📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
This post by David Rowley about Postgres 15 was originally published on the Microsoft TechCommunity Blog.
In recent years, PostgreSQL has seen several improvements which make sorting faster. In the PostgreSQL 15 development cycle—which ended in April 2022—Ronan Dunklau, Thomas Munro, Heikki Linnakangas, and I contributed some changes to PostgreSQL to make sorts go even faster.
Each of the improvements to sort should be available when PostgreSQL 15 is out in late 2022.
Why care about sort performance? When you run your application on PostgreSQL, there are several scenarios where PostgreSQL needs to sort records (aka rows) on your behalf. The main one is for ORDER BY queries. Sorting can also be used in:
- Aggregate functions with an ORDER BY clause
- GROUP BY queries
- Queries with a plan containing a Merge Join
- UNION queries
- DISTINCT queries
- Queries with window functions with a PARTITION BY and/or ORDER BY clause
If PostgreSQL is able to sort records faster, then queries using sort will run more quickly.
Let’s explore each of the 4 improvements in PostgreSQL 15 that make sort performance go faster:
- Change 1: Improvements sorting a single column
- Change 2: Reduce memory consumption by using generation memory context
- Change 3: Add specialized sort routines for common datatypes
- Change 4: Replace polyphase merge algorithm with k-way merge
Change 1: Improvements sorting a single column
PostgreSQL 14’s query executor always would store the entire tuple during a Sort operation. The change here makes it so that PostgreSQL 15 only stores a Datum when there is a single column in the result of the sort. Storing just the Datum means that the tuple no longer has to be copied into the sort’s memory.
The optimization works for the following query:
SELECT col1 FROM tab ORDER BY col1;
but not:
SELECT col1, col2 FROM tab ORDER BY col1;
The first of the above queries is likely rare in the real world. A more common reason to have single column sorts is for Merge Semi and Anti Joins. These are likely to appear in queries containing an EXISTS or NOT EXISTS clause.
The graph below shows how much storing only the Datum can help by testing the performance of sorting 10,000 integer values.
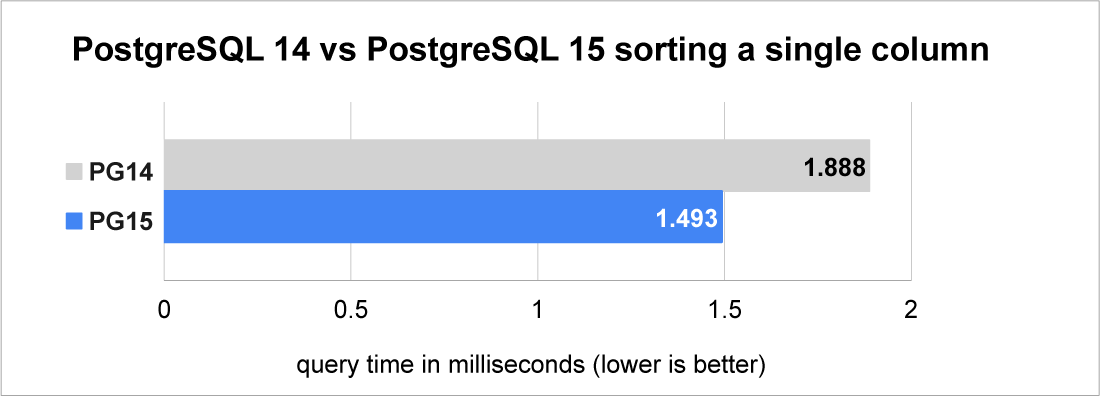
For further information see the link to the Postgres 15 commit message
Change 2: Reduce memory consumption by using generation memory context
When PostgreSQL stores records in preparation for sorting, it must copy the record into an area of memory ready to sort. In PostgreSQL 14 and earlier, when memory is allocated to store records to be sorted, the "aset" memory allocator is used. These memory allocators get used for managing memory in PostgreSQL. They act as a buffer between PostgreSQL and the underlying operating system. The "aset" allocator always rounds memory allocation request sizes up to the next power of 2. For example, a 24-bytes allocation request becomes 32-bytes, and 600 bytes becomes 1024 bytes. Rounding up to the next power of 2 done because when memory is freed, PostgreSQL wants to be able to reuse that memory for future needs. The rounding up is done so that the memory can be tracked in free-lists according to the size of the allocation. Rounding up vastly reduces the number of distinct sizes so helps keep the number of free-lists manageable.
