The schedule is out 🗓️ for POSETTE: An Event for Postgres 2026!
Citus is Postgres that scales out horizontally. We do this by distributing queries across multiple Postgres servers—and as is often the case with scale-out architectures, this scale-out approach provides some great performance gains. And because Citus is an extension to Postgres, you get all the awesome features in Postgres such as support for JSONB, full-text search, PostGIS, and more.
The distributed nature of the Citus extension gives you new flexibility when it comes to modeling your data. This is good. But you’ll need to think about how to model your data and what type of database tables to use. The way you query your data ultimately determines how you can best model each table. In this post, we'll dive into the three different types of database tables in Citus and how you should think about each.
Distributed tables
We're going to start with a distributed table, which is the type of table you probably think of first when you think of Citus.
In Citus, a distributed table is a table that is spread across multiple server nodes. We do this by ‘sharding’ the database into multiple smaller tables, called ‘shards’, that we then distribute across different physical nodes.
For example, if you choose to create a Citus distributed table such as an orders table with a citus.shard_count of 48, then your database would be split into 48 shards (i.e. 48 smaller tables)—and then if you had a 2-node cluster then you would have 24 shards on one node and 24 shards on the other. (If you’re curious to learn more about sharding Postgres databases, there is a primer just for you.)
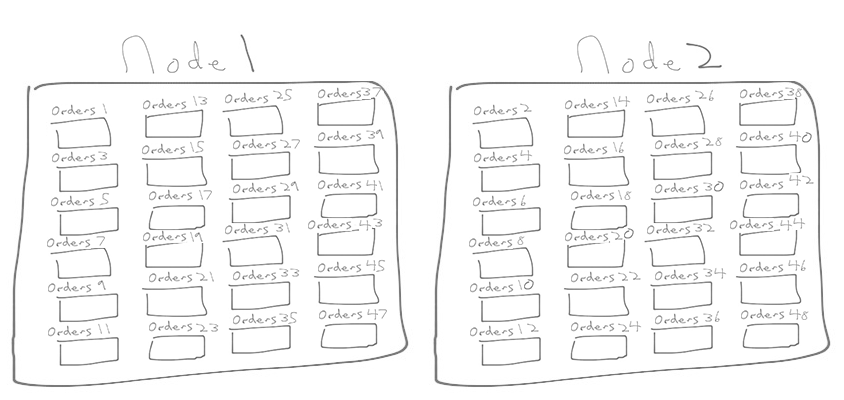
With a distributed table, you do need to specify the key you're going to shard your data by. The good news is that SaaS applications often have some natural distribution key. And when you have a natural distribution key for your tables, it can make sense to shard all or most of your tables by this key, so that your data is co-located.
If you manage an application like Shopify or Etsy—or if you develop a B2B app like Salesforce.com or Marketo—the data for each of your customers is unique and separate. As a result, for the most part, data from one of your customers will not need to interact with data from your other customers.
Because each of your customers (‘tenants’) has data that can be kept separate from each other, the tenant_id or customer_id makes a natural distribution key on which to shard the data. We call these types of applications ‘multi-tenant’ applications and find that many SaaS businesses have created ‘multi-tenant’ applications.
So for these types of SaaS applications, when you specify a distribution key such as tenant_id or customer_id, Citus will:
- Take a hash value of that distribution key
- Identify the shard that the hash value lives in
- Route the data to that shard
With a distributed table in Citus, your data is spread out across multiple nodes, so that your application can benefit from more servers, more cores, more memory. And with our shard rebalancer, Citus makes it easy to “rebalance” how the shards are spread across the different server nodes when you add more nodes to your Citus cluster. Shard rebalancing with Citus helps you optimize the performance of your distributed database.
And with distributed tables, all tables that are sharded by a key such as customer_id can be easily joined with other tables that are sharded on the same distribution key.
Reference tables
In the example of a Shopify-type app, there are some tables that you would definitely want to set up as distributed tables, such as products, orders, and line_items.
But what about smaller tables that may relate to all of your customers? Perhaps you have a categories field? Maybe there is a small lookup table for order_statuses?
With tables that relate to all of your customers, you'll want to be able to join them in an efficient way. Which brings us to the topic of reference tables. Reference tables are tables that are placed on all nodes in a Citus cluster. Instead of being tied to the shard count, we keep one copy of the reference table on each node (as reference!) and which you can then join against.
When interacting with a reference table we automatically perform two phase commit on transactions. This means that Citus makes sure your data is always in a consistent state, regardless of whether you are writing, modifying, or deleting.
Reference tables are handy for tables that are the same for all customers, frequently joined against, often smaller (under 10 million rows), and less frequently updated.
Standard Postgres tables (sometimes called "local tables")
Because Citus is an extension to Postgres, we hook into the core Postgres APIs and adjust query plans as necessary. This means that when you use Citus, the coordinator node you're connecting to and interacting with is also a Postgres database. If you have tables that don't need to be sharded because they're small, you can leave these as standard Postgres tables, also known as "local tables". (Update as of Citus 10, you can now JOIN your local tables with distributed tables.)
To create standard Postgres tables, you don't have to do anything extra, since a standard Postgres table is the default—it’s what you get when you run CREATE TABLE. In almost every Citus deployment, we see standard Postgres tables co-exist with distributed tables and reference tables. The most common standard Postgres table is the users table which you use for user login and authentication, though we often see standard Postgres tables used for a mix of administrative type tables as well.
In Review: Three Types of Tables
We hope as you dig into Citus this guide gives you some good baselines for how to map your own tables in your application to the various database table types in Citus. As quick review:
- Distributed tables - Larger tables or tables that have a strong relation to other tables such as via foreign keys or joins
- Reference tables - Smaller tables which are the same across all of your users and are frequently joined against
- Standard Postgres tables - Tables that do not need to join with distributed tables, or smaller tables that exist for administrative sections of your application
Which Citus table type is right for you?
If you have any questions about how to scale out your Postgres database with Citus or how to model your data for a distributed database, we’re happy to help. We try to make it easy to adopt Citus too: Citus is available as open source and as a managed service: Azure Cosmos DB for PostgreSQL.
Just drop us a note if you want to explore whether Citus is right for you. Or join our Citus Public slack to join the Q&A with the Citus open source community.