The schedule is out 🗓️ for POSETTE: An Event for Postgres 2026!
Wouldn’t it be great if you could run SQL queries on your data in DynamoDB? While this isn’t possible directly, there is an alternative: With Podyn, you can automatically replicate the schema, data, and changes in your DynamoDB tables to Postgres. Once your data is flowing into Postgres, you can start using a wide array of features including views, indexes, rollup tables, and advanced SQL queries. And if you chose Dynamo because you needed scale beyond what you thought a single Postgres instance could provide, you can replicate it into Citus.
Whether you want to query data in DynamoDB, or migrate from DynamoDB to Postgres, podyn can continuously keep postgres in sync without having to set up a database schema.
Example usage: Replicating DynamoDB into Citus Cloud
Let's walk through an example of replicating DynamoDB table to a Citus Cloud formation.
To get started using DynamoDB, you first need to set up credentials for the AWS SDK. In the examples below, we use the sample data from the DynamoDB documentation.
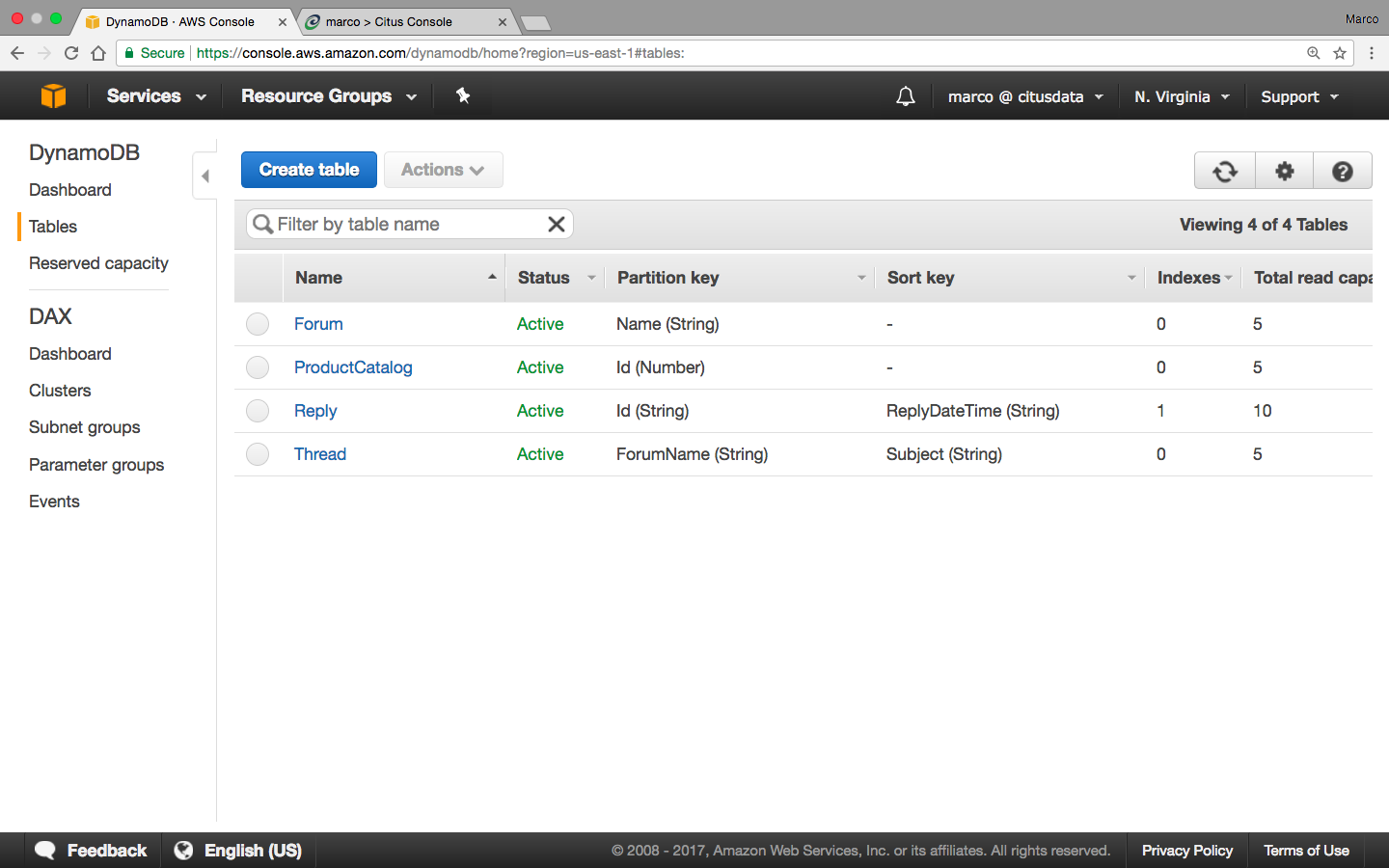
Using Citus Cloud, you can easily set up a Citus formation in just a few minutes.
