📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
Update: This post was originally published in January 2013. We updated the post in 2017 to include the appropriate SQL commands you can use with Citus. The Citus extension to Postgres is open source and available to try via download or in the cloud via the Azure Cosmos DB for PostgreSQL managed service.
PostgreSQL's Full Text Search capability is an excellent example of a powerful, relatively new feature that Citus users are able to leverage. First introduced in PostgreSQL 8.3 and continuously improved since then, Full Text Search (FTS) provides the SQL semantics necessary to run keyword searches over a corpus of documents stored in a database. FTS executes these operations efficiently by enabling the use of GIN and GiST indexes . In addition, from our standpoint, one of the best features of FTS is that Citus makes it linearly scalable. Specifically, with Citus one can double the size of the search dataset and still satisfy the same SLAs simply by doubling the number of machines in the Citus cluster.
In this blog post we wanted to demonstrate using Full Text Search with Citus, but in order to do so we first needed to find an interesting dataset to use in our examples. After hunting around we eventually hit on the idea of using email archives from the PostgreSQL mailing lists. Besides having a nicely self-reflexive quality about it, we also thought this would provide a good opportunity to learn more about the PostgreSQL community. Early in the history of PostgreSQL project, these lists became the primary communication mechanism for both developers and users, and the collected archives in turn provide a unique opportunity to get a complete view of almost everything that has happened in the project over the past fifteen years.
Preliminaries
We obtained the raw data for this project by downloading compressed email archives from the PostgreSQL website. Next we used Python’s Mailbox module to convert each archive file into a CSV file, and then loaded these files into a two node Citus cluster using Postgres' \copy command.
Basic Analysis
Before analyzing the data with Full Text Search we first wanted to get answers to a more basic set of questions, such as: how is email divided between the lists, who are the most active list participants, and what is the probability that any given message is the first email in a thread? Since the data is already loaded into a relational database it is easy to answer all of these questions in a couple of minutes using basic SQL queries.
We quickly found that the dataset contains 722,614 messages spanning the fourteen year period from December 1996 to December 2012. Of the fifteen lists we looked at, the two most popular lists -- pgsql-general and pgsql-hackers -- account for slightly more than 65% of the overall total, making them the two most popular lists by a wide margin. It's interesting to note that these two lists are the default lists for user- and developer-oriented discussions respectively, and that the development list sees more traffic than the user list by roughly 6 percentage points.
We also found it useful to look at the breakdown between different message types on a per list basis. More than half of the lists we looked at consist of more than 60% response messages by volume, and several (including the high volume hackers list) approach the 80% mark. It's fairly intuitive that a higher percentage of response messages indicates that more genuine discussions are taking place on the list.
Another metric worth looking at is the probability that a thread has at least one response. Note that it's possible for this figure to differ quite a bit from the previous metric if the messages are skewed between those with zero response and those with lots of responses.
We next started investigating who was writing all of these emails. We found 35,625 distinct sender names, which means that each list participant contributes an average of approximately twenty emails. This figure is a bit misleading since we also found that the top one hundred most active participants were responsible for 375,297 emails, which is slightly more than half (52%) of the total. The differences between individual participants is even more pronounced if we focus solely on the top ten participants:
The first observation that jumps out from this graph is that Tom Lane writes a lot of emails, 82,565 emails to be exact, or roughly fifteen emails a day. In fact, Tom Lane has written so many emails that there's a greater than one in ten chance that a message selected at random from our dataset will be from Tom Lane. He is also the most active poster in eight of the lists we looked at (including general and hackers), and has been the overall top poster every year since 2000.
