The schedule is out 🗓️ for POSETTE: An Event for Postgres 2026!
The following post is contributed by 8Kdata
An introduction to pg_paxos
Pg_paxos is a database level implementation of the widely renowned Paxos protocol, invented by Leslie Lamport. Pg_paxos offers a master-less (or multi-master, if you prefer) layer that can be enabled directly in the database without the need for external tools or transaction managers.
The defining feature of pg_paxos is that replication across the nodes of the cluster is always conflict-free. This in turn leads to a strictly consistent (as in the distributed sense of the C in CAP) view of the cluster.
This clearly differentiates pgpaxos from other (multi-master) replication solutions that need to perform conflict resolution techniques. Pgpaxos is built on top of the consensus protocol Paxos, which enables pg_paxos to guarantee serializability in a distributed setting. By contrast, other solutions end up with data inconsistencies or depend on developers to explicitly declare conflict resolutions for race conditions. There's no free lunch though: this comes at the cost of latency and lower throughput.
Pg_paxos is an extension for PostgreSQL, and it is open source (under the PostgreSQL license).
Uses for pg_paxos
Databases are usually a central piece in a given architecture or service and orchestrate data access across all actors. Given the role of databases, pg_paxos proves to be very convenient for a conflict-less replication subsystem. Every application may directly use it without adding external dependencies or more services.
There are many applications where the strict guarantees provided by Paxos/pg_paxos are an almost absolute requirement, like:
- Distributed locking services
- Asynchronous loss-less services (like distributed file synchronization services à la Dropbox)
- Financial applications where the order of the operations is critical
- Meta-data services which cannot tolerate inconsistent views
- And of course, many others
Think of pg_paxos as a Zookeeper or an etcd but in your database!
In this post we are going to design and implement a distributed job execution service. Clients may connect to any node (database) and compete to get and execute the next queued job. Pg_paxos will ensure correct execution no matter what happens, including node failure and concurrent races.
But before digging into that let's see how to install and run pg_paxos on your PostgreSQL.
Setup
Initial setup
The setup process for pg_paxos is extremely straightforward. Following the instructions provided in the README is all that is required to get it up and running on your box.
We are going to assume that the installation is happening on a UNIX-based system with a recent version of PostgreSQL installed (9.4+). We are going to set up a three-node Paxos cluster.
First, stop any currently running postgres process (service postgresql stop or pgctl -D /path/to/your/data/directory stop or equivalent). Then make copies of the data directory (found in multiple locations like /usr/local/var/postgres or /var/lib/postgres) to locations in the same directory, calling them postgresclstr2 and postgresclstr_3. If you are a more seasoned PostgreSQL DBA you might want try pg_basebackup.
Installation
Clone the GitHub repo (found at https://github.com/citusdata/pg_paxos) and compile it following the instructions in the README. If you are just testing pg_paxos, consider using the more recently updated develop branch.
