📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
v10.0 (Feb 2021)
Updates to this version:
- Update 10.0.1 (Feb 19, 2021) CHANGELOG
- Update 10.0.2 (Mar 3, 2021) CHANGELOG
- Update 10.0.3 (Mar 16, 2021) CHANGELOG
- Update 10.0.4 (Jul 14, 2021) CHANGELOG
- Update 10.0.5 (Aug 16, 2021) CHANGELOG
- Update 10.0.6 (Nov 12, 2021) CHANGELOG
- Update 10.0.8 (Apr 20, 2023) CHANGELOG
What’s new in Citus 10
Welcome to version 10.0, a special, major release of the Citus database, an open source extension to PostgreSQL. Citus 10 extends Postgres (12 and 13) with many new superpowers:
- Columnar storage for Postgres – Compress your PostgreSQL and Citus tables to reduce storage cost and speed up your analytical queries.
- Sharding on a single Citus node – Make your single-node Postgres server ready to scale out by sharding tables locally using Citus.
- Shard rebalancer in Citus open source – We have open sourced the shard rebalancer so you can easily add Citus nodes and rebalance your cluster.
- Joins and foreign keys between local PostgreSQL tables and Citus tables – Mix and match PostgreSQL and Citus tables with foreign keys and joins.
- New redistribute functions – Change the way your tables are distributed in a single step using new alter table functions.
- Much more – Better naming, improved SQL & DDL support, simplified operations.
These new capabilities represent a fundamental shift in what Citus is and what Citus can do for you.
Citus is no longer just about sharding your Postgres database: you can now use Citus columnar storage to compress large data sets. And Citus is no longer just about multi-node clusters: you can now shard on a single node to be “scale-out-ready”. Finally, Citus is no longer just about transforming Postgres into a distributed database: you can now mix regular (local) Postgres tables and distributed tables in the same Postgres database.
In short, Citus is now a Postgres extension for running Postgres at any scale.
Columnar storage for PostgreSQL
The data sizes of some new Citus users are truly gigantic, which meant we needed a way to lower storage cost and get more out of the hardware. That is why we implemented columnar storage for PostgreSQL as part of the Citus extension. Citus Columnar will give you compression ratios of 3-10x, and even greater I/O reductions. Best part? We have made columnar available as part of the open source Citus 10 release and you can use Citus columnar with or without the Citus scale-out features!
Our team has a long history with columnar storage in PostgreSQL, as we originally developed the cstore_fdw extension which offered columnar storage via the foreign data wrapper (fdw) API. PostgreSQL 12 introduced “table access methods”, which allows extensions to define custom storage formats in a much more native way.
Citus makes columnar storage available in PostgreSQL via the table access method APIs, which means that you can now create columnar tables by simply adding USING columnar when creating a table:
CREATE TABLE order_history (...) USING columnar;
If you have an existing row-based (“heap”) table that you’d like to convert to columnar, you can do that too, using the alter_table_set_access_method function:
-- compress a table using columnar storage (indexes are dropped)
SELECT alter_table_set_access_method('orders_2019', 'columnar');
When you use columnar storage, you will typically see a 60-90% reduction in data size. In addition, Citus will only read the columns used in the SQL query. This can give dramatic speed ups for I/O bound queries, and a big reduction in storage cost.
Compared to cstore_fdw, Citus columnar has a better compression ratio thanks to zstd compression. Citus Columnar also supports rollback, streaming replication, archival, and pg_upgrade.
There are still a few limitations to be aware of: Indexes and update/delete are not supported, and it is best to avoid single-row inserts, since compression only works well in batches. We plan to address these limitations in upcoming Citus releases, but you can also avoid them by using partitioning.
If you partition time series data by time, you can use row-based storage for recent partitions to enable single-row, update/delete/upsert and indexes—while using columnar storage to archive data that is no longer changing. To make this easy, we also added a function to compress all your old partitions in one go:
-- compress all partitions older than 7 days
CALL alter_old_partitions_set_access_method('orders_partitioned', now() - interval '7 days', 'columnar');
This procedure commits after every partition to release locks as quickly as possible. You can use pg_cron to run this new function as a nightly compression job.
Stay tuned for a Citus 10 Columnar blog post by Jeff Davis describing the new columnar storage access method in detail.