Since Tom Lane writes so many emails we thought it would be interesting to analyze his posting habits in more detail. The following scatterplot accounts for every email he sent to any of the fifteen different lists we looked at:
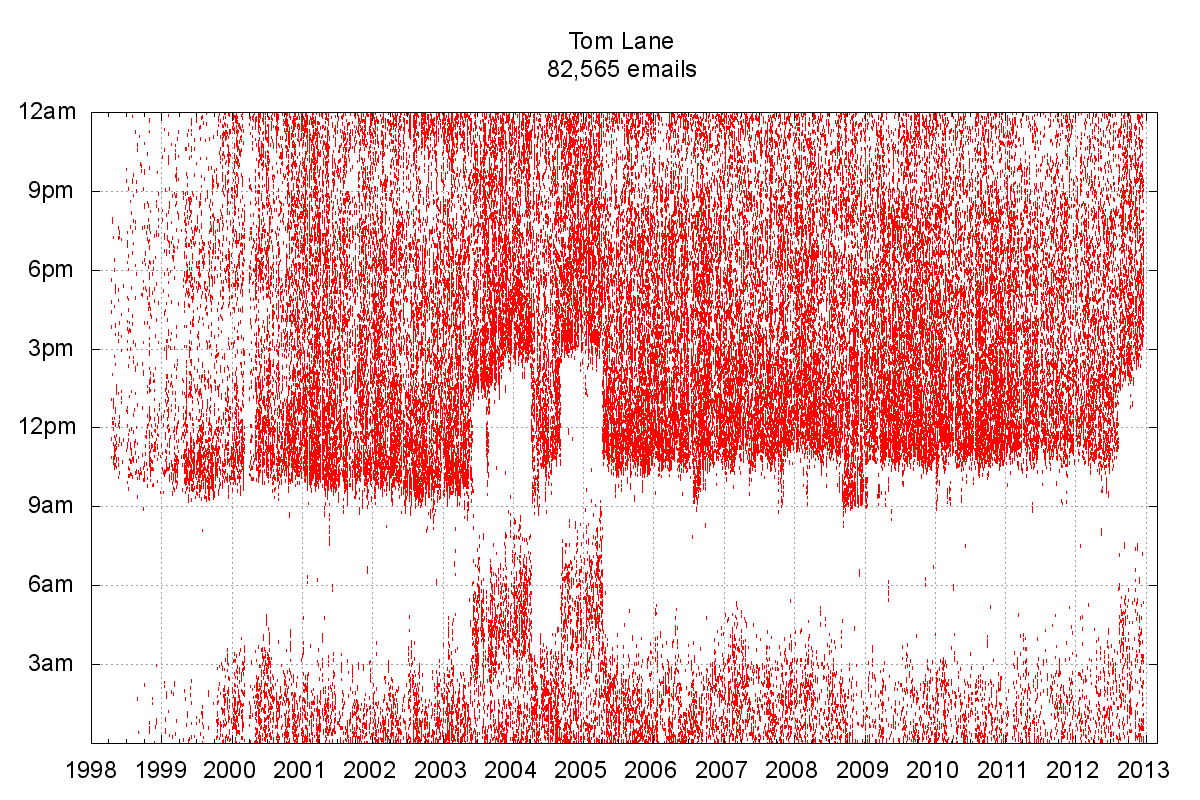
The plot makes evident that Tom Lane has a fairly well defined sleep-wake cycle, which dispelled our initial conjecture that 'Tom Lane' is actually PostgreSQL's version of Nicolas Bourbaki. It's also clear that Tom Lane's morning schedule is more well defined than his bedtime, and that he sends a majority of his emails in the morning.
In mid-2003 and mid-2004, Lane’s posting schedule appears to have shifted later in the day by roughly six hours, producing distinct spikes (and corresponding inverted troughs), a thought-provoking phenomenon.
We initially thought this was evidence of Tom relocating to another time zone, but we eventually settled on a far more pedestrian explanation: it looks like the time setting on the PostgreSQL mail server had shifted abruptly by six hours. Comparing the timestamps in the 'Received' and 'Date' headers from two closely spaced emails sent on 5/20/2003: 1, 2. proves this conjecture.
Looking at the Data with Full Text Search
Now that we have a basic lay of the land it's time to start analyzing the mailing lists using Full Text Search. The canonical FTS demo involves using this feature to quickly build a search engine on top of a corpus of text data contained in the database. However, it turns out that this has already been done with exactly the same dataset, so instead of tackling the more general case we are instead going to explore how FTS can be used to answer several very specific questions.
The first question we consider is how frequently PostgreSQL mailing list messages mention competitor systems such as MySQL, Oracle, etc, as well as how this has changed over time. In order to do this we need some way of determining whether an email contains the name of a competitor system. Here is how we accomplish this task with FTS:
SELECT
ts, msg_id, subject
FROM
pgsql_lists
WHERE
to_tsvector(user_body) @@ to_tsquery('mysql|oracle|sqlserver');
In this query the unfamiliar '@@' operator is PostgreSQL's boolean-valued full text search match operator. This operator applies an FTS query (tsquery) to a processed version of the original document that has been optimized for keyword searches (tsvector). The tsvector is produced by normalizing the tokens that appear in the input, a user-configurable process that typically includes mapping different variations of a word to a common root lexeme and eliminating redundant stop words. We can inspect the results of this normalization process by dumping the contents of a tsvector:
postgres=# SELECT * FROM to_tsvector('How does PostgreSQL compare to Oracle and MySQL?');
-----------------------------------------------
'compar':4 'mysql':8 'oracl':6 'postgresql':3
In this case the word "compare" was mapped to the lexeme "compar", and the stop words "How", "does", "to" and "and" were stripped out. We also see that the tsvector associates position information with each lexeme which is useful for performing proximity ranking on the search results.