clm-srangarajan:pg_paxos(deve10p)$ PATH=/usr/local/pgsql/binl:$PATH make
clang -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasin
g -fwrapv -Wno-unused-command-line-argument -02 -std=c99 -Wall -Wextra -Werror -Wno-unused-parameter -Iinclude -I/usr/local/Cellar/postgresql/9.4.4/include -
I. -I./ -I/usr/local/Cellar/postgresql/9.4.4/include/server -I/usr/local/Cellar/postgresql/Q.4.4/include/internal -I/Applications/Xcode.app/Contents/Developer
/Platforms/MaCOSX.platform/Developer/SDKs/MacOSXlO.10.sdk/usr/include/libxle -c -o src/pg_paxos.o src/pg_paxos.c
clang -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasin
g -fwrapv -Wno-unused-command-line-argument -02 -bundle -multiply_defined suppress -o pg_paxos.so src/paxos_api.o src/pg_paxos.o src/ruleutils_94.o src/ruleu
tils_95.o src/table_metadata.o -L/usr/local/Cellar/postgresql/9.4.4/lib -Wl,-dead_strip_dylibs -L/usr/local/Cellar/postgresql/9.4.4/lib -lpq -bundle_loader
/usr/local/Cellar/postgresql/9.4.4/bin/postgres
clm-srangarajan:pg_paxos(deve10p)$ sudo PATH=/usr/local/pgsql/binl:$PATH make install
Password:
/bin/sh /usr/local/Cellar/postgresql/9.4.4/lib/pgxs/src/makefilesl../../config/install-sh -c -d '/usr/local/Cellar/postgresql/9.4.4/lib'
/bin/sh /usr/local/Cellar/postgresql/9.4.4/lib/pgxs/src/makefilesl../../config/install-sh -c -d '/usr/local/Cellar/postgresql/Q.4.4/share/postgresql/extension
/bin/sh /usr/local/Cellar/postgresql/9.4.4/lib/pgxs/src/makefilesl../../config/install-sh -c -d '/usr/local/Cellar/postgresql/Q.4.4/share/postgresql/extension
/usr/bin/install -c -m 755 pg_paxos.so '/usr/local/Cellar/postgresql/9.4.4/lib/pg_paxos.so'
/usr/bin/install -c -m 644 pg_ paxos. control '/usr/local/Cellar/postgresql/9. 4. 4/share/postgresql/extension/'
/usr/bin/install -c -m 644 updates/pg_paxos--0.1--0.2.sql sql/pg_ paxos--0. 2. sql '/usr/local/Cellar/postgresql/9. 4. 4/share/postgresql/extension/'
Once we do this, we can go ahead and install the required extensions (dblink and pg_paxos itself). Please note that we must do this on each one of the 3 clusters.
clm-éranéarajan{pg_paxos(develop)$ psql
psql (9.4.4)
Type IIhelpII for help.
srangarajan=# CREATE EXTENSION pg_paxos;
ERROR: required extension "dblink" is not installed
srangarajan=# CREATE EXTENSION dblink;
CREATE EXTENSION
srangarajan=# CREATE EXTENSION pg_paxos;
CREATE EXTENSION
pg_paxos configurations
The configuration for pgpaxos is straightforward. Simply edit postgresql.conf and add the following pgpaxos-specific directives:
#
# CUSTOMIZED OPTIONS
#
# Add settings for extensions here
shared_preload_libraries = 'pg_paxos'
pg_paxos.node_id = 'node_5432'
pg_paxos.allow_mutable_functions = 'on'
The first and last setting are merely parameters that control the inclusion and behavior of pgpaxos. Nodeid is a setting that we want unique between all nodes to guarantee consistency. A convenient node naming convention is to append the port number of its running cluster.
Start the three servers. At this point, we should have three clusters running pg_paxos.
A simple distributed job service (queue)
Introduction
We are going to build a distributed job service. A distributed job service is a queue that has multiple consumers which process jobs in a distributed fashion. This means that:
- There are multiple instances of the same worker working in parallel
- They don't point at the same data-source / database
- They never race/overlap
- They never do the same job twice
The benefits of this kind of service include the obvious performance boost from parallel processing. But the real benefit here is that there is no single point of failure. A performance boost could have been obtained by just running multiple jobs against the same DB. However if a worker node with all the jobs went down or that database went down, all progress would be stalled. Apart from this we also get workload distribution.
