📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
This post by Sai Srirampur was originally published on the Azure Database for PostgreSQL Blog on Microsoft TechCommunity.
Update in October 2022: Citus has a new home on Azure! The Citus database is now available as a managed service in the cloud as Azure Cosmos DB for PostgreSQL. Azure documentation links have been updated throughout the post, to point to the new Azure docs.
In my work as an engineer on the Postgres team at Microsoft, I get to meet all sorts of customers going through many challenging projects. One recent database migration project I worked on is a story that just needs to be told. The customer—in the retail space—was using Redshift as the data warehouse and Databricks as their ETL engine. Their setup was deployed on AWS and GCP, across different data centers in different regions. And they'd been running into performance bottlenecks and also was incurring unnecessary egress cost.
Specifically, the amount of data in our customer's analytic store was growing faster than the compute required to process that data. AWS Redshift was not able to offer independent scaling of storage and compute—hence our customer was paying extra cost by being forced to scale up the Redshift nodes to account for growing data volumes. To address these issues, they decided to migrate their analytics landscape to Azure.
Migrating Databricks to Azure was straightforward because Databricks is available as a first-party service on Azure via Azure Databricks. Regarding the database, Azure offers a variety of database services, so our customer had a few choices. The customer's data size was not huge, it was around 500GB—which led them to wonder: should they choose PostgreSQL which would likely reduce the migration effort because Redshift is Postgres based? Their question was: would a single Postgres node give suitable performance? Or should they choose a pure analytical store, which might not be required and incur extra migration effort.
This post will walk you through our journey of considerations, tests, requirements, blockers and so on, as we helped our customer determine which database would ensure an optimal balance of increased performance and reduced cost—with the simplest migration off of Redshift, too.
Interactive analytics dashboard requires fast query responses
Prior to the data migration away from Redshift, the customer had been using the Redshift data warehouse to store and analyze data related to user events on their website, sales, marketing, support, and so on. This data was coming from various sources (applications) and the load was near real-time (every 1 hour). Hence, the Redshift data warehouse was a central piece of their analytics (OLAP) story.
They used the open source Metabase as the BI tool to generate dashboards and visualize all the data—and they had nearly 600 queries that needed to be migrated from Redshift. As dashboards are end-user facing, queries had to perform very well, i.e., with query response times in single digit seconds. In addition, the analytics dashboards were very interactive, i.e., their users could filter and slice/dice on over 20 different dimensions. There were around 200 Databricks jobs (aka Apache Spark) that transformed and cleaned the data stored in the data warehouse and made the data ready for querying from Metabase.
Would a single Postgres node deliver the required performance?
Since Amazon's Redshift data warehouse is based on PostgreSQL (Redshift is a proprietary fork of Postgres) and our customer's data size of ~500GB was not huge, the first thing the customer decided to test was vanilla PostgreSQL on a single server, to see if single-node Postgres database would make the cut. They tested with Azure Database for PostgreSQL – Single Server, the PaaS offering for Postgres on Azure. However, it turned out that a single Postgres server was not adequate for this customer's application: SQL queries that had been running in single digit seconds on Redshift took over 40 seconds to complete on a single Postgres node. This is because even though Postgres offers Parallel Query feature that can parallelize a single query using multiple threads, it is restrictive in terms of what type of queries and what parts of the query plan can be parallelized. Hence we were not able to maximize the underlying hardware resources to improve query latency.
At this point, our team suggested that the customer try the Hyperscale (Citus) deployment option in Azure Database for PostgreSQL.
If you are unfamiliar with Citus, a quick primer: Hyperscale (Citus) is built from Citus, an open source extension to Postgres. On Azure, Hyperscale (Citus) transforms Postgres into a distributed database, so you can shard/partition your data across multiple nodes in a server group—enabling your Postgres queries to use all of the CPU, memory, and storage in the server group (i.e. in the distributed cluster.) Hyperscale (Citus) has built-in logic to transform a single query into multiple queries and run them asynchronously (in parallel) across multiple partitions (called shards) in an efficient way to maximize performance. The query parallelism offered by Citus extends to a variety of SQL constructs—including JOINs, subqueries, GROUP BYs, CTEs, WINDOW functions, & more.