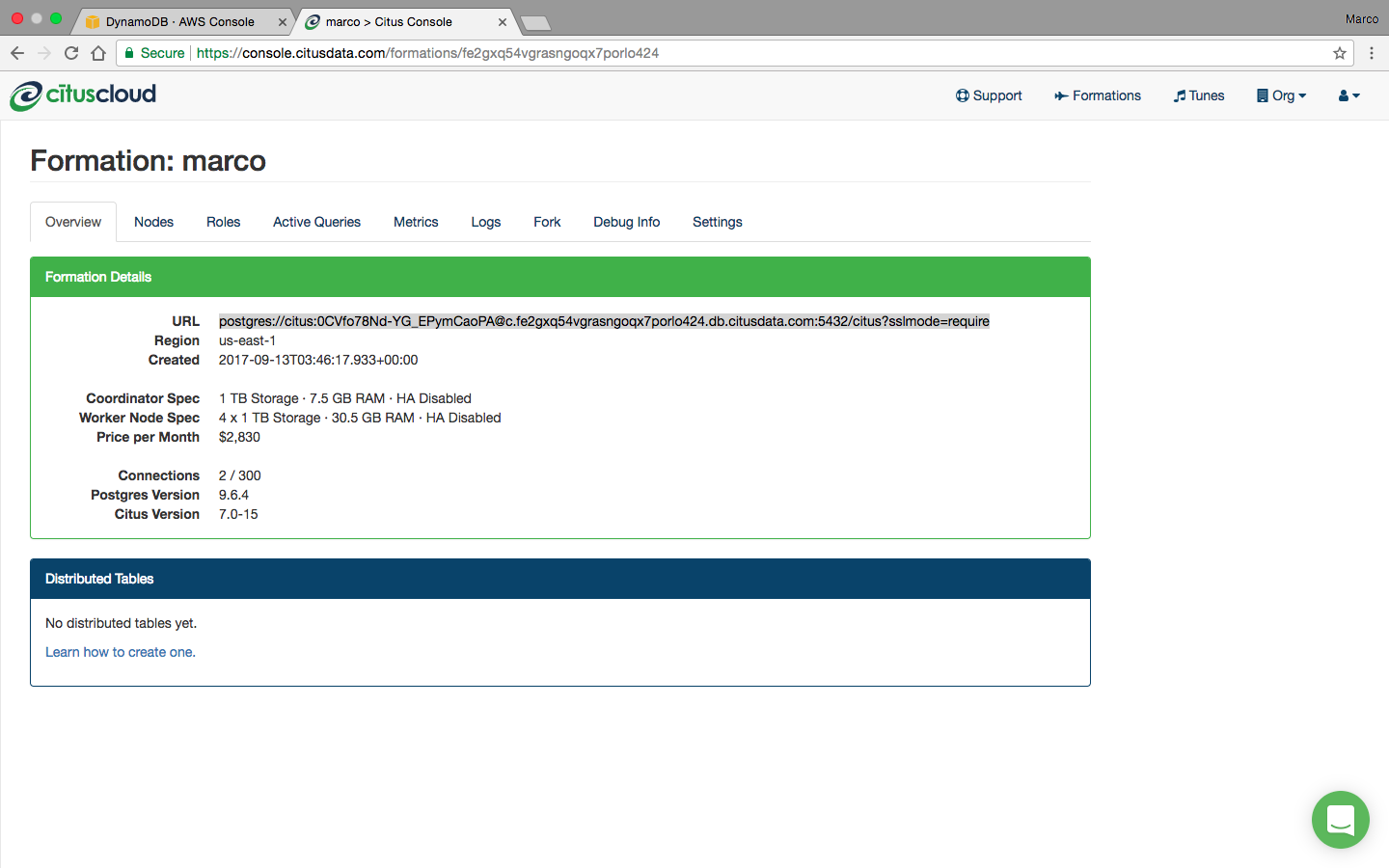
In the Citus Cloud console, you can find a postgres URL for psql. To use the URL with podyn, you need to translate it to JDBC format by specifying the user and password as arguments:
$ export PGURL=postgres://citus:0CVfo78Nd-YG_EPymCaoPA@c.fe2gxq54vgrasngoqx7porlo424.db.citusdata.com:5432/citus?sslmode=require
$ export JDBCURL=jdbc:postgresql://c.fe2gxq54vgrasngoqx7porlo424.db.citusdata.com:5432/citus?sslmode=require&user=citus&password=0CVfo78Nd-YG_EPymCaoPA
The first step is to replicate the schema and the data. By adding the --citus option, podyn will automatically call create_distributed_table to create distributed tables. Below is how we replicate all tables in us-east-1:
$ export AWS_REGION=us-east-1
$ ./podyn --schema --data --citus --postgres-jdbc-url $JDBCURL
Constructing table schema for table Forum
Constructing table schema for table ProductCatalog
Constructing table schema for table Reply
Constructing table schema for table Thread
Replicating data for table Forum
Replicating data for table ProductCatalog
Replicating data for table Reply
Replicating data for table Thread
Adding new column to table Thread: "Views" numeric
Adding new column to table Thread: "Message" text
...
podyn automatically creates tables and indexes and uses COPY to load data. Whenever podyn encounters a key it hasn't seen before, it adds a new column. Complex data types in DynamoDB (list, map) are stored as jsonb columns, while simple data types use text, numeric or bool.
On the Citus formation, you can now see tables that correspond to DynamoDB tables.
$ psql $PGURL
citus=> \d
List of relations
Schema | Name | Type | Owner
--------+--------------------+-------+----------
public | Forum | table | citus
public | ProductCatalog | table | citus
public | Reply | table | citus
public | Thread | table | citus
public | pg_buffercache | view | postgres
public | pg_stat_statements | view | postgres
(6 rows)
citus=> SELECT * FROM "Forum"; Name | Category | Threads | Messages | Views
-----------------+---------------------+---------+----------+-------
Amazon DynamoDB | Amazon Web Services | 2 | 4 | 1000
Amazon S3 | Amazon Web Services | | |
(2 rows)
Once you've completed the initial data load, you can use the same tool to continuously replicate changes:
