📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
When those of us who work on Postgres High Availability explain how HA in Postgres works, we often focus on the server side of the stack. Having a Postgres service running with the expected data set is all-important and required for HA, of course. That said, the server side of the stack is not the only thing that matters when implementing high availability. Application code has a super important role to play, too.
In this post, you will learn what happens to your application code and connections when a Postgres failover is orchestrated. Your application might be running on Postgres on-prem with HA configured—or in the cloud—or on a managed PostgreSQL service such as Azure Database for PostgreSQL. Now, if you’re running your app on top of a managed service with HA, you probably don’t need to worry about how to implement HA, as HA is managed by the service. But it’s still useful to understand what happens to your application when a Postgres failover occurs.
The most important thing to know about client-side HA is that when a failover happens, the connections to Postgres are lost. Your application will get an error when trying to use the previously established connection, without any way to anticipate the situation.
What’s true of all those different deployment options though is that a PostgreSQL connection is stateful. The PostgreSQL connection support specific connection-time properties and GUCs (Postgres settings are called GUC variables.) Then a connection hosts a session, and Postgres exposes session-level objects such as temporary tables, server-side prepared-statements, cursors, and even more. When a failover happens, all this state is lost. The connection is lost. And your application must reconnect.
How Connection Strings work with Postgres
In the following application code snippet, written in Python and edited so that you can see all the interesting bits in a very short amount of code, you can see that you connect to a Postgres service (here using the psycopg2 driver) and then use the connection to execute a query:
CONNSTRING = "dbname=yesql application_name=app host=node1"
def fetch_month_data(year, month):
"Fetch a month of data from the database"
date = "%d-%02d-01" % (year, month)
sql = """
select date, shares, trades, dollars
from factbook
where date >= date %s
and date < date %s + interval '1 month'
order by date;
"""
pgconn = psycopg2.connect(CONNSTRING)
curs = pgconn.cursor()
curs.execute(sql, (date, date))
result = {}
for (date, shares, trades, dollars) in curs.fetchall():
result[date] = (shares, trades, dollars)
return result
When the primary Postgres instance fails in production, a failover is implemented so your application can still access the same data set as before the failure. Even though your connection may be established successfully, it’s possible that later, when your application attempts to use the connection to create its cursor, or tries to execute a SQL query, or even later when reading through the result set… well at any point in time after your application has obtained a connection to the Postgres instance, the connection might be lost.
Come to think of it, the connection to the Postgres instance could get lost because of changes in the firewall rules, because of a network equipment failure, because of an ethernet or fiber cable being damaged, and many other reasons. In some cases, the TCP/IP implementation will pretend like sending packets is just suddenly very slow, thanks to the default TCP/IP timeout settings. In other cases, though, the connection to Postgres is immediately known to be broken.
When a failover happens, all currently established connections to the Postgres database service are lost. Connection lost.
Client-side HA and Fault-Tolerance: a job for the whole team
The only conclusion we can draw so far is that implementing Postgres HA is a job for the whole team: dev (frontend and backend) and ops (sre, sysadmin, and dba roles) need to be involved, along with product and business partners in most cases. Even when the infrastructure operates with the most robust design, a failover means the application has lost its previously established connection, with absolutely no way to anticipate that.
You might be surprised that I am including frontend developers in the bucket list of concerned people, and I even extended the list further to include product and business people. That’s on purpose. One way to understand HA is to remember that we are implementing fault tolerance. After all, your goal is to react to a hardware or software fault in production in the least impacting way for your end users. The first question is then going to be: can you deliver a meaningful subset of your product when the database is down? is there a part of your user activity that is read-only? or that could be safely delayed?
So now that you have implemented proper fault tolerance in your product, up to the frontend parts of the architecture, you are prepared for when the worst happens. When your primary Postgres instance is not available anymore, you will have lost your connection to Postgres. What’s next? You need to establish a new connection to Postgres.
