📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
It has been several months since the launch of Citus Cloud, and we’d like to share one part of its design with you. In particular, the fundamental unit of organization for our hosted service on top of AWS is concurrent state machines. In what follows we’ll walk through their use and implementation for Citus Cloud.
First, we’d be remiss if we didn’t acknowledge the great influence that working on Heroku Postgres had on the team. There are also a few talks on Heroku Postgres's design that you may find as interesting and useful information.
Citus Cloud is recently written from scratch. Because of this, it's a good time to provide guidance in how one can start writing similar systems.
An Example: A Server that Restarts
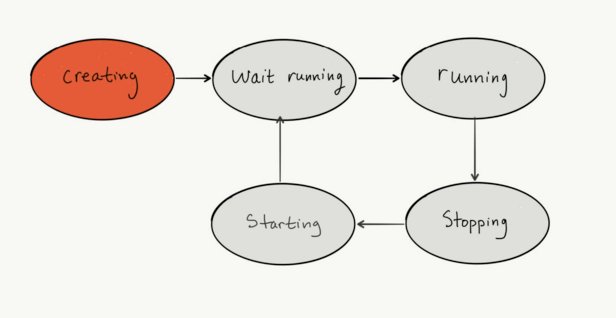
To orient ourselves, the following is pseudo-code of an abstract state machine, called Server. This state machine is for creating and restarting servers in some cloud provider:
Server
State: creating
cloud_create_instance
transition wait_running
State: wait_running
if not offline?
transition running
State: running
if offline?
transition stopping
State: stopping
cloud_stop_instance
transition starting_instance
State: starting_instance
cloud_start_instance
transition wait_running
 It's worth noting that each state's side effects, the
It's worth noting that each state's side effects, the cloud_ operations, are idempotent. They must also raise errors if they fail, to end execution of a state body. In practice, this is easy to adhere to in most cloud APIs.
The net result of these two properties is that the state machine can crash, or error, at any point in execution. A retry of the steps within that state will follow.
Implementation
With the abstract in mind, I'll translate this into implementation as seen in CloudPlane.
First, it's worth glossing over CloudPlane's physical resources. It requires Redis, Postgres, and two distinct processes running. One of those processes serves web requests. It is comparable in this respect to the most common-variety web application.
The web requests provide input to the state machine. The other runs the state machine code.
Second, the implementation is in Ruby. Ruby carries the following advantages that one should try to maximize:
- has a REPL, and a syntax amenable to its use.
- is terse
- has crucial mature libraries:
Sequel,Net::SSH, AWS SDKv2 - has easy fault injection via mocks and
rspec.
Without further ado, the translation. First, the SQL schema:
CREATE TABLE servers (
id uuid primary key,
region text not null,
state text not null,
instance_id text
);
We use the libraries Sequel (for ORM) and AASM (for state machine methods).
class Server < Sequel::Model
# Sequel defines accessors for all fields on a table,
# e.g. a reader for "id" or setter "instance_id=".
include AASM
def work
send('work_' + state)
save_changes
end
def work_creating
# Note how the client_token feature is used for idempotency.
ran = ec2.run_instances(..., client_token: id)
self.instance_id = ran.instances.first.instance_id
created
end
def work_wait_running
detect_online if online?
end
def work_running
detect_unavailable unless online?
end
def work_stopping
ec2.stop_instances(instance_ids: [instance_id])
stopped
end
def work_starting_instance
ec2.start_instances(instance_ids: [instance_id])
started
end
def online?
# A Stub. Examples of what to do: read fresh telemetry data
# or use Net::SSH to connect are examples of what to do here.
# CloudPlane uses the former approach.
end
def ec2
@ec2 ||= Aws::EC2::Client.new(region: region)
end
aasm column: :state do
state :creating, initial: true
state :running
state :stopping
state :starting_instance
state :wait_running
event :created do
transitions from: :creating, to: :wait_running
end
event :detect_online do
transitions from: :wait_running, to: :running
end
event :detect_unavailable do
transitions from: :running, to: :stopping
end
event :stopped do
transitions from: :stopping, to: :starting_instance
end
event :started do
transitions from: :starting_instance, to: :wait_running
end
end
end
One can then run this state machine by hand, which is useful in experimentation:
> s = Server.create(id: SecureRandom.uuid, state: 'creating', region: 'us-west-2')
> s.state
=> 'creating'
> s.work
> s.state
=> 'wait_running'
It is also useful in testing:
RSpec.describe Server do
before do
# Better in spec_helper.rb in a real program.
Aws.config[:stub_responses] = true
end
let(:s) do
Server.create(id: SecureRandom.uuid,
state: 'creating',
region: 'us-west-2')
end
it 'begins stopping if offline' do
s.state = 'running'
expect(s).to receive(:online?).and_return(false)
s.work
expect(s.state).to eq('stopping')
end
it 'makes an instance in creating' do
s.ec2.stub_responses(:run_instances, {
instances: [ { instance_id: 'i-deadbeef'} ]
})
s.work
expect(s.instance_id).to eq('i-deadbeef')
expect(s.state).to eq('wait_running')
end
end
Using techniques like these, CloudPlane maintains 100% line coverage. Maintaining 100% line coverage allows efficient location of most untested code in new patches. It took some time to bring CloudPlane to 100% coverage at first. Yet, afterwards, maintaining 100% is not difficult.