Starting with Citus on a single node—to be scale-out-ready
We often think of Citus as “worry-free Postgres”, because Citus takes away the one concern you may have when choosing Postgres as your database: reaching the limits of a single node. However, when you migrate a complex application from Postgres to Citus, you may need to make some changes to your application to handle restrictions around unique- and foreign key-constraints and joins, since not every PostgreSQL feature has an efficient distributed implementation.
The easiest way to scale your application using Citus without ever facing the cost of migration and be truly worry-free is to use Citus from day one, when you first build your application. Applications built on Citus are always 100% compatible with regular PostgreSQL, so there is no risk of lock-in. The only downside of starting on Citus so far was the cost and complexity of running a distributed database cluster, but this changes in Citus 10. You can now shard your Postgres tables on a single Citus node to make your database “scale-out-ready”.
Being able to use Citus on a single node makes getting started so easy that we can simply describe it here: After installing Citus and setting up a PostgreSQL database, add the following to postgresql.conf:
shared_preload_libraries = 'citus'
Restart PostgreSQL and run the following commands (e.g. via psql):
CREATE EXTENSION citus;
CREATE TABLE data (key text primary key, value jsonb not null);
SELECT create_distributed_table('data', 'key');
The create_distributed_table function will divide the table across 32 hidden shards that can be moved to new nodes when a single node is no longer sufficient.
You may experience some overhead from distributed query planning, but you will also see benefits from multi-shard queries being parallelized across cores. You can also make distributed, columnar tables to take advantage of both I/O and storage reduction and parallelism.
The biggest advantage of distributing tables on a single node is that your database will be ready to be scaled out using the shard rebalancer.
Open sourcing the Citus shard rebalancer
The managed Hyperscale (Citus) service on Azure and its predecessor on AWS used to have a separate extension for rebalancing shards after adding a node, which was not part of the Citus open source repo.
With Citus 10, we have introduced the shard rebalancing functionality into the open source Citus repo. That means that scaling out is now as simple as running 2 SQL queries after you’ve set up a new PostgreSQL server with the Citus extension:
-- add a new worker node
SELECT citus_add_node('10.0.0.6 ', 5432);
-- move shards to the new worker node(s) to even out the number of shards per node
SELECT rebalance_table_shards();
-- or, move shards based on disk size in case they are skewed
SELECT rebalance_table_shards(rebalance_strategy := 'by_disk_size');
While a shard is being moved, writes to that shard are blocked, but all reads and writes to other shards can continue. If you are using the Hyperscale (Citus) option in Azure Database for PostgreSQL, we have some extra tricks to make writes to the shards being moved non-blocking as well.
By default, the Citus shard rebalancer comes with 2 rebalance strategies: by_shard_count to even out the number of shards (the default), by_disk_size to even out the number of bytes, and you can also create your own rebalance strategies.
Joins and foreign keys between PostgreSQL and Citus tables
With the new single-node Citus capabilities and the shard rebalancer, you can be ready to scale out by distributing your tables. However, distributing tables does involve certain trade-offs, such as extra network round trips when querying shards on worker nodes, and a few unsupported SQL features.
If you have a very large Postgres table and a data-intensive workload (e.g. the frequently-queried part of the table exceeds memory), then the performance gains from distributing the table over multiple nodes with Citus will vastly outweigh any downsides. However, if most of your other Postgres tables are small, then you might end up having to make additional changes without much additional benefit.
A simple solution would be to not distribute the smaller tables at all. In most Citus deployments, the application connects to a single coordinator node (which is usually sufficient), and the coordinator is a fully functional PostgreSQL server. That means you could organize your database as follows:
- convert large tables into Citus distributed tables,
- convert smaller tables that frequently JOIN with distributed tables into reference tables,
- convert smaller tables that have foreign keys from distributed tables into reference tables,
- keep all other tables as regular PostgreSQL tables local to the coordinator.