Rounding up to the next power of 2 causes an average of 25% of memory to get wasted.
Typically, PostgreSQL has no need to free any memory for records when sorting. Normally it only needs to free all memory at once when the sort is complete, and the records are consumed. PostgreSQL also frees all the memory at once when the data to sort does not fit in memory and must be spilled to disk. So, for the general case, PostgreSQL never has to free individual records and the rounding up of the memory allocation sizes just causes memory to be wasted.
PostgreSQL has another memory allocator named "generation". The generation allocator:
- never maintains any free-lists
- never rounds up allocation sizes
- assumes the allocation patterns are first in first out.
- relies on freeing complete blocks when all chunks on each block are no longer needed
Because "generation" does not round up allocation sizes, PostgreSQL can store more records with less memory. Switching sort’s tuple storage to use a generation memory context instead of an aset context also improves the situation from a CPU cache point of view.
How much this change improves performance depends on the width of the tuples that are stored. Tuple sizes that are slightly above a power of 2 improve the most. For example, PostgreSQL 14 would round a 36-byte tuple to 64-bytes—close to double the memory that is needed. We can expect the least increase in performance from tuples that are already a power of 2 in size.
To show how much faster this change makes sort, we will need to test a few different sizes of tuples. What I have done is start with 1 column and test its performance, before adding another column and repeating. I stopped at 32 columns. Each column uses the BIGINT datatype which consumes an extra 8 bytes each time a column is added.
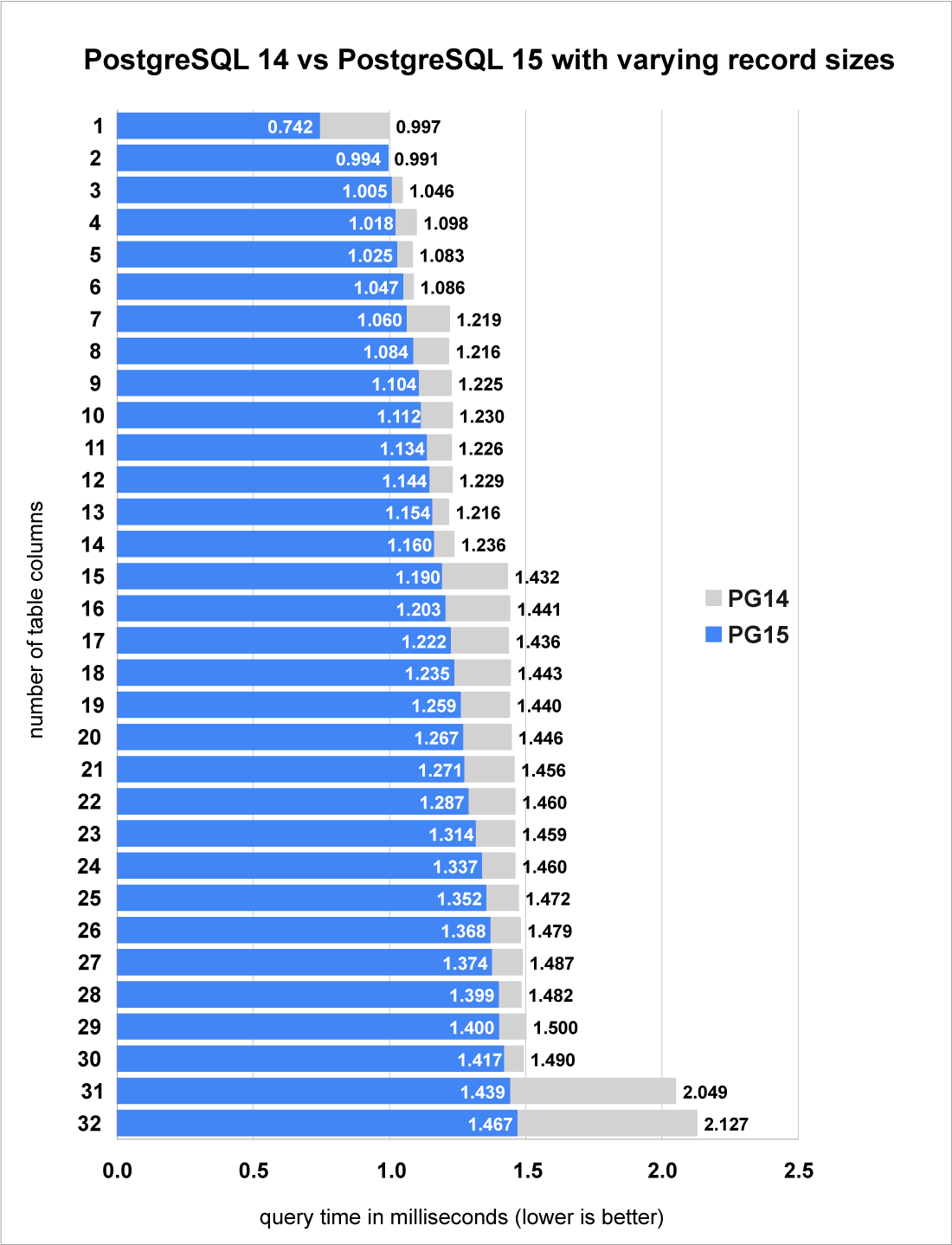
The test results show that the performance of PostgreSQL 15 has improved by between 3% and 44%, depending on the width of the tuple.
- Looking closely at the PostgreSQL 14 times, you can see bars going up in steps. Each step lines up with when the tuple size grew beyond another power of 2.
- Whereas for PostgreSQL 15, you don’t see the same "steps" where query time takes significantly longer, the way you do with Postgres 14 (at 7 columns, 15 columns, and 31 columns). Rather, in PostgreSQL 15 the query time increases more gradually as the number of columns increases.
