The schedule is out 🗓️ for POSETTE: An Event for Postgres 2026!
Our latest release to the Citus open source extension to Postgres is Citus 9.3.
If you’re a regular reader of the Citus Blog, you already know Citus transforms Postgres into a distributed database, distributing your data and SQL queries across multiple servers. This post—heavily inspired by the internal release notes that lead engineer Marco Slot circulated internally—is all about what’s new & notable in Citus 9.3.
And if you’re chomping at the bit to get started and try out Citus open source, just go straight to downloading the Citus open source packages for 9.3. Or head over to the Citus documentation to learn more.
Because Citus 9.3 improves our SQL support for window functions in Citus, we decided to add a few “windows” to the racecar in the Citus 9.3 release graphic below.

For those who prefer bullets, a summary of all things new in Citus 9.3
Citus 9.3 builds on top of all the HTAP performance goodness in Citus 9.2 and brings you advanced support for distributed SQL, operational improvements, and things that make it easier to migrate from single-node Postgres to a distributed Citus cluster.
Before we dive into what’s new in Citus 9.3, here’s a quick overview of the major themes:
- ADVANCED DISTRIBUTED SQL SUPPORT
- Full support for Window functions (enabling more advanced analytics use cases)
- Improved shard pruning
- INSERT..SELECT with sequences
- Support for reference tables on the Citus coordinator
- OPERATIONAL IMPROVEMENTS
- Adaptive connection management
- Propagation of ALTER ROLE across the cluster
- Faster, low-memory pg_dump
- Local data truncation function
Window functions
Window functions are a powerful SQL feature that enable you to run algorithms (do transformations) on top of your Postgres query results, in relationship to the current row. Window function support for cross-shard queries had become one of the top feature requests from our Citus analytics users.
Prior to Citus 9.3, Postgres window functions were always supported for router (e.g. single tenant) queries in Citus—and we also supported window functions in SQL queries across shards that used PARTITION BY distribution_column.
The good news: As of Citus 9.3, Citus now has full support for Postgres window functions, to enable more advanced analytics use cases.
If you’re not yet familiar with Postgres window functions, here’s a simple example. The SQL query below uses window functions (via the OVER syntax) to answer 3 questions:
- for the current person, whose birthday is right before that person’s birthday?
- how many people have a birthday in the same year as this person?
- how many people have a birthday in the same month as this person?
SELECT
name,
birth_date,
lag(name) OVER (ORDER BY extract(doy from birth_date)) AS previous_birthday,
count(*) OVER (PARTITION BY extract(year from birth_date)) AS same_year,
count(*) OVER (PARTITION BY extract(month from birth_date)) AS same_month
FROM
birthdays
ORDER BY
name;
Marco Slot reminded me: another way to understand window functions is to think about the Postgres planner, and exactly where in the process the window functions are handled.
This sketch from Julia Evans is a super useful way to visualize the order that things run in a PostgreSQL query. You can see in Julia’s zine that the SELECT is not at the beginning but rather, the SELECT is run after doing a GROUP BY.