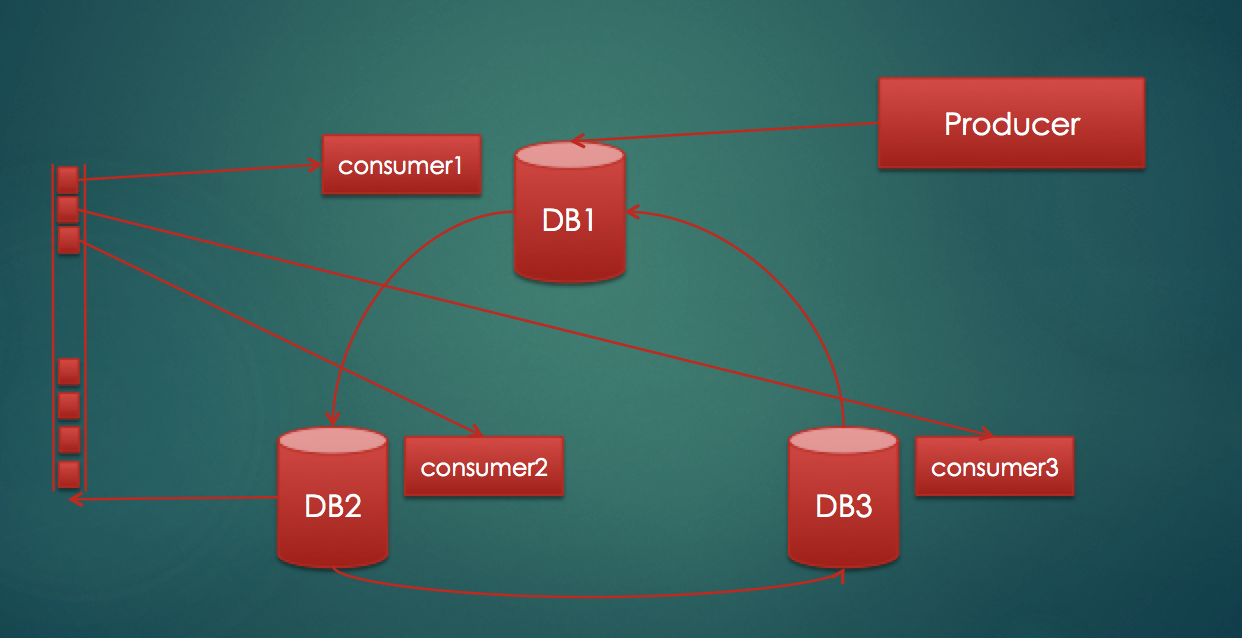
The above diagram shows a simple setup for the service we want to build.
- We have three databases that are constantly communicating with each other to keep data in a consistent state using the Paxos protocol.
- We have a producer node that puts jobs into one of the databases, and since data is being consistently replicated all three databases will see these jobs.
- We have three consumer nodes picking up jobs from these databases.
- On the left hand side of the block diagram we see a logical depiction of the distributed queue. Note that this single queue does not actually exist; it is persisted in the three databases. However, due to the strong consistency guaranteed by pg_paxos, all consumers effectively see a single unified view of the job queue.
What are the guarantees we would need to build such a system?
- A single, globally consistent view of the queue
- The ability to make atomic operations on this queue
- Strong isolation to allow for concurrency while preventing dirty, non-repeatable, and phantom reads
- And of course, durable state
In essence we have asked for the four (A)tomicity (C)onsistency (I)solation (D)urability properties from a distributed database. This is exactly what Paxos guarantees through strict serializability, atomicity and consistency from its round-based decision making. Combined with PostgreSQL's own durability, pg_paxos can fulfill all four of these guarantees.
It could be argued that other queue systems such as SQS or RabbitMQ could also be used for this distributed execution service. However, we don't want any job to be run more than once. These systems exhibit an explicit at-least-once delivery, which would require very careful design of distributed locking (fairly non-trivial) to make jobs run only once. By contrast, thanks to the proposed locking mechanism (which is trivially implemented in pg_paxos) an exactly-once delivery mechanism is implemented.