An important prerequisite to scaling out Postgres horizontally with Hyperscale (Citus) is to decide what your distribution column will be. (Some people call the distribution column the 'distribution key', or the 'sharding key.') Most of the times picking a distribution column is very intuitive based on the application use case. For example with this customer, for the click stream workload that captures events from users visiting their website, we picked user_id as it is a natural sharding key because events are coming from users, and the dashboards are for analyzing and understanding user behavior.
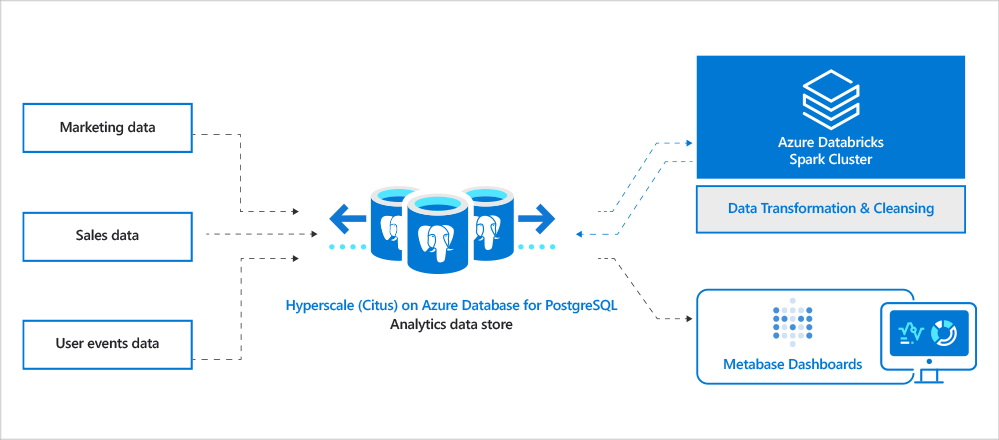
This architectural diagram for Hyperscale (Citus) is below:

Choosing Hyperscale (Citus) to power an analytics workload
Real-time analytics is a use case where Hyperscale (Citus) really shines. The MPP nature of a distributed Postgres database and close relationship with the PostgreSQL ecosystem makes Hyperscale (Citus) a compelling choice for migrations from Redshift.
The customer tested Hyperscale (Citus) and found an average ~2x performance improvement vs Redshift for similar sizing (hardware) on both sides. They went with a 2 worker-node Hyperscale (Citus) cluster with each worker having 8vcores (64GB RAM) and 512GB storage. So the total horse power of the database was 16vcores, 128GB RAM and ~3000 IOPs (3 IOPs/GB of storage).
Below are some of the learnings from the migration process.
Query parallelism & Postgres indexes yielded a ~2x performance gain vs. Redshift
Query parallelism and indexes are a game changer in workloads where you need to filter on many different combinations of columns, where you can't afford to scan the entire dataset for these queries. This ability to create indexes in Hyperscale (Citus) really helped. Redshift is not very flexible with indexes; you can't run the CREATE INDEX command because Redshift is a columnar store. With Hyperscale (Citus), however, you get the same flexibility as Postgres in creating indexes. Even the CREATE INDEX and CREATE INDEX CONCURRENTLY are parallelized across worker nodes, which can lead to tremendous performance benefits. (CONCURRENTLY avoids blocking writes during index creation.) We have heard customers reporting close to ~5-10x performance improvement in creating indexes with Hyperscale (Citus).
In this customer scenario, we created more than 30-40 indexes to speed up their Postgres queries. Because of the interactive nature of their analytics application, there was a lot of dynamic filtering based on various dimensions—and using Postgres indexes helped.
Use JSONB to store semi-structured data
Because Redshift doesn't support the JSON/JSONB data types, our customer had been forced to store their large JSON documents as text columns in Redshift—and they also had to use the JSON functions that Redshift provides to parse through the JSON documents. The good news is that because Hyperscale (Citus) natively supports the Postgres JSON/JSONB data-types, you can store and query JSON documents, and you can use JSONB to store the JSON document in a binary format.
