse features were built with a single machine in mind. This means cpu, memory, and disk. When you take any of these features, and execute them over a distributed system, you have a new bottleneck: the network.
So how do handle these diverse features in a distributed environment? To accommodate for these differences, Citus uses a “layered approach” to planning. When a query comes into the database, Citus picks the most efficient planner among four different planners. You can learn more about Citus planners from a talk Marco delivered recently at PGConf US.
| Citus Planner | Use Case |
|---|---|
| Router planner | Multi-tenant (B2B) / OLTP |
| Pushdown planner | Real-time analytics / search |
| Recursive (subquery/CTE) planner | Real-time analytics / data warehouse |
| Logical planner | Data warehouse |
In this diagram, the four planners look cleanly separated. In practice, we added new features that make use of these planners over time. As a result, we ended up having features that leaked between the four distributed planner layers. For example, if you wanted to insert a single row, it was easy to route that request to the proper shard. Similarly, if you wanted to execute an analytics query, Citus would easily pick the appropriate planner. Citus would then plan the query for distributed execution and push down the work to related shards.
What happens when you have a query that both updates rows and also analyzes them? For these types of queries, Citus planning logic would leak between the four planner types.
UPDATE accounts
SET dept = select_query.max_dept * 2
FROM
(
SELECT DISTINCT ON (tenant_id) tenant_id, max(dept) as max_dept FROM
(
SELECT accounts.dept, accounts.tenant_id
FROM accounts, company
WHERE company.tenant_id = accounts.tenant_id
) select_query_inner
GROUP BY tenant_id
ORDER BY 1 DESC
) as select_query
WHERE
select_query.tenant_id != accounts.tenant_id
AND accounts.dept IN (2)
RETURNING
accounts.tenant_id, accounts.dept;
In Citus 7.4, we refactored our planning logic for DML statements (INSERT, UPDATE, DELETE) that included SELECT statements within them. This refactoring both increased the type of statements Citus could handle. It also reduced dependencies between the different planner components, enabling us to make changes to each planner in the future easier.
Complex bugs due to incremental changes / code duplication
As Citus expanded into new workloads, we added new planner components to meet new requirements. At the same time, Citus also notably expanded its SQL coverage for analytical workloads.
Since Citus 5, we added new features mostly as incremental changes to existing planner code. Sometimes, we made these changes in short notice because they ended up being critical for a customer.
As we went through our release testing, we found that these incremental features worked well in isolation. However, they could lead to bugs when used in combination.
For example, the following query didn’t pass our acceptance tests. Part of the issue with this query was how Citus handled the combination of DISTINCT ON clauses, aggregate and window functions, window functions in the ORDER BY clause, HAVING clause, and a LIMIT clause.
SELECT
DISTINCT ON (AVG(value_1) OVER (PARTITION BY user_id)) user_id,
AVG(value_2) OVER (PARTITION BY user_id)
FROM
users_table
GROUP BY
user_id, value_1, value_2
HAVING count(*) = 1
ORDER BY
(AVG(value_1) OVER (PARTITION BY user_id)), 2 DESC, 1
LIMIT
100;
Another part of the issue was that Citus handled the SQL features in this query across two planner components. Depending on the sharding key, Citus would decide which parts of the query it could push down to the machines in the cluster. This lead to code duplication and complex interactions between the planner components.
In Citus 7.4, we refactored the distributed query planner to remove these issues. As part of this change, we moved all the logic related to executing the above analytical clauses into one place. In the process, we removed code that ended up being duplicated across different components. Last, we made the dependencies between the above clauses explicit. This way, as we add new clauses that come with new Postgres clauses, we’ll have a faster and easier time integrating them.
Features that became obsolete with new requirements
Citus’ early versions primarily targeted analytical workloads. In these workloads, users would shard their large tables. For the small tables, Citus would take a more dynamic approach. When the user issued an analytical query, Citus would then broadcast this small table’s data to all the machines in the cluster. We referred to this operation as broadcast joins.
Broadcast joins worked well for customers who loaded their data in batches and at regular intervals. However, as we had more customers who needed to update these tables in real-time, the notion of a broadcast join became problematic. We first tried to mitigate this problem by introducing smarter caching of shards for broadcast joins.
During our Citus 6 release, we realized that broadcast joins were no longer tenable. So, we deprecated broadcast joins in favor of reference tables. With reference tables, the user would explicitly tell Citus that these tables were small. Citus would then replicate this table’s shards across all machines in the cluster and propagate updates to them immediately.