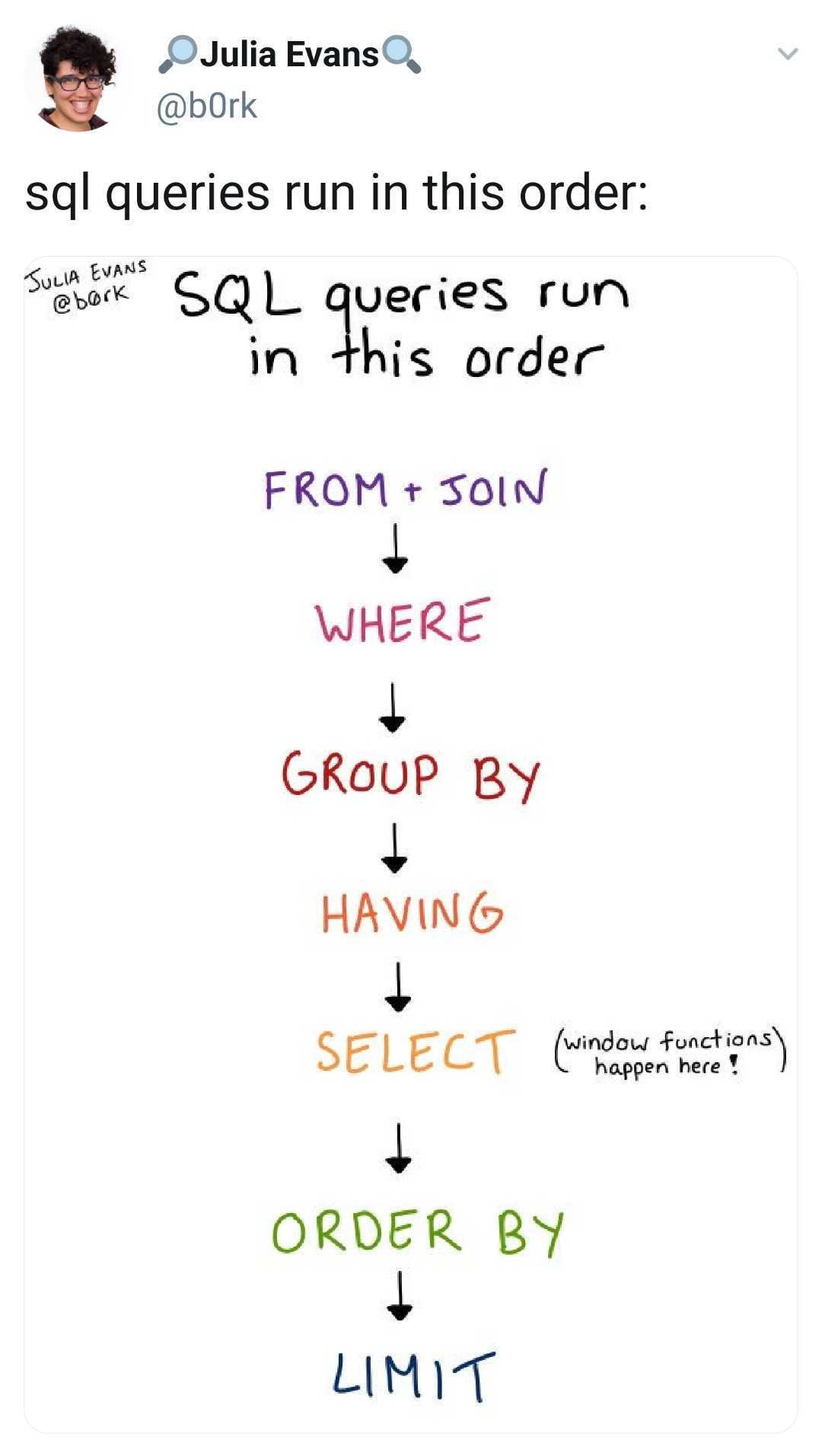
For those of you who work with analytics, Postgres window functions can be incredibly powerful because you don’t have to write a whole new algorithm or rewrite your SQL query to use CTEs (common table expressions).
Improved shard pruning
We received an amazing open source contribution on the Citus github repo from one of our Citus enterprise users who wanted their Postgres queries to be faster. Many of their SQL queries only need to access a small subset of shards, but when the WHERE clause involves expressions involving OR, some of their SQL queries were still querying all shards.
By expanding the shard pruning logic, our Citus customer (thank you, Markus) has made the shard pruning logic work with arbitrary Boolean expressions. So now, these types of Postgres queries will go to fewer shards (in this case, to just 2 or 3 shards instead of 32). The net result: faster query performance.
INSERT..SELECT with sequences
One of the most powerful commands in the Citus extension to Postgres is INSERT..SELECT, because it can be used for parallel, distributed data transformations that run as one distributed transaction.
Citus 9.3 enables inserting into a distributed table with a sequence, which was one of the few previous limitations of INSERT..SELECT on distributed tables.
