POSETTE 2025 is a wrap! 🎁 Thanks for joining the fun. Missed it? Watch all 42 talks online.
A key part of running a reliable database service is ensuring you have a good plan for disaster recovery. Disaster recovery comes into play when disks or instances fail, and you need to be able to recover your data. In those type of cases logical backups, via pg_dump, may be days old and in such cases not ideal for you to restore from. To remove the risk of data loss, many of us turn to the Postgres WAL to keep safe.
Years ago Daniel Farina, now a principal engineer at Citus Data, authored a continuous archiving utility to make it easy for Postgres users to prepare for and recover from disasters. The tool, WAL-E, has been used to keep millions of Postgres databases safe. Today we're excited to introduce an exciting new version of this tool: WAL-G. WAL-G, the successor to WAL-E, was created by a software engineering intern here at Citus Data, Katie Li, who is an undergraduate at UC Berkeley.
Introducing WAL-G from Citus, the successor to WAL-E
WAL-G is a complete rewrite that provides the same functionality as WAL-E, but boasts performance improvements of 4x faster restores on recovery. WAL-G brings:
- Parallelization on restore for performance improvements
- Backwards compatibility
- Safety enhancements that check for incompletely restored backups
Let’s dig in deeper to all that’s new and improved with WAL-G.
4X Faster Disaster Recovery for your Postgres database
The goal of WAL-G was always to provide a noticeable improvement in terms of performance over WAL-E, and not just a rewrite for the sake of a rewrite. We sought to either reduce the footprint of the process that was running, or improve restore times, and if at all possible accomplish both.
We’re happy to say that WAL-G excels at both objectives—giving your database more resources and delivering faster restores from archives.
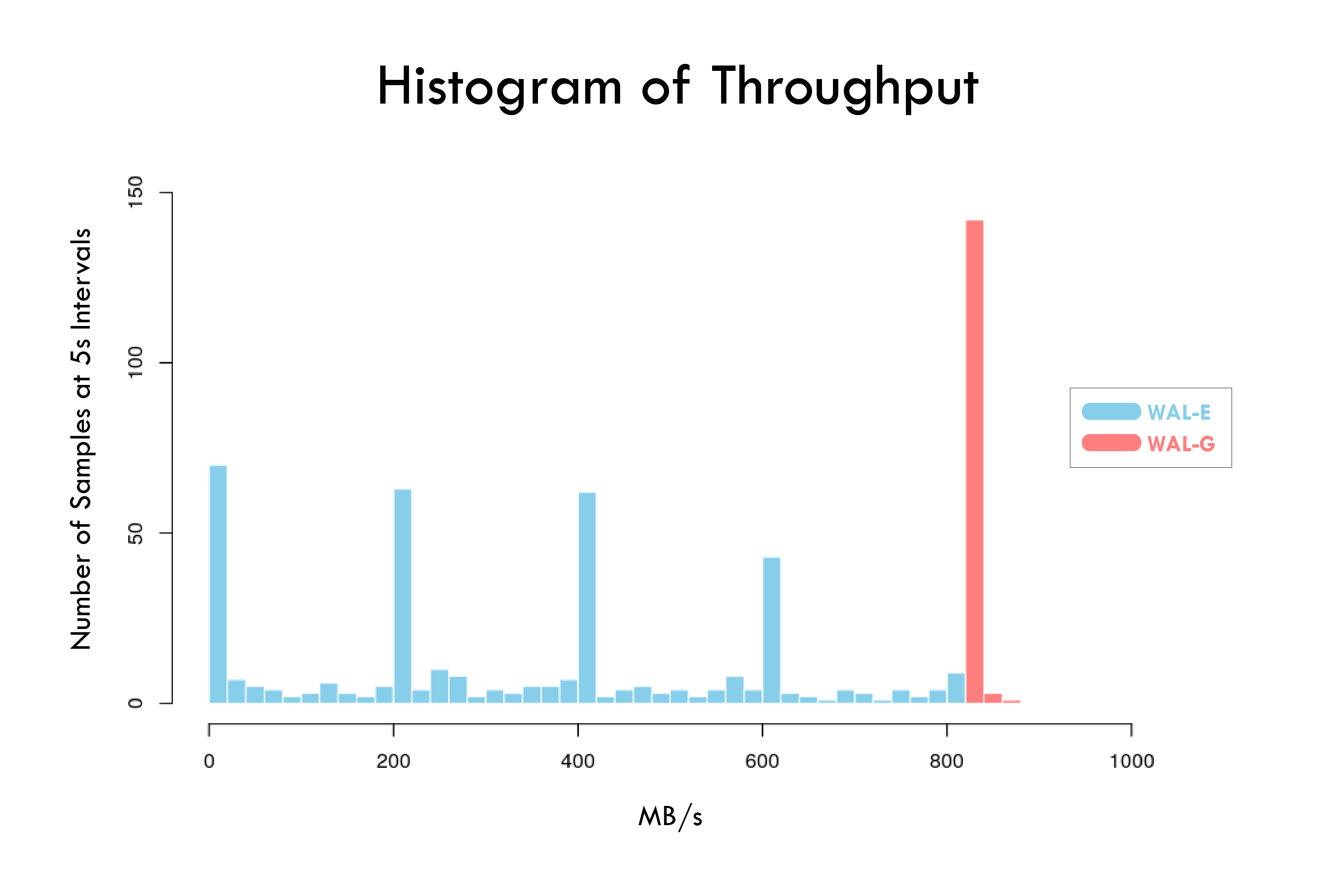
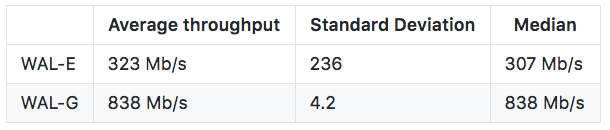
The figure above shows the distribution of throughput over the course of a restore by both WAL-E and WAL-G. As one can see, WAL-G offers consistent write performance at 95% of the theoretical maximum that an r4.8xlarge is advertised to offer (875 MiB/s), with virtually no deviation, unlike WAL-E. On i3.8xlarge we observed performance improvements as high as 7x.