DDL Design
In order to be able to test, verify and KISS, we're going to simplify the problem -- from processing any job to processing a very specific job. We are going to be creating and processing jobs which increment counters. The counters are indexed by key. The table design would look like this:
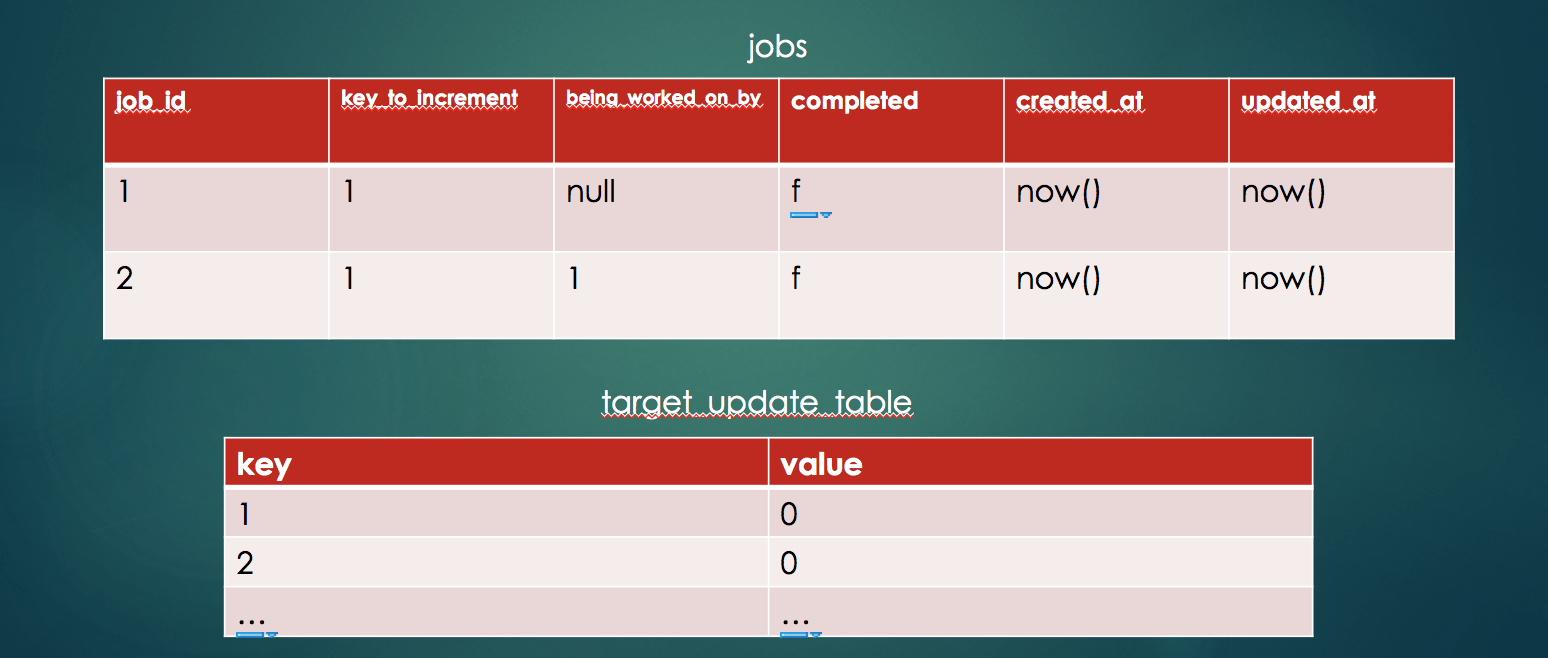
There are additional pieces of metadata on the jobs table, namely "completed" and "beingworkedon_by". They mark whether the job has been completed, and if not which consumer is currently processing that job. This metadata will be instrumental in making sure we don't repeat jobs and don't create races.
For our experiment we are going to assume we have ten key-value pairs with all values initially at zero. Our jobs are each going to increment a value until all values hit ten, thus ten jobs per pair. Hence, as we have ten KV pairs, they will give birth to 10 * 10 = 100 jobs.
So, we have one hundred jobs being produced and three consumers trying to finish them as quickly as possible. We can verify correct execution by checking that all values are at ten, no more and no less.
