📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
There are a lot of things that are everyday occurrences for engineering teams. Deploying new code, deploying a new service, it's even fairly common to deploy a net new data store or language. But migrating from one database to another is far more rare. While migrating your database can seem like a daunting task, there are lessons you can learn from others—and steps you can take to minimize risk in migrating from one database to another.
At Citus Data, we've helped many a customer migrate from single node Postgres, like RDS or Heroku Postgres, to a distributed Citus database cluster, so they can scale out and take advantage of the compute, memory, and disk resources of a distributed, scale-out solution. So we've been privy to some valuable lessons learned, and we’ve developed some best practices. Here you can find your guide for steps to follow as you start to create your migration plan to Citus.
Refine your database's data model to prepare for sharding
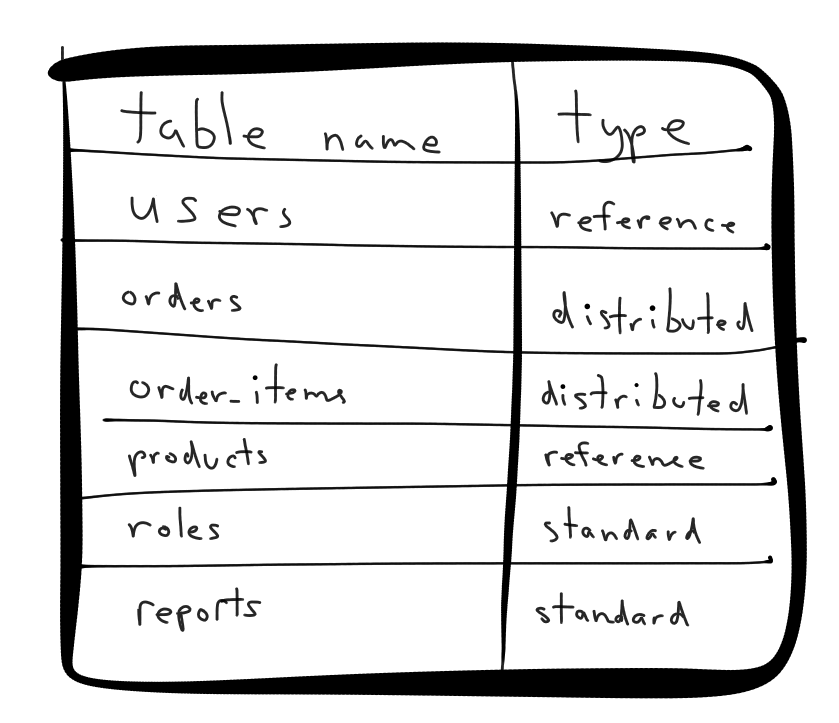 The first step in the process is to define your database’s data model, just as you would if you were building your application fresh. Within Citus, there are three table types: distributed tables, reference tables, and standard Postgres tables on the Citus coordinator node.
The first step in the process is to define your database’s data model, just as you would if you were building your application fresh. Within Citus, there are three table types: distributed tables, reference tables, and standard Postgres tables on the Citus coordinator node.
Initially when setting things up, you may trial things with a subset of your tables, perhaps just 3-10 tables, just to get things working. As you prep for migration, you'll want to go through and build up a full inventory of tables and define which each is, we've found it's good to maintain a spreadsheet of each table and it's type and then have a migration to update your schema accordingly.
Deciding how to distribute your data across nodes in Citus
The needs of your application will inform what approach you should take to sharding your data across multiple nodes. In order to prepare your application for that you may have to add some data. The most common thing we see among SaaS applications is that tenant_id needs to be backfilled when following the multi-tenant approach.
Pro-tip: If you're using our gem activerecord-multi-tenant it has a mode that allows you to apply tenant_id on inserts and updates to ease your migration process.
Backfill data that is missing
Once you know your table setup, and once you have a column for tenant_id on every table, you need to make sure the data filled in. It's a good idea to let things run in insert/update mode for a little while, but even with that you still may be missing some data.
The best process to update your missing data is to write a background jump that gradually updates some number of records at a time. It could be 100 records every 10 seconds, or higher or lower depending on your needs and what your database can handle. Once you have backfilled tenant_id on all of your models it's also a good idea to add a not-null constraint to each of the tables for it.
Get your primary keys in order
Now that all your data is ready we need to update some of your keys to ensure they work and help us enforce referential integrity. In order to do this you'll want to update primary and foreign keys to be composite keys. Let's look at an example of this, assume you have the following structure on a single node Postgres database:
CREATE TABLE leads (id serial PRIMARY KEY,
first_name text,
last_name text,
email text);
After adding tenant_id the table would now look something like:
CREATE TABLE leads (id serial PRIMARY KEY,
tenant_id integer,
first_name text,
last_name text,
email text);
And now you'll want to change the primary key to include both the tenant_id, and it's original primary key:
CREATE TABLE leads (id serial,
tenant_id integer,
first_name text,
last_name text,
email text,
PRIMARY KEY (tenant_id, id));
Flip to “Read mode” live—to decouple code changes from database changes
It's always a good idea to decouple code changes from database changes. For this reason, we encourage once you have your tenant_id in place and all code changes to reference your tenant when querying, so you can deploy your application with Postgres to make things work as if things were already sharded within Citus.
It is of note that for some applications that have extensive index usage may throw things out of whack. One option is to re-write your indexes to include tenant_id as well, though the statistics may result in different performance. This could be better or worse performance. The short is, definitely try to flip all the code live, but do so gradually and monitor performance as you do.
But how do I cutover without days/hours of downtime?
This all depends on the database you're migrating from and the size of your database. If your database is under 100 GB (of raw data, not including the indexes) then the simplest option is a dump and restore. This is quite safe and will likely take you around 30 minutes end to end.
If your database is much larger in size, let’s say 1 TB, then the cutover does become more complicated. Fortunately we have some tools in place to help you here. Because Postgres is awesome, we're able to leverage the logical decoding infrastructure in Postgres (available in Postgres 9.4 and up) to stream directly into a Citus Cloud cluster. It can still take a day or two for the dump plus ongoing stream to get caught up, but because it's an ongoing stream you can get it in place then let it run until you're ready for cutover.
If you're looking to go with option 2 then feel free to get in touch with us as we can help.
Game day for your database migration
You've put in lots of work, you've practiced, rehearsed, and run scrimmages. Okay... sorry for all the sportsball references. The short is, you're ready to cutover your production database to a new one in order to get more performance and better scaling going forward. During the cutover process you'll want to:
- Pause traffic to the database
- Ensure your replication lag doesn't exist
- Update your
DATABASE_URLto the new Citus cluster - Make sure you have your VPC/IP whitelisting configured
- Reset any sequences on your new database to current values
Flip it live, then make sure to keep an eye on things.
We want you to never have to worry about scaling your database again
At Citus, our mission is to make it so you never have to worry about scaling again. That’s why we call Citus “worry-free Postgres”.
Obviously the easier it is for you to migrate from your single-node Postgres database onto Citus, well, the easier it is for your SaaS application (and your customers!) to reap the performance benefits of scale-out compute, memory, and disk resources—plus the efficiencies of our parallelized queries. Hence this blog post. We want to make sure that those of you considering a move to Citus can leverage lessons learned by those who have come before you.
Have questions about how to make a database migration as simple as possible? Just contact us and let us know: we’ll be happy to help.