As a part of the migration process, we decided to use the JSONB data type in Hyperscale (Citus) instead of text, so our customer could reap the benefits of JSONB—a robust set of functions that Postgres natively supports for JSONB, as well as the ability to index JSONB columns with GIN type indexes. This not only helped in modernizing the application by using recent features of Postgres, but also led to significant performance gains—querying a JSONB directly is better than typecasting a text to a JSON and then querying it. If you haven't yet tried JSONB in Postgres, I would strongly recommend trying it out—it's been a game changer for many customers! ☺
The JSONB data type in Postgres can also give 6x-7x compression
An interesting phenomenon we observed was that the storage footprint in Hyperscale (Citus) was only slightly higher than that of Redshift (550GB in Hyperscale (Citus) vs 500GB in Redshift). Since Redshift stores data in a columnar format, it compresses really well. As Hyperscale (Citus) is a row-based store, we expected the Hyperscale (Citus) storage footprint to be significantly higher, but we were surprised to see a very low increase in storage footprint compared to Redshift, even with 30-40 Postgres indexes.
Using the JSONB datatype in Postgres, which inherently compresses the JSON documents (with toast), made the difference. As the size of a JSON document grows, the compression rates increase. We have seen over 7x compression with some customers storing large JSON documents (in MBs).
Migration effort from Redshift to Hyperscale (Citus) took ~2 weeks
As Redshift is also based on PostgreSQL, the migration effort was minimal. Overall, it only took around two weeks for the end-to-end migration from Redshift to Hyperscale (Citus). As I mentioned before, the first step was to pick the right distribution column(s) so you can inform Hyperscale (Citus) as to how you want your data sharded across all the nodes in the Hyperscale (Citus) cluster. The next step was to decide which tables should be distributed vs. which tables should be reference across all the nodes in the Hyperscale (Citus) cluster. Once that was done, code changes were made—including changes to some of the SQL queries and databricks jobs—followed by data migration using simple Postgres pg_dump and pg_restore utilities.
Some of the learnings from our migration journey from Redshift to Hyperscale (Citus) in Azure Database for PostgreSQL:
- Tables: 180 tables were migrated. Over 80 of them were distributed across worker nodes.
Query migration:
- 80% of the queries were drop-in, with no modification!
- 18% of the queries needed Redshift->Postgres syntax changes to get benefits from to text->JSONB conversion. Instead of using functions that Redshift provides, we used native JSONB functions/operators provided by Postgres.
- 2% of the queries needed updates that were Hyperscale (Citus) related, i.e., distributed tables related.
Databricks jobs: 200 Databricks jobs were nearly drop-in, with minimal changes, because the JDBC driver that Redshift uses is same as that for Postgres/Hyperscale (Citus).
Hyperscale (Citus) has a shared nothing architecture
Hyperscale (Citus) has a shared nothing architecture i.e. each node in the cluster has its own compute and storage. We let you scale up/down compute of coordinator and workers separately. If you wanted to just scale storage and not compute, you can do that as well by scaling storage on workers and coordinator independently. Our customer found this useful as a way of optimizing costs, especially because with Redshift they had not been able to independently scale storage.
Along with this we also give you the ability to horizontally scale out. You can easily add more servers to the Hyperscale (Citus) server group on Azure and rebalance data in an online way. By "online" I mean there is no downtime for reads and writes while rebalancing data from already existing servers to the new servers in the cluster (cluster = server group, I use those two terms interchangeable.)
Some sweet spots for migrations from Redshift to Hyperscale (Citus)
Based on our experience, Azure Database for PostgreSQL - Hyperscale (Citus) could be a compelling option for customers migrating from Redshift for certain workloads. As the case study above illustrates, below are some sweet spots for Hyperscale (Citus). If your workload has one (OR) more of these sweet spots, consider Hyperscale (Citus) as a good candidate for your analytics (OLAP) store. ☺
- Interactive real-time analytics: Different variations of queries due to multiple permutations of column filters. An indicator of this is when your end-users need to ask questions with lots of different parameters, which means they need to query with many different column filters. One way I often describe it is: "Interactive Real-time Dashboarding/Analytics" vs "Pure Offline Analytics".
- Mixed workloads with transactions & analytics: UPDATEs, DELETEs are a part of the workload along with INSERTs/COPY (common in mixed workloads such as htap, as seen in this SIGMOD demo).
- High concurrency: more than 50 end users querying the database at one time (a.k.a. interacting with the Metabase interactive analytics dashboard at once) along with concurrent ingest.
- Preference for Postgres: an affinity to stick to Postgres and use its latest features—JSONB, HLL, Partitioning, PostGIS/Geospatial etc.