PostgreSQL 15 does not use the generation memory context for bounded sorts. For example, a query with an ORDER BY and LIMIT N clause. The reason the optimization is not used here is that bounded sorts only store the top-N tuples. Once N records are fetched, PostgreSQL will start to throw away tuples that are out of bounds. Throwing away tuples requires freeing memory. PostgreSQL cannot determine in advance the order that tuples will be freed. The generation memory context is likely to waste large amounts of memory if it was used for bounded sorts.
For further information see the link to the Postgres 15 commit message.
Change 3: Add specialized sort routines for common datatypes
Sorting done in PostgreSQL using an adapted quicksort algorithm. PostgreSQL has a vast number of different datatypes which users are even able to extend themselves. Each datatype has a comparison function which is given to the quicksort algorithm to use when comparing 2 values. The comparison function returns either a negative number, 0 or a positive number to state which value is higher or if they are equal.
The problem with having this comparison function is that to perform a sort, PostgreSQL must call the function many times over.
- In the average case, when sorting 10,000 records, PostgreSQL would need to call the comparison function O(n log2 n) times. That is about 132 thousand times.
- When sorting 1 million records, the average number of comparisons is around 20 million.
PostgreSQL is written in the C programming language—and while C function call overhead is low, C function calls are not free. Calling a function so many times has a noticeable overhead, especially when the comparison itself is cheap.
The change made here adds a set of new quicksort functions which suit some common datatypes. These quicksort functions have the comparison function compiled inline to remove the function call overhead.
You can do the following if you want to check if the datatype you’re sorting in PostgreSQL 15 is using one of these new quicksort functions:
# set client_min_messages TO 'debug1';
and run your SQL query:
# explain analyze select x from test order by x;
If your debug message says either:
- qsort_tuple_unsigned
- qsort_tuple_signed
- qsort_tuple_int32
then you’re in luck. If the debug message says anything else, then the sort is using the original (slower) quicksort function.
The 3 quicksort specializations that have been added cover more than just integer types. These new-to-PostgreSQL 15 functions also cover timestamps and all data types that use abbreviated keys, which included TEXT types using the C collation.
Let’s a have a look at the performance increase from the sort specialization functions. We can trick PostgreSQL’s executor into not applying the optimization for change 2 by adding a LIMIT clause to the query.
