📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
Note: This is a guest blog post by Giuseppe “Pino” de Candia, the creator of Dynamo. We asked Pino to chime in with his thoughts on distributed databases and the trends he sees in this space. You can read more about Pino here.
When Ozgun, one of the founders of Citus Data, emailed me resources on scaling multi-tenant databases for B2B apps and asked me what I thought, all kinds of distributed systems tradeoffs started crossing my mind—along with memories of the forces that shaped Dynamo.
It’s been a decade since my team at Amazon worked on Dynamo, a highly available and scalable key-value store. By the time we started working on the project, Amazon was already going through two transitions.
First, Amazon was starting to operate at a scale that exceeded what could be delivered by regular data stores. In particular, our relational database at the time couldn’t handle the load generated by the website. Further, our database administrators had to periodically perform gymnastics to change the database schema and re-partition existing table partitions.
Second, Amazon was reworking its architecture to more efficiently serve a hundred million consumers. That work involved moving from a two-tiered web architecture to a service-oriented (SOA) one, where each service owned / defined the boundaries for one business unit. For example, the session service owned authentication-related logic and the shopping cart service was responsible for the items users added to their carts. As a result, the business logic defined ownership for the underlying data. Naturally, a service’s data could easily depend on other services’ and all services ultimately relied on a relational database to act as their source of truth.
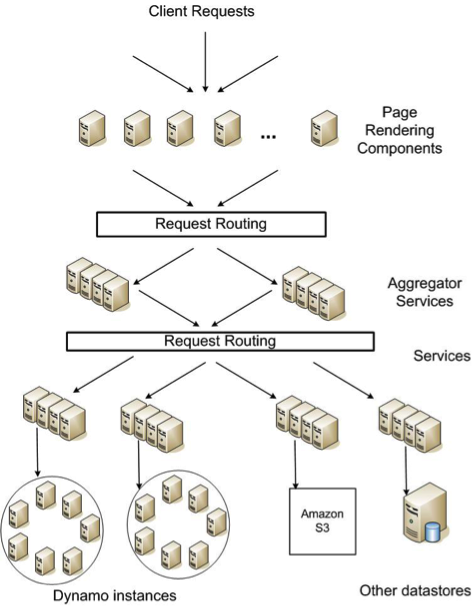
With Amazon’s traffic growing rapidly, we needed a solution that scaled, fast. We had two options at this stage: build a feature-rich database that scales, or deliver a scalable database based on simplifying assumptions about our requirements. At the time, moving fast was of the essence. We also had the benefit that we could make two related assumptions given Amazon’s architecture.
Query model: Dynamo targeted services that performed simple read and write operations to a data item. This data item was uniquely identified by a key (say user_id) and stored as a binary object. Operations didn’t span across these data items and applications needed to store objects that were relatively small in size. As an example, a user could only look at what was in their shopping cart, or add and delete items.
Compared to SQL, this query model offered a significant simplification. We could restrict the type of operations one could perform on the data store, particularly ones that had side effects or touched across multiple data items.
Data model: The fundamental reason we could simplify our query model or relax certain transactional semantics followed from our data model. At its core, Amazon.com operated a complex B2C business that had introduced complex relationships between “groups of data.”
For example, Amazon.com served web pages that were primarily related to Amazon’s catalog and inventory information. When you expressed interest in an item, Amazon would then keep this information in user-related datastores. Then, your order would be allocated to and fulfilled from a warehouse.
This complex relationship didn’t lend itself well to distributing the data on one or two dimensions. As a result, Amazon formalized those relationships between data through services and service APIs. At the time, Amazon had over a hundred services and each service maintained a flat schema (such as your shopping cart) that didn’t require a relational model.
The primary benefit where this simplification showed itself was around Dynamo’s consistency model. Taking a step back, one can roughly group the consistency model used in distributed databases into two groups:
- Eventual consistency, where any replica can take a write. If two replicas have different state, the database then looks to reconcile those differences.
- Strong consistency, where the database’s state moves forward in a lockstep fashion. To achieve this, the database could elect a primary node that serves writes or use a distributed consensus algorithm such as Paxos.
Dynamo provides eventual consistency, which allows for updates to be propagated to all replicas asynchronously. This enables a system that can always take writes and then reconcile any inconsistencies within data items through techniques such as vector clocks.
