The schedule is out 🗓️ for POSETTE: An Event for Postgres 2026!
Citus is a distributed database that extends (not forks) PostgreSQL. Citus does this by transparently sharding database tables across the cluster and replicating those shards.
After open sourcing Citus, one question that we frequently heard from users related to how Citus replicated data and automated node failovers. In this blog post, we intend to cover the two replication models available in Citus: statement-based and streaming replication. We also plan to describe how these models evolved over time for different use cases.
Going back to Citus’ first version, one of the early use cases that we looked at was analyzing large volumes of event data in real-time. This data has the nice property that they are append-only and have a natural time dimension. Users could therefore batch those events together and load them into the distributed cluster.
These properties of event data enabled parallel loads of events data, without sacrificing from consistency semantics, relatively easy. A coordinator node would keep metadata related to shards and shard placements (replicas) in the cluster. Clients would then talk to the coordinator node and exchange metadata on which shards to append events data. Once a client appended related events data to the related shards, the client would conclude the operation by updating the shard metadata on the coordinator node.
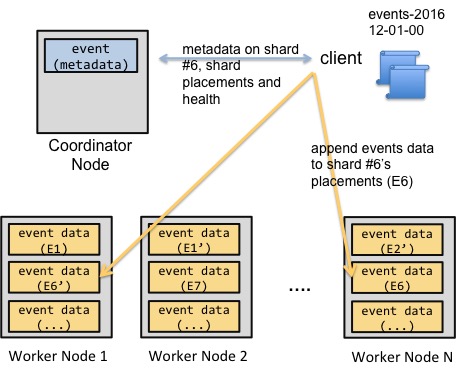
The simplified diagram above shows an example data load. The client tells the coordinator node that it wants to append events data to an append-distributed table. The coordinator node grants the client information about shard 6’s placements. The client then copies these events to the shard’s placements and updates the coordinator with related metadata. If the client fails to copy events to one of the nodes, it can either mark the related shard placement as invalid or abort the copy operation.
There are three important points to highlight in this example.
- The method above is known as statement-based replication and it provides automated failover in a relatively simple way.
- If the coordinator node becomes unavailable, you need to restart it or fail it over. The fact that the coordinator node only holds small and slowly changing metadata helps.
- Events data is immutable. Loading it into the cluster changes the shard’s state in a deterministic way. These properties make it much more amenable for use with statement based replication. In particular, different clients could load events data into the cluster in parallel, without creating conflicts with one another.
We felt pretty happy about leveraging these properties in our initial release -- at least for several months. After all, other distributed / analytical systems also made similar assumptions about events data, and told their users how they should be loading their data.
The challenge was that Postgres users had very different expectations than those of other distributed systems. Scaling your database to hundreds of machines was intriguing. But, “What do you mean you can’t update records? Isn’t this Postgres?” became an everyday question.
We therefore took Citus’ statement-based replication model and extended it. In this model, we also provided hash distribution as a data distribution method. This way, users could easily update and delete individual rows. Enabling update and deletes also required that we address two questions: concurrent clients updating the same row, and one of the shard replicas becoming unavailable during an update.
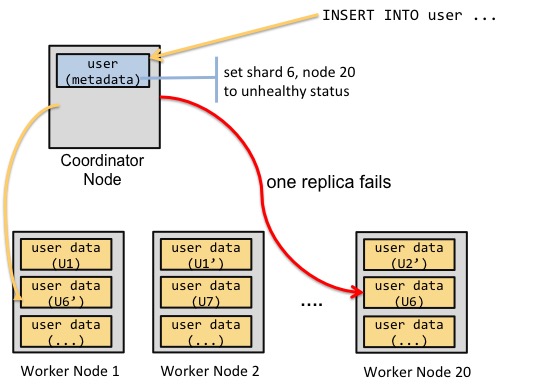
We therefore extended the coordinator node in two ways. First, the coordinator handled locking for update and delete statements touching the same shard. Second, if the coordinator node couldn’t reach a shard replica during a write operation, it would mark that replica as unhealthy. The user would then run a command to fix the unhealthy replica from the healthy one.
From a consistency semantics standpoint, this approach is commonly referred to as read your writes consistency.
We first released these improvements to statement-based replication with pg_shard. We then integrated them fully into Citus with our open source announcement. And our customers started running even more operational workloads.
The tricky thing about SQL in a distributed system is that it provides many constructs that aren’t deterministic or commutative in nature. As a result, if you allow the underlying state to diverge across different replicas, you can’t really reconcile that state (without losing data).
