📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
In both Citus Cloud 2 and in the enterprise edition of Citus 7.1 there was a pretty big update to one of our flagship features—the shard rebalancer. No, I’m not talking about our shard rebalancer visualization that reminds me of the Windows '95 disk defrag. (Side-node: At one point I tried to persuade my engineering team to play tetris music in the background while the shard rebalancer UI in Citus Cloud was running. The good news for all of you is that I was overwhelmingly veto'ed by my team. Whew.) The interesting new capability in the Citus database is the online nature of our shard rebalancer.
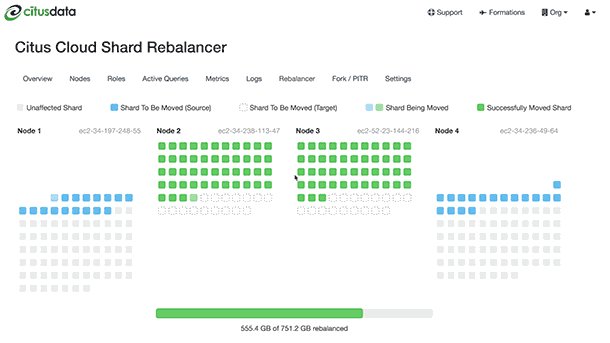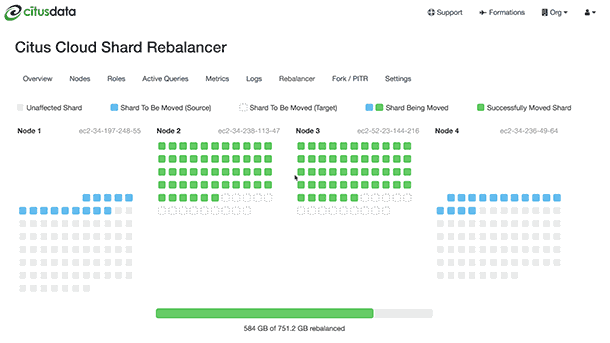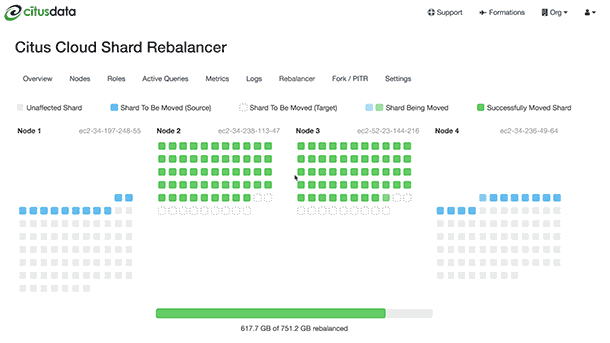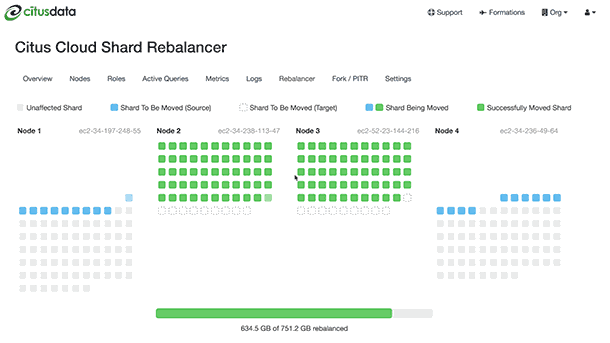
Before I dig into shard rebalancer updates, it's probably helpful to have some baseline understanding of the Citus distributed database. Citus takes a table and distributes it into shards (aka smaller Postgres tables) across multiple physical nodes. Here's an example:
How sharding in Postgres with Citus works
You have an events table. When you shard this events table with the Citus extension to Postgres, under the covers we’ll create events_001, events_002, events_003, etc.
Each of these shards is a standard Postgres table. Your shard count is actually independent of the number of nodes in your Citus database cluster. We then take the shards and split them up among the nodes in your cluster. Which shard lives on which node is all determined by the Citus software and recorded within metadata tables on the Citus coordinator node.
Now let’s take an example SQL query:
SELECT *
FROM events
WHERE user_id = 85
Citus would transform this SQL query under the covers. Note your application doesn’t have to do anything extra to distribute the SQL query across nodes onr across shards, rather, our Citus dynamic executors and router executors take care of it for you. The resulting query would look something like:
SELECT *
FROM events_003
WHERE user_id = 85
Nodes, shards, tables, the transformation of SQL queries... what does any of this have to do with shard rebalancing and scaling out Postgres?
Well, when you initially create your Citus database cluster, you specify the number of shards, which is more of less a soft limit of the number of nodes you can scale to.
The old way of rebalancing
Before Postgres 10 and before Citus 7.1, when you would run the shard rebalancer, Citus would start moving data for a given shard/table to a new node in the Citus database cluster.