For example, the shopping cart application requires an “Add to Cart” operation that can’t be forgotten or rejected. If the shopping cart’s most recent state is unavailable, and a user makes changes to an older version of the cart, that change is still meaningful and should be preserved. At the same time, this update shouldn’t supersede the currently unavailable state of the cart, which itself may contain changes that should be preserved.
To make sure that all writes to the shopping cart are preserved, Dynamo uses vector clocks. Vector clocks capture causality between different versions of the same object. In Dynamo, when a client wishes to update an object, it must specify which version it’s updating. On a read operation, Dynamo will check if an object has multiple branches and will look to syntactically reconcile these branches into one. One can draw a crude analogy here to revision control systems such as Git, where users specify the branch they are checking changes.
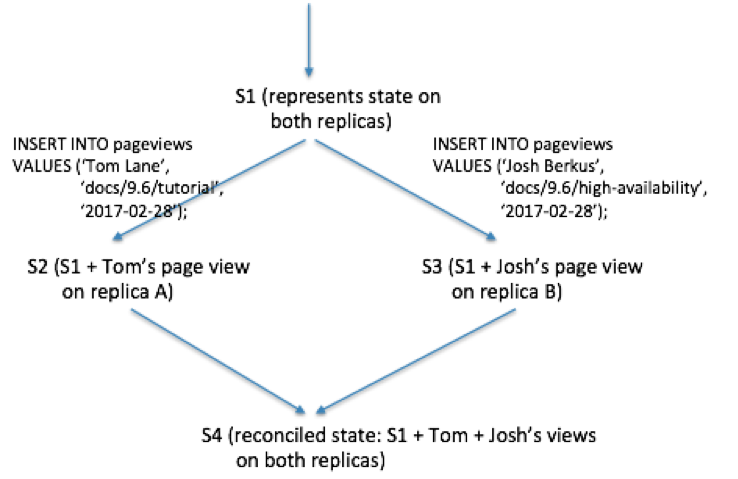
In the above example, Dynamo processed two write operations in parallel branches and then reconciled those changes. The final shopping cart incorporates all three write operations. The query model helps here because it only allows put() operations. In comparison, SQL allows for non-deterministic changes to data. In PostgreSQL for example, you can write INSERT or UPDATE statements that include functions with side effects, such as nextval(), now(), or random(). These type of functions make automatically reconciling write conflicts really hard.
If using SQL makes things hard, a data model that allows for arbitrary changes across multiple data items makes resolving write conflicts impractical. For example, imagine the following two queries that happened to run on different replicas in a distributed environment.
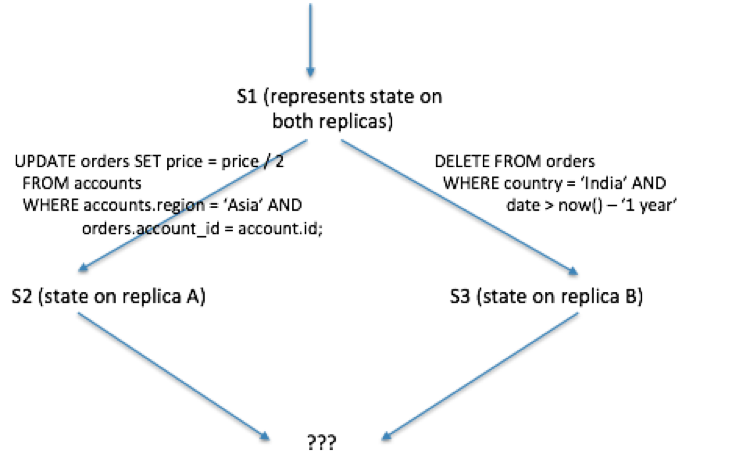
You can continue to extend on this example by imagining that these tables also have complex relationships with other ones. For example, what happens if the orders table has foreign key constraints on shipments and users tables? What happens if the foreign key constraint remains valid on one branch, but not on a combination of others?