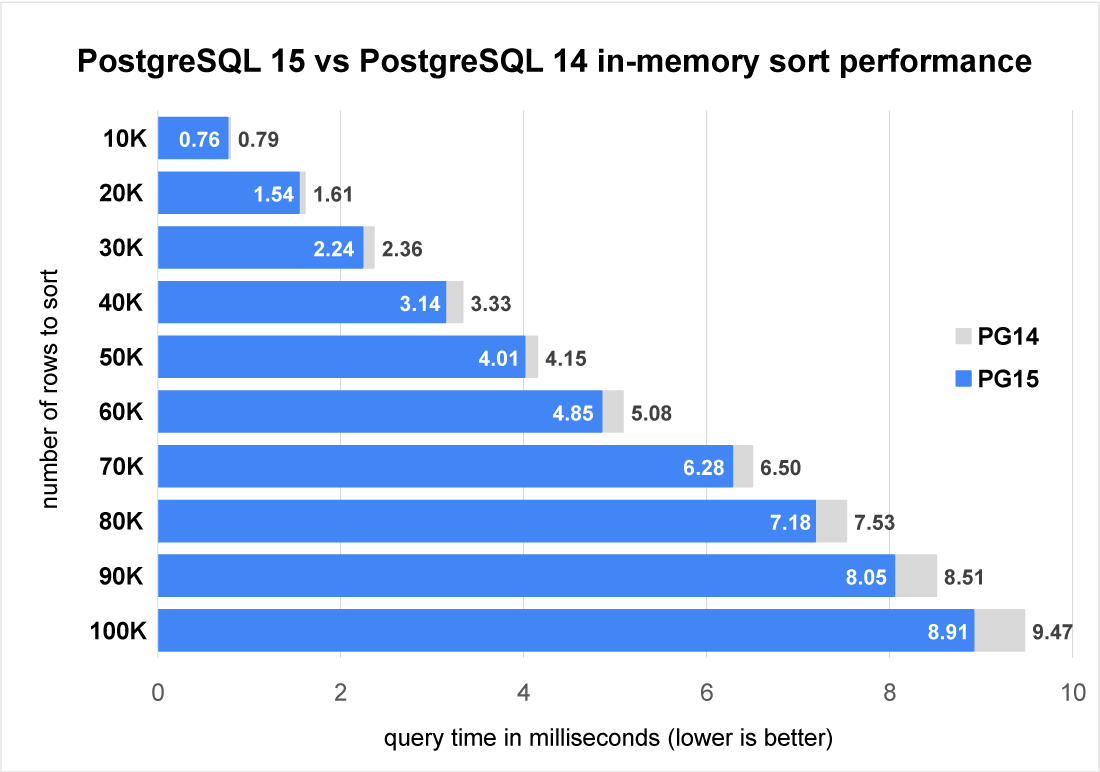
Here we can see that in this small-scale sort that performance does increase as more rows are sorted. This is expected as the sort specialization change reduces the constant factors of comparing tuples during the sort. Sorting more records requires, on average, more comparisons per record. So we see larger savings with more records. These speedups only apply up until CPU caching effects cause the performance to degrade again due to more frequent CPU cache misses.
For further information see the Postgres 15 commit message.
Change 4: Replace polyphase merge algorithm with k-way merge
The final change is aimed at larger scale sorts that exceed the size of work_mem significantly. The algorithm which merges individual tapes was changed to use a k-way merge. When the number of tapes is large, less I/O is required than the original polyphase merge algorithm.
Let’s do some benchmarks to see how the merge algorithm change affects the performance of PostgreSQL 15.