Using a slightly more complicated version of this same query we were able to collect statistics from the pgsql-hackers and pgsql-general lists for the preceding fourteen years:
We chose to focus on the hackers and general lists since they closely reflect two different groups in the PostgreSQL community, namely PostgreSQL core developers and PostgreSQL users. Based on these results two points stand out: PostgreSQL users consistently mention competitor systems more frequently than PostgreSQL developers, while the frequency with which both groups mention competitor systems has been in steady decline since 2003.
Next, we thought it would be interesting to perform sentiment analysis on the emails using keywords borrowed from Ramiro Gomez's excellent blog post about analyzing GitHub Commit Messages. For example, we attempted to measure the emotion "surprise" by searching for emails that satisfied the following FTS query: "yikes|gosh|baffled|stumped|surprised|shocked". The lists of keywords we used for other emotions can be found in Ramiro's original blog post.
Before discussing the results it's important to concede that this is at best a poor man's version of sentiment analysis. The main drawback of this approach is that it ignores the context in which keywords appear, and is consequently susceptible to generating false positives. For example, the phrases "I am really shocked" and "I am not shocked at all" will both trigger our measure for surprise. "Bad language" isn't context dependent (it’s either there or it isn’t), and because of that property it's likely the most accurate statistic on this graph. As for the other more conventional sentiments, it's worth noting that the level of surprise exhibited by list participants has been steadily increasing, roughly tripling between 1998 and the present.
Before we wrap up we should compare Full Text Search to the other text search facilities that PostgreSQL provides. Astute readers are probably wondering why we even bothered to use Full Text Search when we could have easily generated the same results using pattern matching operators such as LIKE and SIMILAR TOO. For example, instead of using FTS filter clauses like this
to_tsvector(user_body) @@ to_tsquery('mysql|oracle|sqlserver')
We could have accomplished the same thing using a standard pattern matching operator:
lower(user_body) SIMILAR TO '%(mysql|oracle|sqlserver)%'
The benefits of using FTS become more apparent if we stop to consider the limitations of pattern matching. PostgreSQL's traditional search operators lack built-in linguistic understanding, which in turn forces the user to manage a host of additional details. For example we usually want keyword search queries to be case-insensitive, and in order to accomplish this we had to manually normalize (i.e lower case) both operands. We also want full text search queries to automatically respect word boundaries, and to accomplish that we would either have to rewrite our search string to explicitly include whitespace, or else accept the fact that some of our results may contain 'coracle' instead of 'oracle'. Finally, it would be great if our search mechanism knew something about derived words and synonyms. Our pattern matching query will find documents that contain 'SQLServer', but will fail to match documents that contain synonyms like 'sql-server' and 'mssql'. In contrast Full Text Search automatically normalizes document text as well as the terms that appear in queries, respects word boundaries, and can be configured to recognize synonyms via an extensible set of user-defined FTS dictionaries.
Other Resources
While doing background research for this blog post we found a variety of useful resources that we think are worth passing along to readers. For starters, two of the main developers responsible for FTS, Oleg Bartunov and Teodor Sigaev, gave a series of talks at PGCon conferences related to Full Text Search. Bartunov's talk Full Text Search in PostgreSQL from PGCon 2007 provides an excellent overview of the FTS interface as well as implementation details. Two years later Bartunov and Sigaev gave another talk at PGCon 2009 that describes several significant advances in FTS and also offers tips for designing FTS dictionaries. Last but not least, anyone who is considering using FTS should take a look at Magnus Hagander's talk from PGCon 2008 which describes using Full Text Search to power the documentation and mailing list search features on the PostgreSQL website. As an added bonus it turns out that the source code for the website (including FTS queries and configuration scripts) is available for download from the pgweb repository on GitHub.
On the basis of citations it appears that Eric Raymond's book The Cathedral and the Bazaar, first published in 1999, inspired much of the subsequent academic interest in the social dynamics of large open source software projects. In the following years different teams of researchers would use email archives to analyze the Apache Web Server and Mozilla projects, the R project, and the PostgreSQL project.
Finally, if you’re interested in learning more about sentiment analysis we recommend starting with Pang and Lee’s survey paper Opinion Mining and Sentiment Analysis.
Carl wishes to thank Hadi Moshayedi for contributing background research and results that are used in this article.