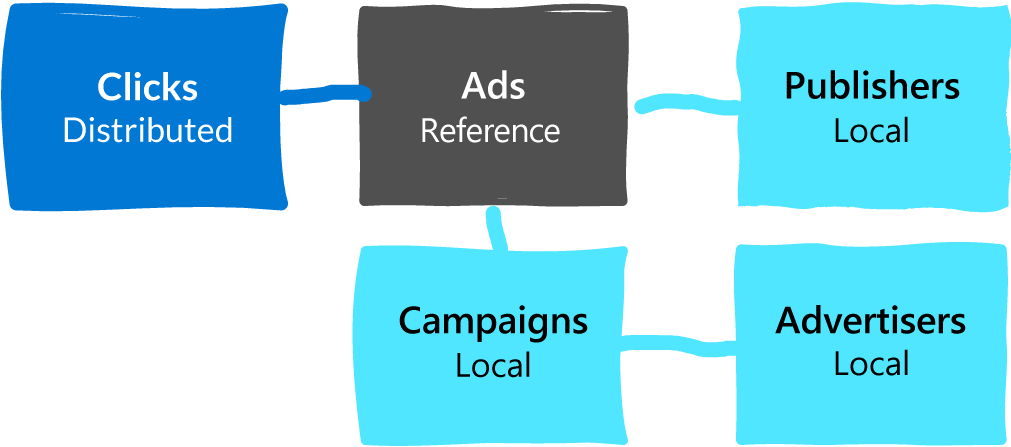
That way, you can scale out CPU, memory, and I/O where you need it, and minimize application changes and other trade-offs where you don’t. To make this model work seamlessly, Citus 10 adds support for 2 important features:
- foreign keys between local tables and reference tables
- direct joins between local tables and distributed tables
With these new features, you can mix and match PostgreSQL tables and Citus tables to get the best of both worlds without having to separate them in your data model.
Alter all the things!
When you distribute a table using Citus, choosing your distribution column is an important step, since the distribution column determines which constraints you can create, how (fast) you can join tables, and more.
Citus 10 adds the alter_distributed_table function to change the distribution column, shard count, and co-location of a distributed table.
-- change the distribution column to customer_id
SELECT alter_distributed_table('orders',
distribution_column := 'customer_id');
-- change the shard count to 120
SELECT alter_distributed_table('orders',
shard_count := 120);
-- Co-locate with another table
SELECT alter_distributed_table('orders',
distribution_column := 'product_id',
colocate_with := 'products');
Internally, alter_distributed_table reshuffles the data between the worker nodes, which means it is fast and works well on very large tables. We expect this makes it much easier to experiment with distributing your tables without having to reload your data.
You can also use the function in production (it’s fully transactional!), but you do need to (1) make sure that you have enough disk space to store the table several times, and (2) make sure that your application can tolerate blocking all writes to the table for a while.
Replacing master_ with citus_ in our APIs
Early versions of Citus were heavily influenced by Hadoop, and we referred to the node that holds the database metadata as the “master” and the nodes that hold the data as “workers.” We started using the term “coordinator” instead of master years ago, but some of our APIs (SQL functions) still had master_ in their names out of inertia.
The outdated terminology was confusing, but more importantly derives from a master/slave analogy that has no place in software. Citus 10 replaces the functions that started with master_ with equivalent versions that start with citus_ (e.g. master_add_node becomes citus_add_node). We will completely remove the master_ APIs in a future release, so if you’re using the master_ function names, we recommend you replace the names in your scripts as well.
Many other features in Citus 10
And there’s more!
- DDL support
More DDL commands work seamlessly on distributed Citus tables, including CREATE STATISTICS, ALTER TABLE .. SET LOGGED, and ALTER SCHEMA .. RENAME. - SQL support
Correlated subqueries can now be used in the SELECT part of the query, as long as the distributed tables are joined by their distribution column. - New views to see the state of your cluster: citus_tables and citus_shards
The citus_tables view shows Citus tables and their distribution column, total size, and access method. The citus_shards view shows the names, locations, and sizes of individual shards.
Start playing with Citus 10 in two easy steps
If you are as excited as we are and want to play with these new Citus 10 features, doing so is now easier than ever. Since Citus can be used on a single node (any scale!), that means you can also run Citus as a single Docker container.
# run PostgreSQL with Citus on port 5500
docker run -d --name citus -p 5500:5432 -e POSTGRES_PASSWORD=mypassword citusdata/citus
# connect
docker exec -it citus psql -U postgres
Thank you
A big thank you to the following people who contributed to this update:
And finally, thank you to all of you who use Citus and who have taken the time to give feedback and be part of our journey. If you’ve filed issues on GitHub, submitted PRs, talked to our @citusdata team on Twitter, signed up for our monthly technical newsletter, or joined our Citus Public Slack… well, thank you. And please, keep the feedback coming.