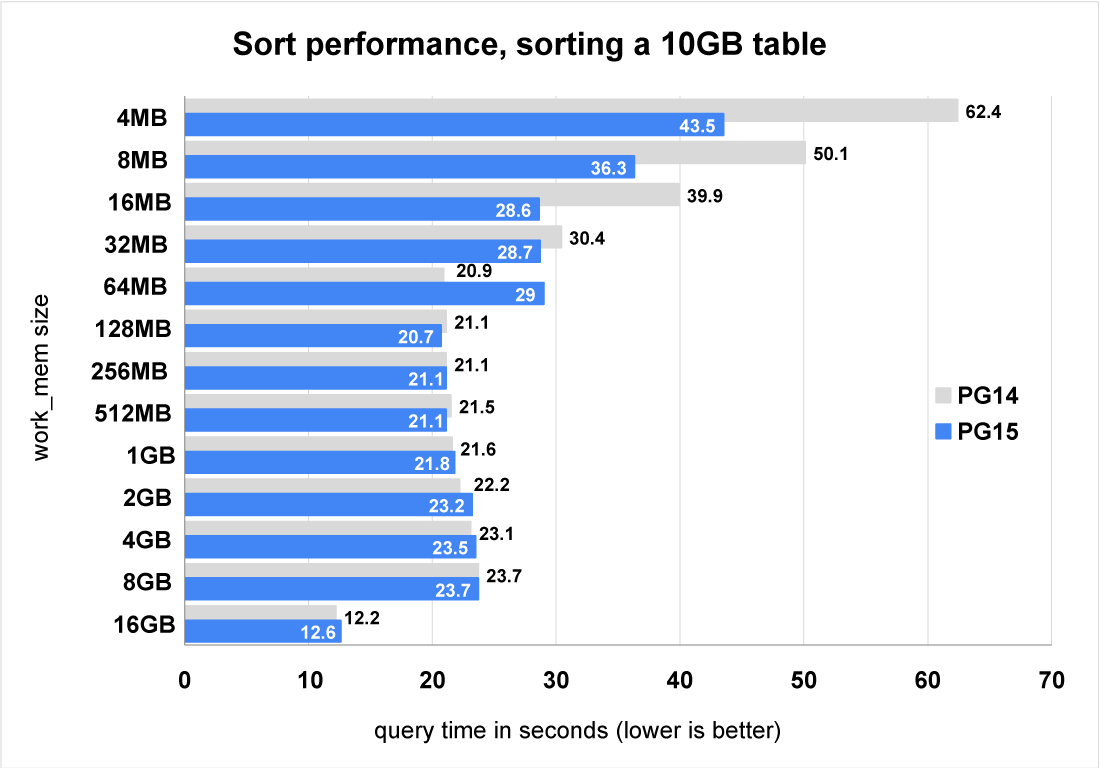
Figure 4 above shows us that PostgreSQL 15 performs much better than PostgreSQL 14 for large sorts with very small values of work_mem. As the work_mem setting is increased, the performance gap decreases. With the largest value of work_mem (16GB) the sort no longer spills to disk. We can also see that the test with a work_mem setting of 64MB caused the query to run more slowly. This will require some further investigation before PostgreSQL 15 is released.
For further information see the postgresql git commit message.
Future Work for sort in Postgres
We are highly likely to see further improvements in future PostgreSQL releases in the area of sort function specialization. For example, when PostgreSQL compares two values during a sort, it needs to check for NULLs. That is quite cheap to do for a few values but remember, this comparison must be done many times. The cost of the comparisons adds up quickly. If PostgreSQL already knew that no NULLs existed by checking for them when it stores records, then there would be no need to check for NULLs when comparing two records to sort. Many columns have NOT NULL constraints so this case should be common. PostgreSQL could also use NOT NULL constraints as proofs so that it does not have to check for NULLs at runtime.
Why not try PostgreSQL 15 today to see how these changes affect your workload?
The first test I ran while working on reducing the memory consumption of sort improved performance by 371%. This was due to the reduction in memory consumption required for storing the records to sort no longer exceeding my work_mem setting. Previously the sort was spilling to disk and after the change the entire sort was done in memory.
Many SQL queries running on PostgreSQL require records to be sorted. Making sort go faster in PostgreSQL 15 is likely to make many of your queries go faster than on PG 14.
If you want to give sort performance in PostgreSQL 15 a try:
- The release notes for PostgreSQL 15 are now online.
- PostgreSQL 15 beta 1 released on the 19th of May 2022 (it will be followed by "release candidate" versions in the months that follow)
- The final release of PostgreSQL 15 is due around October/November 2022
- You can download PostgreSQL 15 beta 1 here
If you’re reading this before the final release of PostgreSQL 15, why not download a copy of the PostgreSQL 15 beta and try out your own workload to see for yourself?