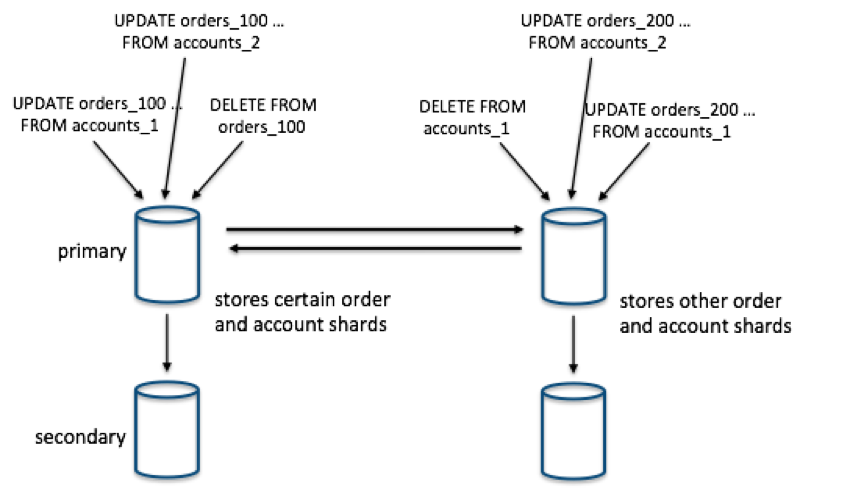
This is why relational databases pick a stronger consistency model, one where the underlying state progresses in a lockstep fashion. The most widely deployed implementation of this model is where writes are routed to a primary node, applied on the primary, and then propagated to secondary nodes. In this model, if the primary node fails, the database then promotes a new primary node in a few minutes and routes queries to the promoted primary.
Relational databases that appeal to different audiences—such as Oracle RAC and Postgres RDS—use this stronger consistency model to provide relational database semantics.
Now, this consistency model helps with resolving issues around replication, but it doesn’t help with horizontally scaling a data model that has complex relationships. For example, if you ran the previous commands on database tables that were distributed on multiple dimensions, you’d still need to ensure that they get executed in an ordered manner. You can serialize these commands or run sophisticated locking algorithms, but then you could hurt your performance (concurrency).
When I was comparing Dynamo's approach to Citus', these additional tradeoffs related to performance and query capabilities crossed my mind. Most of us in the industry categorize distributed databases according to where they stand in the CAP theorem, but I agree with Martin that that definition is too simplistic.
In practice, at least two other key properties come into the picture when you’re building a distributed database:
- What type of application will use this database? This has significant implications for your database’s query and data model and how feature-rich you’d like your database to be.
- How do you expect your performance to scale? What type of database operations need to scale well?
When we built Dynamo, our requirements and assumptions followed from Amazon’s own environment. In particular, we needed a highly scalable database to power parts of a complex B2C business. In this business, the underlying data didn’t have one or two natural dimensions that we could easily distribute the data on. Rather, Amazon switched over to a service-oriented architecture, where each service became responsible for a relatively simple schema and query model.
Comparatively, if you’re interested in scaling a multi-tenant database, you likely have a growing SaaS / B2B business. B2B applications lend themselves to a data model that has two important characteristics—and those two properties quite favor relational databases.
First, your SaaS / B2B application likely captures rich data related to each business or tenant that you serve. That is, you likely won’t serve as many users as you would have in a B2C application, but the data that you capture for each business will be richer. As a result, you usually end up with dozens of database tables that capture different aspects of the business that you’re serving. In this model, relational databases offer you transactions so that you can update related tables together, joins so that you don’t need to keep duplicated data, and foreign key constraints so that you can keep related data consistent.
Second, B2B data models have a natural sharding dimension to them. You can simply distribute your data based on the business or tenant identifier and then colocate data related to a particular tenant on a single machine. This ensures that operations such as transactions, joins, and foreign key constraints don’t pay the performance penalty associated with going over the network. This way, you can get key benefits that relational databases offer to you, at scale.
In summary, if you spend enough time designing and building distributed databases, you come to realize that the world doesn’t deal in absolutes. When the team at Citus Data shared with me resources on scaling multi-tenant databases, it reminded me that distributed systems problems are hard and involve trade-offs.
Both Dynamo and Citus are great databases, but they take very different approaches to scaling. These approaches are informed by the different B2C and B2B workloads they power. For Amazon, the B2C needs of the business influenced the tradeoffs made in creating Dynamo. Meanwhile, Citus is designed for B2B applications that need to scale to thousands of tenants while keeping all the benefits of a relational database.