Multi-Hosts Connection Strings, thanks to libpq
Let’s assume your application is using the connection string "dbname=yesql application_name=app host=node1" shown in the code sample above—and let’s assume node1 goes down. In the best case scenario, node1 is back online already and is now a standby itself to the new primary, so currently node1 is available as a read-only replica… but what if your application code expects a read-write connection to work with?
Fortunately, Postgres has a client-side library that implements a multi-host connection string and the target-session-attrs attribute. The client-side library is named libpq and is both the C language library and the basis for most the non-C programming APIs that connect to Postgres.
Some programming languages refrain from binding with C code and will then provide a full implementation of the Postgres protocol directly, such as Java with JDBC drivers or Go lang. A lot of programming languages just bind to libpq internally to provide a Postgres driver though—such as Python, Ruby, PHP, or even Node.js when using node-pg-native.
You can use the multi-host connection string facility in libpq instead of binding your application to a single Postgres node, as I did in the code sample earlier in this post.
Note that when using a cloud or managed database service, such as Azure Database for PostgreSQL—and sometimes also when using a database connection proxy such as PgBouncer or HAProxy—the extra layer can hide some of the details to your application. If you’re using a managed database service, you can continue to use the connection string given by the service both before and after a Postgres failover, assuming you configured your managed database service to use HA. When using PgBouncer or HAProxy, well, there are multiple ways to set that up, and this article does not cover these. Use multi-hosts connection strings when your application connects directly to Postgres.
Let me show you the new code, with the new connection string that lists all our Postgres primary candidate nodes and requires a read-write session:
# previous version looked like this:
# CONNSTRING = "dbname=yesql application_name=app host=node1"
# new version with multi-hosts looks like this:
CONNSTRING = "host=node1,node2,node3 target_session_attrs=read-write dbname=yesql application_name=app"
Here’s an example of the same connection string in the format that Django expects. I’ve also added some more details, such as the username and the sslmode:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': 'yesql',
'USER': 'dim',
'PASSWORD': '',
'HOST': 'node1,node2,node3',
'PORT': '5432',
'OPTIONS': {
'application_name': 'app',
'sslmode': 'require',
'target_session_attrs': 'read-write',
},
},
}
When using this new multi-host connection string above:
- Your application connects to the hosts specified in the
HOSTline, in the order provided. - Once a connection is successfully established, a query is run to figure out if the connection has been made to a Postgres server that offers a
read-writesession attribute. - Once the
read-writesession attribute has been confirmed, you are connected to the primary, and the connection is established. - However, if the
libpqcheck for theread-writesession attribute fails on a new host, the connection will be discarded. The next host on theHOSTlist will now be tried, in a loop, until you either find one that supports your target session attributes, or until all the hosts in theHOSTlist have been tried.
Handling a failover from the application perspective
So, if you go back to thinking about your main scenario here: what happens to your application code when a failover happens in production? What you know already is that your connection to the database is lost during a failover.
Now, given that multi-host connection string capability, you have a way to keep re-using the exact same connection string after a failover happened. It might be that node1 is now down and can’t be reached anymore, or that node1 is already back online as a standby node: in either case your connection string that is using target_session_attrs=read-write is going to fail on node1, and keep trying, until one of the remaining nodes is found to provide a read-write session.
Testing environment: a 1-line docker command thanks to pg_auto_failover
Conventional wisdom has this great quote about theory and practice:
“In theory, theory and practice are the same thing… not in practice”.
If you want to try out this multi-host connection string and test it with your application, well, you need to setup at least a primary Postgres node and one standby, and you need to know how to implement a Postgres failover. That sounds like a DBA job now, and we just want to easily check your application connection string locally. Do you really need to ask for a production-grade environment just for this test?
Thanks to pg_auto_failover there is an easy way to setup a couple of Postgres nodes with failover capabilities. We even cooked a special pg_auto_failover docker image to make it easy for you to test your applications for HA.