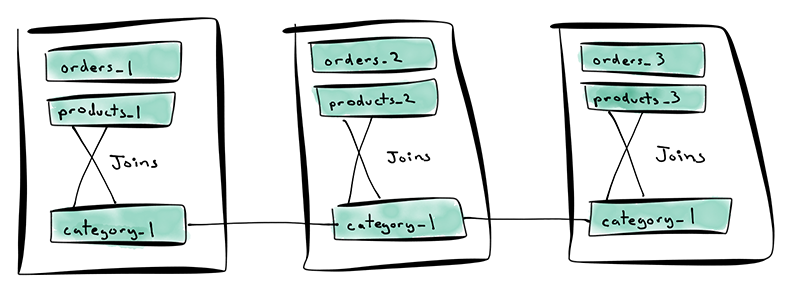
The category table is a reference table. The category table has a single shard that’s replicated across all machines in the cluster.
Because broadcast joins were deeply integrated into our planning logic, we never got around to cleaning them up. Over time, broadcast joins confused new team members. It also made changes to our planners harder. New features would break backwards compatibility with broadcast joins, so we ended up waiting on them.
Riot Games’ blog post on Taxonomy of Technical Debt identifies this type of technical debt as contagious (contagion). In Citus 7.4, we removed all legacy code related to broadcast joins. This reduced the amount of planner code we need to think about when implementing new features. It also resolved seven legacy issues related to broadcast joins.
Reducing time spent on release testing
We expect that each pull request in the Citus repository also comes with its related tests. Then, we assign a reviewer to code review the pull request. The author and the reviewer are also responsible for personal desk-checking of code.
Before each new Citus release, we then go through a release testing process. This process enables us to test new changes not only in isolation, but also in combination. We also compiled a checklist of functionality and performance tests over the years. This checklist helps us maintain the same level of product quality over releases.
For example, the following table captures the sets of tests we ran before releasing Citus 7.4.
| Item | Estimated (dev days) | Actual(dev days) |
|---|---|---|
| - Run steps in documentation - Test app integration | 1 | 2 |
| Integration tests | 1 | 1.5 |
| Test new features | 4 | 4 |
| Failure testing | 4 | 2.5 |
| Concurrency testing | 1.5 | 1.5 |
| Performance testing - Analytical workloads - Transactional workloads | .5 | 1 |
| Scale testing | .5 | .5 |
| Query cancellation testing | 1 | 1 |
| Valgrind (memory) testing | .25 | 1 |
| Upgrade to new version - test | 1.5 | 1.75 |
| Enterprise feature testing | 3 | 2.5 |
| Total | 18.25 | 19.25 |
Over time, we started running into two challenges with release testing. First, as Citus expanded into new use-cases, the surface area of functionality that we needed to test grew with it. As a result, we ended up spending more and more time with release testing.
Second, we made improvements to our release process to reduce our release times from six to four to two months. Consequently, release testing ended up taking a longer portion of each release cycle.
To mitigate these challenges, we first reviewed our release testing process. We then made three improvements over the past year. First, we found test processes that we manually repeated in each release and automated them - such as integration and performance testing.
Second, we found that our regression tests framework caught the most bugs and invested into making it better. Third, we realized that we spent the majority of our time with concurrency testing. Fortunately, Postgres also comes with an isolation test framework. We adopted this framework into Citus and started automating our distributed concurrency tests.
These improvements left one group of tests as a serious offender: failure testing. One of the challenges with distributed databases is that each component can fail. We realized that we were spending a notable amount of time in each release generating machine and network failures. Further, most bugs that surfaced in production were also in this bucket. Often, our customers would report a bug that showed up as a result of a combination of failures in the distributed system.
With Citus 7.4, we’re introducing an automated failure testing framework for Citus. We expect this framework to reduce the amount of time we spend in release testing. Further, we expect to codify typical machine and network failure scenarios into this framework. By doing so, we can catch bugs earlier and provide a better experience to our customers.
Reduce technical debt to move fast
Technical debt is a widely discussed topic between product and engineering teams. On one hand, you want to deliver a product with more features to your customers, fast. On the other hand, these features add complexity to your codebase. You need to keep this complexity in check so that you can bring new developers up to speed and continue to add new features at a fast pace.
At Citus, we see technical debt as maintaining a balance between product and engineering. In each release, we reserve a portion of our time in fixing issues related to technical debt. At the same time, we released ten new versions after open sourcing Citus two years ago. This lead to more features and more code. So, keeping this complexity in check became important in maintaining our release velocity in the long term.
In Citus 7.4, we focused on reducing technical debt related to our planner logic, code paths that became obsolete over the years, and release test times. For a full list of changes, please see the list in our GitHub repo.
Share your feedback on Citus 7.4 with us
Citus 7.4 scales out Postgres through sharding, replication, and query parallelization. This latest release of our Citus database also comes with improvements that will make it easier for us to add new features in the future. As always, Citus is available as open source, as enterprise software you can run anywhere, and as a fully-managed database as a service.
If you give Citus a try, we’d love to hear your feedback. Please join the conversation in our Slack channel and let us know what you think.