$ ./podyn --changes --postgres-jdbc-url $JDBCURL
Replicating changes for table Forum
Replicating changes for table ProductCatalog
Replicating changes for table Reply
Replicating changes for table Thread
Replicated 5 changes to table ProductCatalog
Replicated 2 changes to table Forum
...
It may take a few minutes before changes start replicating.podyn first sets up several tables in DynamoDB in which it stores checkpoints, to make sure it doesn't replicate the same changes again if it restarts. Once replication has started, it usually takes less than a second before you see a change in postgres.
Tips for using podyn
Postgres likes lowercase column names. Uppercase column names always need double quotes. To automatically make all columns lowercase you can use the -lc option. Table names do keep their original case.
If you use a lot of different keys in your DynamoDB items, then you may not want all of them to become columns. In that case, you can use the -m jsonb option, which will create simpler schemas with a single jsonb column containing the entire DynamoDB item.
By default, podyn uses a scan rate of 25 read units for the initial data copy. To speed up the data copy, you may want to increase your read capacity on DynamoDB and adjust the scan rate accordingly using the --scan-rate option. Replicating changes does not consume read capacity, so you can lower the read capacity once the data copy is done.
You don't have to choose between scale and SQL
In the past you often had to make a hard choice between functionality (SQL) and scale (NoSQL) for your database. If you chose scale, you'd hit a point where you want more functionality. If you chose functionality, you'd hit a point where you want horizontal scale.
It's easy for us to say that you can now get the functionality of a SQL database with horizontal scale using Postgres and Citus, but we know you cannot simply change to a different type of database overnight. podyn aims to make it easier for DynamoDB users to start taking advantage of the functionality of a SQL database, at any scale.
Note that podyn is a relatively new tool. If you have any feedback on it be sure to let us know or post issues on the podyn GitHub page.
