📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
Choosing a database isn't something you do every day. You generally choose it once for a project, then don't look back. If you experience years of success with your application you one day have to migrate to a new database, but that occurs years down the line. In choosing a database there are a few key things to consider. Here is your checklist, and spoiler alert, Postgres checks out strongly in each of these categories.
Does your database solve your problem?
There are a lot of new databases that rise up every year, each of these looks to solve hard problems within the data space. But, you should start by looking and seeing if they're looking to solve a problem that you personally have. Most applications at the end of the day have some relational data model and more and more are also working with some level of unstructured data. Relational databases of course solve the relational piece, but they increasingly support the unstructured piece as well. Postgres in particular
Do you need strong gurantees for your data? ACID is still at the core of how durable and safe is your data, knowing how it stacks up here is a good evaluation criteria. But then there is also the CAP theorem which you see especially applied to distributed or clustered databases. Each of the previous links is worth a read to get a better understanding of the theory around databases. If you're interested in how various databases perform under CAP then check out the Jepsen series of tests. But for the average person like myself it can be boiled down a bit more. Do you need full gurantee around your transactions, or do you optimize for some performance?
While it doesn't fully speak to all the possible options you can have with databases, Postgres comes with some pretty good flexibility out of the box. It allows both synchronous (guaranteed it makes it) and asynchronous (queued up occurring soon after) replication to standbys. Those standbys could be for read replicas for reporting or for high availability. What's nice about Postgres is can actually allow you to swap between synchronous and asynchronous on a per transaction basis.
Then there is the richness of features. Postgres has rich data types, powerful indexes, and a range of features such as geospatial support and full text search. By default yes, Postgres usually does solve my problem. But that is only one of my criteria.
How locked in am I to my database?
Once I've established that my database I want to know a bit more about what I'm getting myself into. Is the database open source is a factor. That doesn't mean I require the database to be open source, but it simplifies my evaluation. A closed source database means I'm committing to whatever the steward of that database decides. If the company is well established and is a good steward of the product a closed source database can absolutely satisfy what I need.
On the flip side open source doesn't immediately mean it is perfect. Is it open source but with an extremely restrictive license? Is there a community around it? Has it been getting new releases? All of these play into my level of comfort in trusting you with my data.
Can I hire for my database?
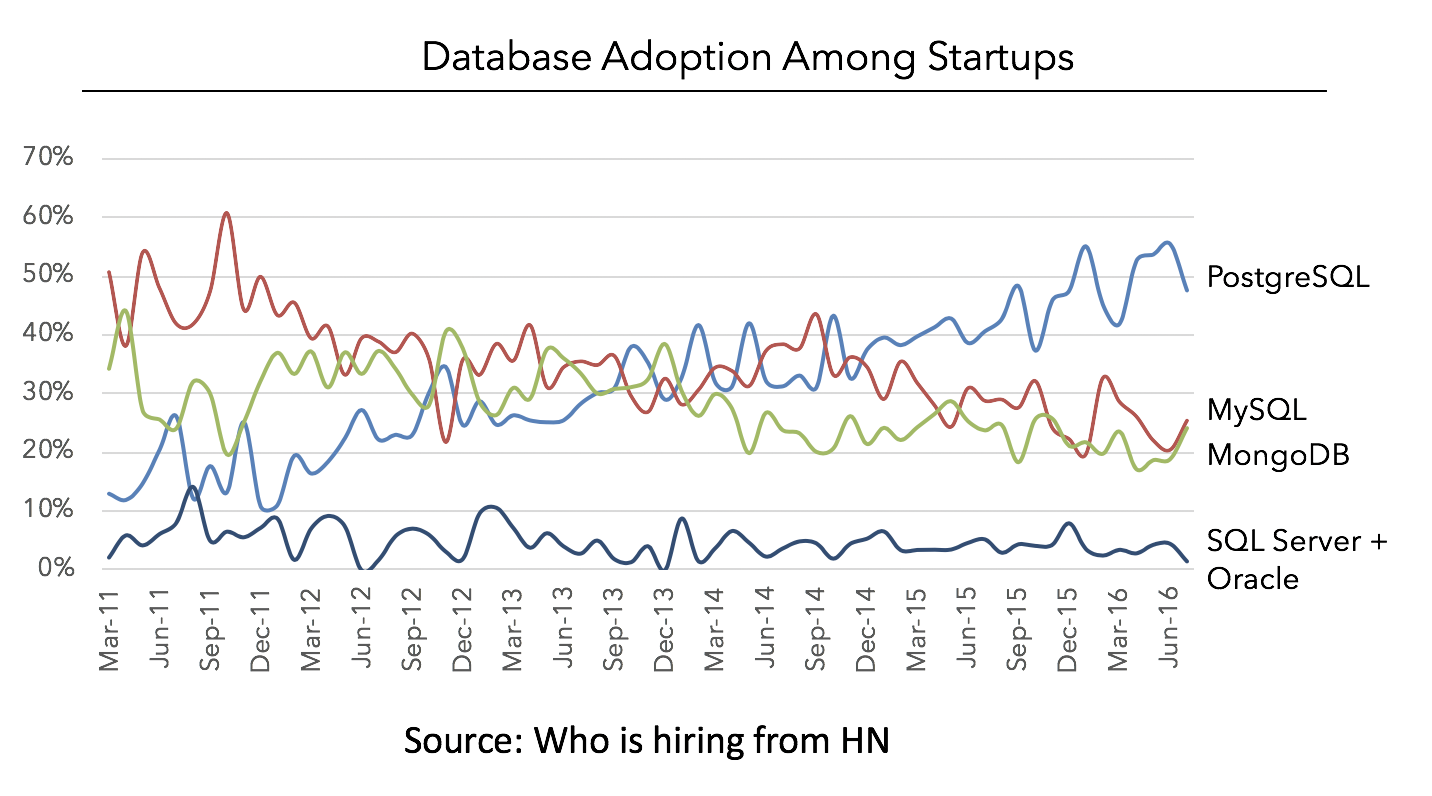
This one gets missed so often by early stage companies! It is the number one reason I like using open technologies and frameworks because I can hire someone already familiar with my tech stack. In contrast, with a home grown in house framework or database the ability to test knowledge is harder and the ramp up time is considerably more for a new hire. Postgres shines as bright as any database here. A look at Hacker news who is hiring trends, which I view as a leading indicator, from a couple years ago shows Postgres leading the pack of desired database skills. The number of people that know Postgres continues to increase each day. It is not a fading skill.
What does the future look like?
Finally, I'm looking at what my future needs will be combined with the future of the database. Does the database have momentum to keep improving and advancing? Does it not only have features I need today, but does it have features that can benefit me in the future without complicating my stack? I often favor a database that can solve multiple problems not just one. Combining 10 very specialized tools leads to a much more complex stack, vs. in Postgres if I need to layer in a little full text search I already have something that can be my starting point.
Does it scale is my final big one. If my business is expected to remain small this is no longer a concern, but I want to know what my limits are. Replacing my database is a large effort task, how far can I scale my database without rearchitecting.
Personally Postgres having a good answer to the scale question is what attracted me to join Citus over 3 years ago. It takes Postgres and makes it even more powerful. It removes the scaling question for you, so when I need to scale I have my answer.
These aren't the only criteria
I'm sure this is not an exhaustive list, but it is a framework I've used for many years. In most of those years I'm lead back to the simple answer: Just use Postgres.
What other criteria do you use when choosing your database? Let us know @citusdata