While the shards were being moved, we used to have to take a lock to prevent new data from arriving in those shards. All reads of the Citus database would continue to flow as normal, but while that lock was held, the writes used to get queued up. And then, as soon as that lock was released, only then would we allow the writes to flow through as normal. For many applications this was and still is perfectly fine. And yet...
Let’s do some math about how our shard rebalancer worked in the old days. (Actually, my teammate Claire tells me this isn’t math, nor maths—rather, it’s just arithmetic.)
Anyway, let’s do some arithmetic in this pre-Postgres 10 and pre-Citus 7.1 past scenario:
- Let’s say you had 2 Citus worker nodes in your database cluster with 120 shards total across both nodes.
- You wanted to add 2 more nodes, scaling out the total Citus database cluster to 4 nodes.
- Let’s assume, in this case, that it would take you an hour to rebalance the shards—i.e. to move half of the shards (60) from the existing 2 Citus nodes to the 2 nodes you just added to the Citus database cluster.
- In the past, this meant the impact on each shard was that for a 1-2 minute window, writes to those shards would get queued.
- The good news was that all the while your reads would have operated as you'd expected.
- And as each shard was moved, Citus would update the metadata on the Citus coordinator node to re-route new SQL queries (you know, using that Citus router executor I mentioned earlier) to the new Citus worker node.
For rebalancing a database cluster when adding nodes (hence adding memory and vCPU and power), the past shard rebalancer experience with Citus was often sufficient. Some of our customers even said it was “fine”. But we we're not okay with “fine”, we thought we could do better, we knew there were applications & use cases in which a zero-downtime shard rebalancer would be valuable.
Enter Postgres 10, logical replication, & the Citus zero-downtime shard rebalancer
Enter Postgres 10. The logical replication feature, new to Postgres 10, laid a foundation for us to improve the customer experience for our shard rebalancer.
As of our Citus 7.1 release, those few minutes of writes getting queued up that used to exist are now reduced to milliseconds, thanks to how Citus employs the new Postgres 10 logical replication capabilities. If you're not familiar logical replication— in layman's terms, logical replication allows us to get basic inserts, updates, deletes as they happen on the database as well as filter them in a per-table or database view.
The powerful basics of the new logical replication feature in Postgres 10
The way to set up logical replication between two different Postgres databases is to create the same table schema on 2 different Postgres databases, and then to create a “publication” on the Postgres database that’s taking writes, and then to create a “subscription” on the Postgres database that you want to replicate to (i.e. on the Postgres database that is meant to be a copy of the primary.)
Under the covers, Postgres 10 starts copying the data in the table using the COPY command. This happens without blocking writes, so by the time the initial data copy completes, the source table might have changed. The magic in logical replication is that it will store a log of all changes from the moment the data copy started and then replay them on the subscriber, keeping it continuously in sync.
This new logical replication capability in Postgres has a lot of potential. For example, it can be used to upgrade Postgres with minimal downtime. Our Citus extension to Postgres now uses logical replication under the covers to scale out a cluster seamlessly and to rebalance your database with zero downtime.
Under the hood of the zero-downtime shard rebalancer in Citus
Now, when you run the shard rebalancer in Citus after adding a new worker node, the Citus shard rebalancer chooses which shards to move to the new node(s). To move a shard, the rebalancer creates the table structure, including indexes and constraints, on the new node and then sets up the publication and subscription to replicate the shard (including changes to the shard) to the new node.
The Citus shard rebalancer then waits until the initial data copy is complete and the new node is reasonably caught up with the change log. When only a few changes are remaining, the Citus coordinator very briefly blocks writes and waits for the new node to catch up with the last few remaining writes, and then drops the old shard and starts using the new one. This way, the application will barely even notice that the data was being moved.
Co-location makes the Citus shard rebalancer safe for applications
Doing the rebalancing in an online fashion means there is no locking of writes, but what about applications that have a lot of joins?
For use cases with lots of joins, you need to ensure all of the references to the data are intact and not spread across nodes.
With Citus, when you shard your tables by a distribution key (sometimes called a sharding key, or a partition key) such as tenant_id or customer_id (as many of our users with multi-tenant applications do), all tables associated with a particular tenant_id or customer_id are then co-located on the same node. Citus then keeps track of these co-located tables and ensures that they remain together so you can easily join them.
When the Citus shard rebalancer begins moving data, it respects that a user’s data spans across multiple tables and those tables stay together. To honor this, the shard rebalancer moves all the tables that have relationships together and does the cutover with the final writes in sync.
Want to learn more about how the Citus extension to Postgres works?
If you have any questions about the inner workings of Citus, we’re always happy to spend time talking about Citus, Postgres, and how others are already using Citus to give their applications a kick (in terms of performance, and scale.)
In fact, when I had coffee with one of our users recently, this CTO warmed my heart with these words:
“If I’d known I could talk to real [knowledgeable & helpful] humans, I would have contacted you months earlier.”
So if you have any questions or just want to say hi, feel free to join us in our slack channel. And if you want to hop on the phone to explore whether Citus is a fit for your use case contact us.