Implementation
The implementation of a consumer is straightforward. For each KV pair, insert a job into the jobs table.
This is the code for the consumer:
def indentify_next_job()
def grab_job()
def execute(job) {
locked = grab_job(job)
execute_job() if locked
}
job = identify_next_job()
while(job) {
execute(job)
job = identify_next_job()
}
Each consumer runs in a tight loop, trying to grab and execute the next available job until there are no more. It calls identifynextjob to obtain the next job.
identifynextjob
SELECT job_id
FROM jobs
WHERE (being_worked_on_by IS NULL OR being_worked_on_by = ?)
AND completed IS NOT TRUE LIMIT 1
This is a simple query that selects one uncompleted job which has not yet been picked by another consumer node (or by the same node earlier). This last condition is a subtlety worth noting. The same node could attempt to grab a job twice. This could happen if the consumer node grabbed a job but died before finishing it off.
grab_job
UPDATE jobs
SET being_worked_on_by = ?, updated_at = now()
WHERE job_id = ?
AND (being_worked_on_by IS NULL OR being_worked_on_by = ?)
OR updated_at - created_at > '00:10:00'
RETURNING key_to_be_incremented
This query effectively "locks" the job for the consumer node. We have to use a stored value in a column (which is effectively and consistently replicated by pg_paxos to all other nodes) to achieve distributed locking semantics. This is also the reason why the condition for picking a job needs to be rechecked here.
One other check is that the job is more than ten minutes old. This is an aging check to make sure that if some other node picked up the job and died a long time back, we continue the work.
execute_job
WITH perform AS (
UPDATE target_update_table
SET value = value + 1
FROM jobs
WHERE target_update_table_key = ?
AND jobs.being_worked_on_by = ?
RETURNING target_update_table_key
)
UPDATE jobs
SET completed = TRUE, updated_at = now
FROM perform
WHERE jobs.being_worked_on_by = ?
AND job_id = ?
This is the function that actually executes the job. It is split into two parts, a CTE and the core query. The CTE does the actual incrementing and the core query marks the job complete.
We use the same predicate from previous queries in the CTE, but without the IS NULL modifier. This is because at this point in the workflow the job should have been locked, either by this or another consumer -- and so execution should not happen.
Also note the repeated predicate in the other query. This is because in PostgreSQL the core query and the CTE both start execution simultaneously and see snapshots of the DB state. Double-checking the predicate addresses this concurrency situation.
The jobs are being updated in the outer query from the CTE even though we aren't actually using any field from the CTE. This causes the outer update to run only if the CTE updated (and hence returned) something. It's the poor man's way of tying these two updates into a single transaction.
Running the Code
Clone the repo TODO to obtain the software for this distributed queue service. Please note that you will have to run the SQL setup scripts against each node before running the producer and consumers. The files assume the following setup:

The expected outcome is that no conflicts arise and the result is always correct. There are no serializability issues, no jobs being run twice. Just what you what expect.
This is no little accomplishment. If you would have used a non-consensus based solution, like most of the multi-master asynchronous software relying on conflict resolution, you may have ended with inconsistencies due to timing issues, race conditions or clock skew.
Conclusion
In conclusion, pg_paxos is promising software. It brings much needed conflict-free operation to compete with existing solutions. It is very simple to install, set up, and get running. It does not yet support all of PostgreSQL's features, but it is under active development.
The drawbacks are high latency in both reads and writes and low throughput. Pg_paxos cannot be used for high performance transactional systems. But it can serve very well for low-bandwith, reliable replication use cases. It's a well-known limitation of consensus-based solutions in general.
We faced some issues while performing this study, but our interactions with the developers on the project have been great. They were very responsive to our suggestions, bug reports (7, 6, 5, 4 and 3) and general questions, and have shown a quick turnaround time on fixing bugs or implementing essential missing features reported.
You can find the example code used in this post here on GitHub. If you liked pg_paxos, please star the project on GitHub!