In particular, our customers wanted to have stronger transactional guarantees and efficient joins. As we added those capabilities, we also saw that our customers started using Citus for a new use-case.
Previously, Citus customers focused on real-time analytical workloads -- they would ingest large volumes of data into the cluster and then run analytical queries that would complete under a second. With these new capabilities in Citus, we saw another use-case emerge. Our customers started building scalable multi-tenant databases.
We found that the key to scaling out a multi-tenant database is through colocating a tenant's data from different tables within one machine. Highly scalable multi-tenant databases (for example Google’s F1) were already using table colocation; and this method made most transaction and join operations extremely efficient. It also enabled key features, such as foreign key constraints.
Table colocation introduced yet another challenge with statement-based replication. Let’s say that you have 200 tables that are sharded on the same dimension and colocated. If you have concurrent updates to 10 of the tables’ shards, and you fail to reach a machine that holds shard replicas, what do you do? To honor foreign key constraints, you’d need to mark all 200 shard replicas on that machine as inactive. If you did that, how does that impact high availability?
We talked about this challenge and other related issues on GitHub issues. In summary:
If you are building a sharded multi-tenant database (you have a highly normalized data model) and you are also looking for high availability features, then statement-based replication is often not good enough.
The reason for that is you can’t have the underlying data diverge some and then look to reconcile it. The more dependencies you have across your tables, such as foreign key constraints, the more likely it becomes that an update statement will have side-effects.
So what do you do if you’re building a multi-tenant database? One possibility is to reduce the replication factor to 1. If you don’t have replication, your state can’t diverge. In fact, Citus 6.0 already instructs you to reduce the replication factor if you’re using foreign keys.
Another option is to switch from statement-based to streaming replication. PostgreSQL has been building up on streaming replication for the past five releases now; and this replication model ensures that your changes get applied in lockstep fashion. That is, if you arrange worker nodes into replication groups, Citus can then route a request for a shard to that replication group’s primary. On the primary node, Postgres can then apply its concurrency control logic. This approach's architecture looks like the following:
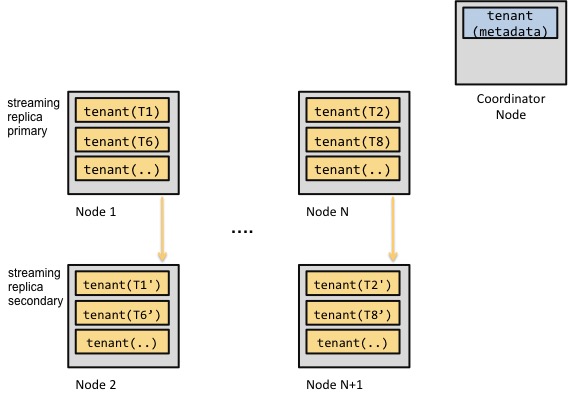
The thing is, Postgres’ streaming replication isn’t exactly the most fun system to set up. On Citus Cloud, we can use our team’s immense experience with managing Postgres and the primitives available on AWS to automatically take care of things for you. For our open source deployments, we’re actively evaluating projects that make use of streaming replication easier and we’ll follow up with updates over the course of next year.
In the meantime, we’re also making two changes with our v6.1 release. First, we’re encouraging users who’re building scalable multi-tenant databases to use streaming replication. The easiest way to do that is through Citus Cloud.
Second, we recognize that our users have multiple use cases; two of them are multi-tenant applications and real-time analytics. We’d like Citus’ default behavior across all use cases to be safe, not web scale. We’re therefore reducing the default replication factor for statement replication to 1. Users can increase this setting, but we’d like to make this an explicit change -- anticipating that it will raise awareness about statement-based replication and its drawbacks for the multi-tenant use case. We’re also capturing this change, its motivations and technical details in GitHub issues.
In summary, we learned through Citus releases and talking to our customers that PostgreSQL sets different expectations. At a higher level, customers have a different mental place in their minds for a relational database (RDBMS) than a NoSQL or Hadoop based database. This makes scaling out an RDBMS hard -- the more your use case expects from the database, the trickier this gets. At Citus, we will continue to address each of these challenges with every new release.
We hope this blog post provides a helpful insight into where Citus started its replication journey and where it’s headed. We always drive the product direction with input from our users and customers; and we’re looking forward to hearing more. If you have questions or comments for us, please drop us a line in our Slack channel or Intercom.