So, how exactly did we accomplish the performance improvements?
Full rewrite of WAL in Go instead of Python
WAL-G is a rewrite from the ground up, written in Go instead of Python. Switching from Python to Go was largely due to how Go competes in terms of performance:
Go programs are compiled whereas Python programs are interpreted. Go’s standard library is written with performance sensitivity in mind. Go’s design is conducive to low-overhead multithreading, as opposed to Python’s subprocess or multiprocessing module.
A large influence of the design of WAL-G was to avoid having to use pipes and external processes like WAL-E does. WAL-E compresses using lzop as a separate process, as well as the command cat to prevent disk I/O from blocking. When analyzed with perf, WAL-E’s major bottleneck was the number of memory copies it had to complete per archive. In addition, pipe buffers for WAL-E had to be set to be large; this process has grown all the more difficult over the years as Linux has enforced new limits on pipe buffer allocation. WAL-G sidesteps pipe usage completely by linking Go libraries directly, such as for tar creation and lz4 compression.
Deeper into the design of WAL-G
Handling compression and tar creation internally greatly simplifies the design of WAL-G, from WAL-E’s 6.5k lines of code to WAL-G’s 1.5k. In addition, the development of a modern AWS SDK with better documentation resolved some of the more tricky parts of WAL-E with a mere few lines of code.
At the time of creating WAL-E, Amazon did not yet have flexible support for streaming, nor parallel uploads to S3, nor were SDKs for interacting with AWS as robustly maintained. Thus in order to achieve parallel uploads, WAL-E created temporary files, determined the sizes, and then notified AWS about them ahead of time. These files later get removed, but in rare occasions, clean up would fail so the files would leak prolifically. If these files were synced to disk, thrashing would also pose as an additional issue. Some of the newer AWS SDKs, including the Go SDK, has built-in management of multi-part uploads that allow programs to enjoy high performance with low complexity.
Better backups for all with WAL-G from Citus FTW
Protecting you from incompletely downloaded backups is a new feature included in WAL-G. During extraction pg_control is restored last, so that the server cannot be started before every other file in the backup has been downloaded and flushed to disk.
The handling of pg_control therefore differs when writing the backup, but WAL-G can still extract WAL-E version of archives. When extracting WAL-E archive versions with WAL-G, it is left to the user’s discretion to ensure the completion of the backup restoration.
Additionally, WAL-G uses the "non-exclusive" backup mode offered by Postgres 9.6 and later instead of the “exclusive” mode. Previously, exclusive backups required cleanup if Postgres stopped for any reason, requiring the intervention of deleting the file backup_label to start the database again. Using the non-exclusive mode solves these issues by allowing WAL-G to write the contents of the backup_label and tablespace_map from a Postgres query rather requiring those files to be written to disk.
WAL-G also relies more on unit tests as opposed to integration tests. WAL-E’s integration tests were often slow and relied upon good network conditions; also, the WAL-E integration tests did not allow for controlled fault injection. By mocking out certain parts of WAL-G, such as uploading to S3, testing potential errors becomes easy and straightforward. WAL-G also comes with a number of bespoke testing utilities, such as a random data generator, to ease future development.
What’s next for WAL-G?
As of now, WAL-G does not support parallel uploads or downloads of WAL files, while WAL-E is able to upload and download several WAL files at once. Parallel uploads/downloads will be implemented in WAL-G in the future. Furthermore, WAL-E was able to use the external program pv to perform rate limiting for uploads via pipes. A major design goal of WAL-G was to avoid pipelining and the copies required by it. Without pipelining in place, rate limiting will be added separately for WAL-G uploads in the future.
Special thanks
Our team at Citus wants to commend Katie Li—our software engineering intern on the cloud team—for her solid design and implementation work creating WAL-G. About to start her junior year at UC Berkeley as a Computer Science major, Katie has delivered a useful new version of WAL-E for Postgres which benefits not only our Citus customers but the entire Postgres community.
WAL-G is available as open source under the Apache 2.0 license—and (of course) WAL-G can be found on github.