Specific State Machines in CloudPlane
Unlike the previous example, CloudPlane has several state machines. These are specific to its domain of running Citus database servers on EC2. I gloss over them here so you can get a sense of their size and division.
- Formation: a Citus cluster, comprised of many servers. This controls creation and deletion of Servers and Lineages.
- Server: tied to exactly one EC2 instance in a Formation.
- Timeline: is the Postgres concept of the same name. Its primary function is organizing backups. Timelines relate to one another with a parent-child relationship. A server promotion from standby to primary creates a new Timeline.
- Lineage: used to compute the contents of
pg_worker_list. For every worker and master in a CitusFormation, there will be oneLineage. A Lineage ties together Timelines, backups, servers, and hostname information. - Role: adds, deletes, and changes passwords on Postgres roles on a Server.
- Ami: promotes and monitors AWS AMI availability. It is only active during creation and deletion.
- Page: creates or resolves a page in PagerDuty. It also has formatting information to help the operator see diagnostics on a web page.
Execution and Concurrency
The principles for executing these state machines are:
Call
workaround every ten to thirty seconds for every state machine in the system.CloudPlane requires
workto be mutually exclusive. Two threads of execution must not be callingServer['abcd-1234-...'].workat the same time.Actors and other threads of concurrent threads of execution communicate via
Semaphoremodifications. Only threads holding a lock on an actor may decrement a semaphore. Any other thread may add to a semaphore.
The following sections cover each principle in detail.
Periodicity
"Sidekiq", a queuing library, performs periodic dispatch of work.
The done by running a SQL query and using its results to "refill" queues for later completion. The mechanism is excerpted here: The following runs the Refiller periodically:
Sidekiq::Cron::Job.create(name: 'refiller', cron: '* * * * *',
class: 'Refiller', args: [true])
The following is a subroutine that takes a Ruby class, e.g. Server in the above example, enqueuing its ID and class name for dispatch. One can see that there is code to avoid over-filling the queue (if q.size < klass.active.count), where the former is a query to Redis and the latter is a SQL count(*) query:
def schedule(klass)
cn = klass.to_s
q = Sidekiq::Queue.new(cn)
if q.size < klass.active.count
klass.active.select(:id).each do |o|
Sidekiq::Client.push('queue' => cn, 'class' => Dispatcher,
'args' => [cn, o.id], 'retry' => false)
end
end
end
Mutual Exclusion
The Dispatcher runs work after taking a lock on the Actor record, to avoid concurrency hazards such as double-execution of the code for a state. Of prime importance is that only some actions (like overwriting the state field) can take place with the lock held.
An excerpt with locking, logging, and work:
DB.transaction do
actor = begin
klass.where(id: id).lock_style('FOR UPDATE NOWAIT').first
rescue Sequel::DatabaseError => e
return if e.cause.class == PG::LockNotAvailable
raise
end
return unless actor
# It is required to read a snapshot of semaphore values before
# doing any work, such that `decr` will subtract a value from
# a snapshot earlier than any other query modifying other
# records in the database.
actor.sem if actor.respond_to?(:sem)
logger.info("Working/#{consecutive_work} #{klass_name}['#{id}'] #{actor.state}")
old_state = actor.state
begin
Timeout.timeout(3 * 60) do
actor.work
end
Finally, Actor state changes and/or decrementation of semaphores must occur while holding the lock.
Semaphores
CloudPlane uses a table of Semaphores to trigger actions in Actors, avoiding concurrency hazards. We name each Semaphore, so different threads can change independent semaphores concurrently. For example, when adding a node to a cluster, one must send addressing and credential information to every node in the cluster.
Making the above description more complete, the use of Semaphores looks like this. To show pseudo-code of the above example, one would have request code that looks like this:
class Formation < Actor
def add_node
add_server
servers.each do |s|
s.sem.incr(:configure)
end
end
end
class Server < Actor
def work_running
if sem.pos?(:configure)
self.state = :configuring
save_changes
end
end
def work_configuring
configure_stuff
sem.decr(:configure)
self.state = :running
save_changes
end
end
Rephrased, the "producer" of work performs an increment (incr) on the semaphore called :configure. Whereas, the "consumer" checks (pos?) and decrements (decr) that same semaphore.