If you are already using docker for some of your local testing or development, then setting up an environment that allows you to see what happens to your application code in case of a Postgres failover is as easy as running the following command:
$ docker run --rm -it citusdata/pg_auto_failover:demo
The docker image runs three Postgres instances in the same container, to make it easy to play around. This docker image is not intended as a production ready container, as you can well imagine. The goal here is for you, an application developer, to easily trigger a Postgres failover and see what happens to your application.
If you want to use pg_auto_failover for managing your production environment, it is also possible, and we already have users and customers doing just that. I’m just saying that the “demo” docker image is not fit for production use.
To connect your application to the Postgres instances in the pg_auto_failover docker container, you can either play with the usual docker network ports settings and expose the ports to the outside of the container, or maybe even go fancy and use docker-compose instead.
When running with the pg_auto_failover all-in-one docker container demo image, your terminal is now running a tmux session with six interactive shells running, each numbered with a big font number in the middle of the shell.
- Window 0: a pg_auto_failover monitor is running.
- Window 1: a Postgres instance is running, currently primary.
- Window 2: another Postgres instance is running, currently secondary.
- Window 3: another Postgres instance is running, currently secondary.
- Window 4: current state of the pg_auto_failover formation is displayed and updated every 0.2 second thanks to using the watch command.
- Window 5: interactive shell for you to type commands in the docker demo environment.
To trigger a failover, simply run the following command:
$ pg_autoctl perform failover
Here is what will happen with the triggered Postgres failover, using this pg_auto_failover docker image:
- One of the two secondary nodes will then be elected as the new primary and promoted to primary.
- The other secondary (also called a standby) will reconnect to the new primary, and the old primary will re-join as a standby node.
If you want to know more about how we achieve that with pg_auto_failover, our pg_auto_failover documentation and the what’s new in pg_auto_failover 1.4 post are both useful.
What’s even more interesting in the context of this blog post is that you can see how your application behaves when a Postgres failover happens. You might have to add some connection lost handling, and you might have to change your connection string to use the multi-host capabilities of libpq.
Or maybe your application was ready to handle a Postgres failover and you are witnessing the magic of the client-side HA: congratulations then!
Demo application showing failover impact with statistics
The pg_auto_failover docker image introduced earlier in this post also contains a demo app that you can use to get more clues about what happens to your application during a Postgres failover. All the demo app does is connect to Postgres, and when connected, INSERTs into a table that tracks statistics about connection times.
Here’s what the CLI for the embedded demo app looks like. We use the pg_autoctl command that is part of the pg_auto_failover application. pg_autoctl embeds a bunch of hidden utilities and debugging programs when the environment variable PG_AUTOCTL_DEBUG is defined. Here is what our small demo application looks like:
$ pg_autoctl do demo
pg_autoctl do demo: expected a command
Available commands:
pg_autoctl do demo
run Run the pg_auto_failover demo application
uri Grab the application connection string from the monitor
ping Attempt to connect to the application URI
summary Display a summary of the previous demo app run
$ pg_autoctl do demo run --help
pg_autoctl do demo run: Run the pg_auto_failover demo application
usage: pg_autoctl do demo run [option ...]
--monitor Postgres URI of the pg_auto_failover monitor
--formation Formation to use (default)
--group Group Id to failover (0)
--username PostgreSQL’s username
--clients How many client processes to use (1)
--duration Duration of the demo app, in seconds (30)
--first-failover Timing of the first failover (10)
--failover-freq Seconds between subsequent failovers (45)
We are now going to do 3 things:
- run the demo app and prevent failovers from happening, and then
- run the demo again with one Postgres failover happening.
- After, we will be able to compare statistics from the two runs.
