The schedule is out 🗓️ for POSETTE: An Event for Postgres 2026!
pg_shard is a PostgreSQL extension that scales out real-time read and writes. This document talks about an earlier version of pg_shard that used Postgres' foreign data wrappers (FDWs) for sharding and scaling. We failed, learned, and succeeded in our second attempt.
Until now, our findings for the earlier version lived in internal emails and private GitHub repos. With the FDW-based sharding proposal surfacing again, we saw value in sharing our technical learnings.
At a high level, foreign data wrappers enable accessing a remote data source from PostgreSQL. Another way to think of them is that they are like MySQL's custom storage engines on steroids.
As an example, let’s say that the user issues a SQL query to compute the sum of purchases on a foreign orders table. PostgreSQL will then start a foreign scan on the foreign table, and call IterateForeignScan() to fetch remote tuples one by one.
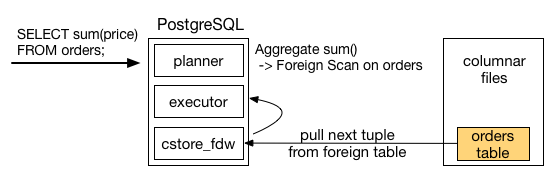
In this diagram, PostgreSQL’s executor begins a foreign scan, and iterates over rows by fetching one row at a time. After adding values in each row, the executor returns the final sum(). The primary observation here is that the executor pulls tuples from an external data source one tuple at a time, and then applies its computation.
Now, let's scale out this database using the current FDW APIs. In this example, we have three years worth of orders data partitioned across three machines.
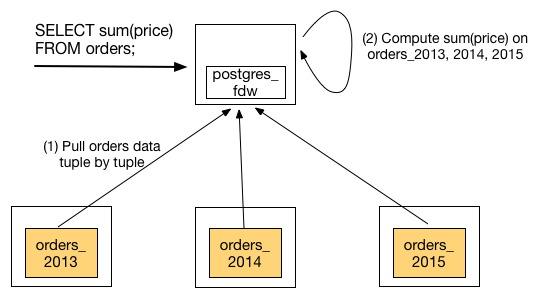
This approach naturally runs into scaling limitations. You'll end up pulling all data over the network and performing the final computation on a single machine. To overcome this limitation, instead of pulling the data to the computation, you need to parallelize your computations and push them to the nodes in the cluster.
Pushing down aggregate functions through the FDW APIs is one of the proposed changes for the upcoming PostgreSQL release. In this proposed method, the FDW APIs get cooperation from the planner so that each one of the three machines compute their own sum, and then the results get summed up for a second time.
Here's where things get tricky. This aggregate push-down approach only works for some queries. As an example, let's say that you wanted to count the distinct number of customer_ids in the orders table. To push this computation down, you need to first repartition the orders table on the customer_id dimension, and then push the count(distinct) to the repartitioned table.
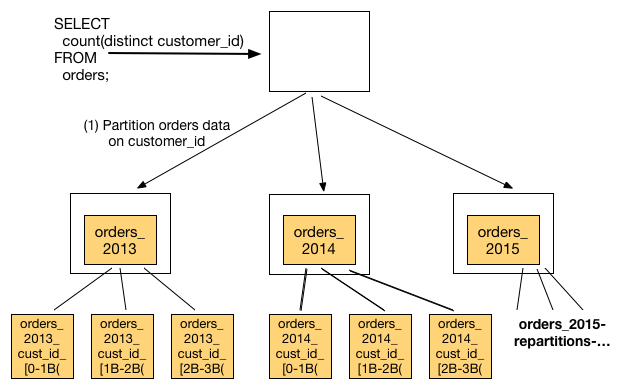
In this example, the coordinator node asks for the orders shards to be repartitioned into three buckets, where each bucket represents an interval of one billion hash tokens [1]. Then, this repartitioned data needs to be shuffled across the cluster and merged so that the count(distinct) could be pushed down to each machine. We’re basically applying a Map/Reduce on the orders table to parallelize the count(distinct) computation.
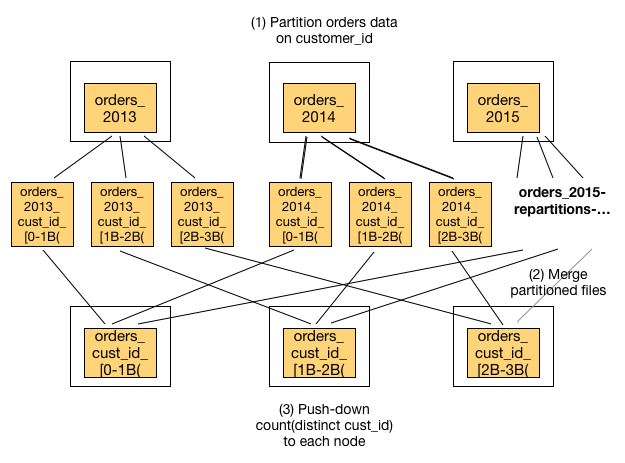
One important learning is that the foreign data wrapper APIs can’t push down the count(distinct) computation, even if they get full cooperation from the planner. Both the planner and executor APIs would need to fundamentally change to support parallelizing this computation. The same challenge exists for many other queries.
Let’s say that you have two large tables distributed over 3 machines. The first one is an orders table partition on time, and the second one is a customer table partitioned on customer_id. FDWs will have join pushdown logic in PostgreSQL’s next release, but they won’t be applicable for this query. To execute this distributed join between orders and customer tables, we first need to repartition the orders table on the customer_id dimension, and only then we can perform the join.
This limitation related to query parallelization was one of the four reasons we decided to revert from using FDWs in pg_shard. We also ran into three other limitations with the APIs. In summary:
Complex SELECT queries can’t be parallelized even after substantial changes to FDW APIs
UPDATE and DELETE operations are performed by first fetching records from the table scanning functions, and then going over the fetched records. If the user wanted to update a single row, this involved first pulling rows and then updating related records. This limitation isn't as fundamental as the one for SELECTs, but it's still there.
Our options to provide high availability (HA) characteristics became fairly limited. The FDW APIs were designed to read data from one remote data source. If we wanted to replicate data through any means other than streaming replication, or failover to another machine midway through a query, we'd end up writing logic to open connections and start new scans in the middle of a function that was supposed to read the next record.
When the user creates a distributed table, propagating DDL commands for each partition. The issue here was that regular and foreign PostgreSQL tables don't support the same features. For example, you can't create an index on a foreign table today. So, when we used a foreign table to mimic a distributed regular table, how do you allow and propagate CREATE INDEX commands? We ended up inferring and creating two tables behind the covers and swapping between them for this.
And the issue with these four limitations wasn't with foreign data wrappers. We wrote mongo_fdw and cstore_fdw, and we're quite happy with the contract FDWs provide. The problem was that we were trying to retrofit an API for something that it was fundamentally not designed to do.
Fortunately, we had Postgres. The PostgreSQL Extension APIs are unique among relational databases in that they enable you to extend, cooperate with, or override any database submodule's behavior. We could therefore change our design to use the planner and executor hook APIs, and we found that things followed nicely from there.
[1] The buckets in the count(distinct) diagrams correspond to hash token ranges. For example, the database takes one row from orders_2013, hashes the customer_id value, and gets a hashed value of 1.5B. It then puts it into the second bucket orders_2013_[1B-2B].
After the distributed shuffle, you end up with orders_cust_id[1B-2B] on machine 2. So all orders that belong to a particular / disjoint set of customers live on one machine. You can then push down the count(distinct customer_id) to each node, and then add up the results.