While use of Semaphores is not complex, it is unorthodox. In the following, this document details the motivations for the design.
The problem is: how can CloudPlane ensure that given some arbitrary number concurrent inputs (e.g. add_node) that CloudPlane will run at least once the required action (e.g. configuring) after the last such triggering input is submitted?
To show how simpler implementations have issues, we simplify the previous example, introducing problems.
The implementation avoids any synchronization construct not already put in place by Postgres. Thus, the Formation actor modifies the state of its associated Server actors directly:
class Formation < Actor
def add_node
add_server
servers.each do |s|
s.state = :configuring
s.save_changes
end
end
end
class Server < Actor
def work_running
end
def work_configuring
configure_stuff
self.state = :running
save_changes
end
end
In this implementation, the following can occur:
Formation Server
────────────────────────────────────────────────────────────────
# add_node
add_server
servers.each do |s|
s.state = :configuring
s.save_changes
end
# work_configuring
configure_stuff
self.state = :running
# add_node
add_server
servers.each do |s|
s.state = :configuring
s.save_changes
end
save_changes # overwrites with `running`
Because Server ran save_changes last, Formation's second request is ignored. This is because configuring is overwritten with running in the last step.
Now we can show how to solve this problem with Semaphores. The Semaphore table looks like this:
Table "public.semaphores"
┌──────────┬─────────┬────────────────────┐
│ Column │ Type │ Modifiers │
├──────────┼─────────┼────────────────────┤
│ actor_id │ uuid │ not null │
│ name │ text │ not null │
│ val │ integer │ not null default 0 │
└──────────┴─────────┴────────────────────┘
Indexes:
"semaphores_pkey" PRIMARY KEY, btree (actor_id, name)
Check constraints:
"semaphores_val_check" CHECK (val >= 0)
Let's also define the Semaphore operations in more detail:
decr: decrements a semaphore by zero or more.incr: increases a semaphore by one.pos?: returnstrueif theSemaphorehas a value above zero.
Using the Semaphore-using implementation, the previous scenario would play out like this:
Formation Server
────────────────────────────────────────────────────────────────
# add_node
add_server
servers.each do |s|
# Increments semaphore to "1"
s.sem.incr(:configure)
end
# work_running
if sem.pos?(:configure)
self.state = :configuring
save_changes
end
# work_configuring
configure_stuff
# Decrements semaphore to "0"
sem.decr(:configure)
self.state = :running
add_server
servers.each do |s|
# Increments semaphore to "1"
s.sem.incr(:configure)
end
save_changes
# work_running
if sem.pos?(:configure)
self.state = :configuring
save_changes
end
# ....configures again....
Here we can see that the Server will correctly begin a second re-configuration pass.
There is a final ambiguity in the previous example: we defined decr as decrementing zero-or-more from a Semaphore, but left implicit is the derivation of how much to decrement.
Semaphore Groups define the precise quantity to decrement. They do this by reading the value of all semaphores for an Actor and storing them in memory. This must be done before any other records are read:
# It is required to read a snapshot of semaphore values before
# doing any work, such that `decr` will subtract a value from
# a snapshot earlier than any other query modifying other
# records in the database.
actor.sem if actor.respond_to?(:sem)
When we call decr, it deducts the memory-stored value from the current database-stored value of the semaphore.
This solves the problem:
Formation Server
────────────────────────────────────────────────────────────────
# add_node
add_server
servers.each do |s|
# Increments semaphore to "1"
s.sem.incr(:configure)
end
# add_node
add_server
servers.each do |s|
# Increments semaphore to "2"
s.sem.incr(:configure)
end
# work_running
if sem.pos?(:configure)
self.state = :configuring
save_changes
end
# work_configuring
#
# (implied, as its done in the
# Dispatcher: read all semaphore
# values. :configure is "2"
sem
add_server
servers.each do |s|
# Increments semaphore to "3"
s.sem.incr(:configure)
end
configure_stuff
# Decrements semaphore by "2",
# value is now "1".
sem.decr(:configure)
self.state = :running
save_changes
# work_running
if sem.pos?(:configure)
self.state = :configuring
save_changes
end
# ....configures again....
To re-iterate, Semaphores are designed for ensuring that some steps are taken at least once after the last incr commits. CloudPlane has many idempotent operations, and this coalescing of modifications is efficient.
Concluding Remarks
We hope you find these references useful to compare to existing systems or designing new ones. If you find useful substantive alterations to this design, we hope you will write about them and if you do please share them with us. Finally if you’re interested in working on similar problems here at Citus we’re hiring.