Support for reference tables on the Citus coordinator node
To take advantage of distributed tables in Citus, it’s important that your SQL queries can be routed or parallelized along the distribution column. (If you’re still learning about how sharding in Citus works, Joe’s documentation on choosing the distribution column is a good place to start.)
Anyway, the need to route queries along the distribution column (sometimes called the “distribution key” or the “sharding key”) means that if you’re migrating an application originally built on single-node PostgreSQL over to Citus, you might need to make a few data model and query changes.
One of the ways Citus 9.3 simplifies migrations from single-node Postgres to a distributed Citus cluster is by improving support for using a mixture of different table types in Citus: reference tables, distributed tables, and local tables (sometimes referred to as “standard Postgres tables.”)
With Citus 9.3, reference tables can now be JOINed with local tables on the Citus coordinator.
This was kind of sort of possible before, but has become a lot better in Citus 9.3. Having the reference table on the Citus coordinator node and being able to JOIN between the local table and the reference table on the coordinator itself.
And if your application reads from the reference table on the Citus coordinator node, there won’t be a roundtrip to any of the Citus worker nodes, because you’ll be able to read directly from the coordinator (unless you actually want to round robin to balance the load across the cluster.)
In the example SQL below, after adding the coordinator to the Citus metadata, JOINs between local tables and reference tables just work. (And yes, we’re taking steps to remove references to “master” from Citus and to rename master_add_node to something else. Naming matters, stay tuned.)
-- Add coordinator to Citus metadata on the coordinator
SELECT master_add_node('10.0.0.4', 5432, groupid := 0)
-- Joins between local tables and reference tables just work
BEGIN;
INSERT INTO local VALUES (1,2);
SELECT * FROM local_table JOIN reference_table ON (x = a);
END;
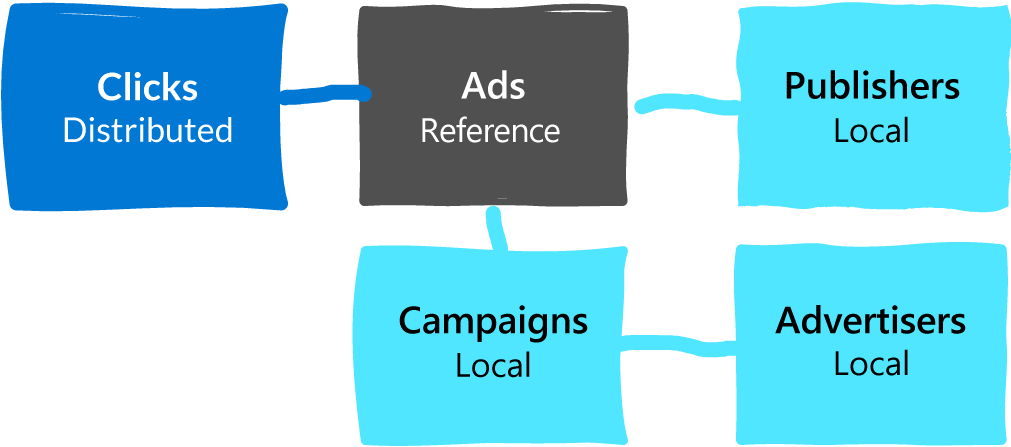
An example of how reference tables on the Citus coordinator can help
But what if you have tables like the ones in the schema below, in which:
clicks joins with ads
ads joins with publishers
ads joins with campaigns
Prior to Citus 9.3, for the example I explain above, you would have had to make all the tables either a distributed table or a reference table in order to enable these joins, like this:

But now with Citus 9.3, because you can now add a reference table onto the Citus coordinator node, you can JOIN local tables (aka standard Postgres tables) on the Citus coordinator with Citus reference tables.
Imagine if the clicks table is the only really big table in this database. Maybe the size and scale of the clicks table is the reason you’re considering Citus, and maybe the clicks table only needs to JOIN with the ads table.
If you make the ads table a reference table, then you can JOIN all the shards in the distributed clicks table with the ads reference table. And maybe everything else is not that big and we can just keep the rest of the tables as local tables on the Citus coordinator node. This way, any Postgres query that hits those local tables, any DDL, well, we don’t have to change anything, because the query is still being handled by Postgres, by the Citus coordinator acting as a Postgres server.
