📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
At this year's PGCon, we gave a talk on pg_shard that included a futuristic pg_shard demo: a distributed table with JSONB fields, backed by a dynamically changing row and columnar store. The demo is based on the GitHub archive data, which comprises a log of all events across all public GitHub repositories with detailed metadata in JSON format.
The pg_shard extension can store very large event logs in a PostgreSQL table by transparently sharding the table across many servers. We envision a use-case where new events are added to the table in real-time and frequent look-ups occur on data less than 7 days old. Data older than 7 days is compressed inside the database using cstore_fdw. A video of the pg_shard talk and demo is available at the end of this post.
In our demo, the events table was range-partitioned by time, such that each shard contains events for a specific hour of the day. One of the advantages of range-partitioning a table by time is that older shards are read-only, which makes it easier to perform certain operations on the shards, such as replacing the shard with an equivalent cstore_fdw table. We consider this demo to be futuristic since pg_shard does not yet have functions to create a range-partitioned table. It can only be set up by manually changing the pg_shard metadata tables, for which we created several PL/pgSQL functions.
The architecture used in the demo resembles a shard assembly line as shown below. In the first stage of the assembly line the shard is filled wih data, after that the shard is frequently read by SELECT queries, and after 7 days the shard is compressed for archival. When pg_shard receives an INSERT, it compares the timestamp of the time ranges of the shards in the metadata tables to find the shard for the current hour. Assuming the INSERTS only happen for the current time, then there is only ever one shard to which new data is being written. At the end of the hour, INSERTs will start going into a new shard. The shard for the next hour needs to be set up in advance, for example by an hourly cron job.
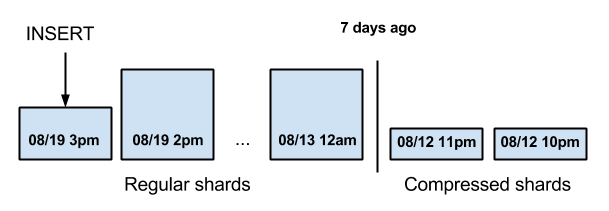
Compression is done by a periodic cron job, which goes through all shard placements with a time range that lies more than 7 days in the past. The compress_table function changes every uncompressed table into a cstore_fdw table in parallel across the cluster. Queries can continue to run while the data is being compressed. After compression, the storage size of a shard is typically reduced by around 50%.
The pg_shard demo presented here could be especially suitable for auditing and metering uses-cases, with various queries on new data to measure usage or detect abuse and archival of older data. When using CitusDB, you can also run parallel queries on the data for real-time analytics, for example to power an analytics dashboard. While some features for range-based partitiong are still missing, we will be adding better support for range-partitioning in upcoming releases and there there are similar set-ups of pg_shard and CitusDB already running in production.

Video of our pg_shard talk at PGCon 2015 - Demo starts at 30:00