Update in 2021: New to Citus 10, we also support foreign keys between Citus reference tables and the local tables, too.
Interesting side-effect: distributed tables can sit entirely on Citus coordinator node
One interesting side effect of this new Citus 9.3 feature: you can now have distributed tables that sit entirely on the coordinator, so you can add the coordinator to the metadata and create a distributed table where all the shards are on the coordinator and the Postgres queries will just work. Just think how useful that can be for testing, since you can now run your test against that single Citus coordinator node.
Adaptive connection management (a super awesome operational improvement)
Those of you who already use Citus to scale out Postgres realize that Citus does much more than just shard your data across the nodes in a database cluster. Citus also distributes the SQL queries themselves across the relevant shards and to the worker nodes in the database cluster.
The way Citus does this: Citus parallelizes your distributed SQL queries across multiple cores per worker node, by opening multiple Postgres connections to each worker during the SQL query execution, to query the shards on each Citus worker node in parallel.
Unlike the built-in parallel query mechanism in PostgreSQL, Citus continues to parallelize queries under high concurrency. However, connections in PostgreSQL are a scarce resource and prior to Citus 9.3, distributed SQL queries could fail when the coordinator exceeded the Postgres connection limit on the Citus worker nodes.
The good news is, in Citus 9.3, the Citus adaptive executor now tracks and limits the number of outgoing connections to each worker (configurable using citus.max_shared_pool_size) in a way that achieves fairness between SQL queries, to avoid any kind of starvation issues.
Effectively, the connection management in the Citus adaptive executor is now adaptive to both the type of PostgreSQL query it is running, as well as the load on the system. And if you have a lot of analytical SQL queries running at the same time, the adaptive connection management in Citus will now magically keep working without needing to set up PgBouncer.
Propagation of ALTER ROLE across the cluster
In Citus 9.3, Citus now automatically propagates commands like ALTER ROLE current_user SET..TO.. to all current and new workers. This gives you a way to reliably set configurations across all nodes in the cluster. (N.B. You do need to be the database superuser to take advantage of this new feature.)
Faster, low-memory pg_dump for Citus
Citus stores the results of PostgreSQL queries on shards in a tuple store (an in-memory data structure that overflows into a file) on the Citus coordinator. The PostgreSQL executor can then process these results on the Citus coordinator as if they came from a regular Postgres table.
However, prior to Citus 9.3, the approach of writing to a tuple store sometimes caused issues when using pg_dump to get the entire table’s contents, since the full distributed table might not fit on the Citus coordinator’s disk.
In Citus 9.3, we changed the implementation of the COPY <table> TO STDOUT command, in order to stream tuples directly from the workers to the client without storing them.
Bottom line, if you need to pg_dump your Citus distributed database, now you can stream your Citus database to your client directly, without using a lot of memory or storage on the Citus coordinator node.
Local data truncation function
When calling create_distributed_table on a table on the coordinator that already contains data, the data is copied into newly created shards, but for technical reasons it is not immediately removed from the local table on the Citus coordinator node.
The presence of the local data could later cause issues, but the procedure for removing the old data was prone to mistakes and sometimes led to operational issues. In Citus 9.3, we introduced a new function, truncate_local_data_after_distributing_table, to make it easier to clean up the local data—which saves space and makes sure you won't run into situations where you cannot create a Postgres constraint because the local data does not match it.
Helping you scale out Postgres with Citus 9.3
By the time I publish this post, our Citus distributed engineering team will be well on their way to Citus 9.4. I can’t wait to find out what our Postgres team will bring to us next.
With the advanced support for distributed SQL, operational improvements, and things that make it easier to migrate from single-node Postgres to a distributed Citus cluster—well, with Citus 9.3, your window functions will just work, you don’t have to worry about deciding whether every table needs to be distributed or not, you can do pg_dumps more easily, adaptive connection management will improve your operational experience… In short, we think Citus 9.3 is pretty darn awesome. I hope you do, too.