The first run looks like this, and you can copy/paste the command in your docker demo image, of course:
$ pg_autoctl do demo run --monitor 'postgres://autoctl_node@localhost:5500/pg_auto_failover?sslmode=require' --clients 10 --duration 30 --first-failover 60
The demo app is a little rough in the edges at this time and the fact that no failover happens is considered an error, and no summary is printed. We can still get the summary with the following command:
$ pg_autoctl do demo summary --monitor 'postgres://autoctl_node@localhost:5500/pg_auto_failover?sslmode=require' --clients 10 --duration 30 --first-failover 60
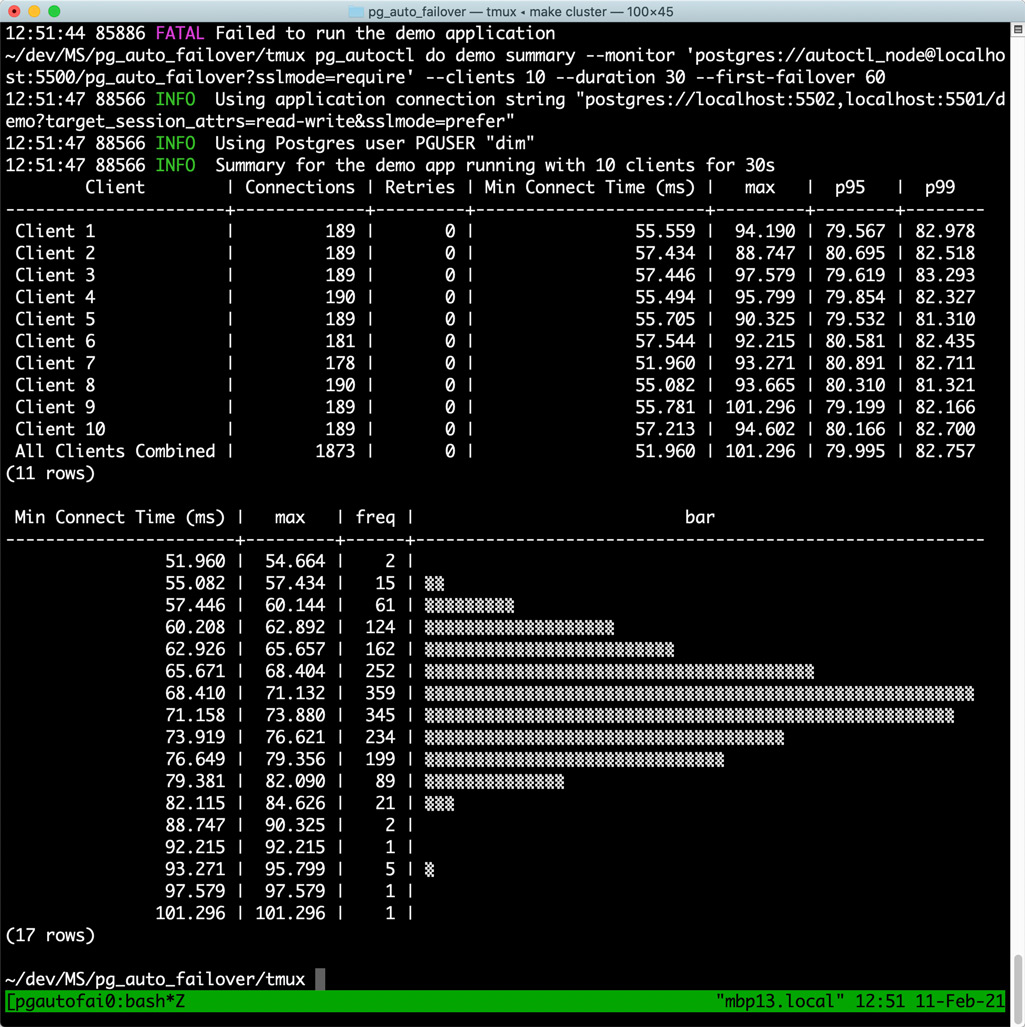
The screenshot above in Figure 2 shows that all clients combined have successfully connected 1,873 times to Postgres in that run, with a minimum connection time 51.960 ms and a maximum connection time of 101.296 ms. The 99th percentile of connection time is 82.757 ms for this round.
| Total # Postgres connections | Minimum connection time (ms) | Maximum connection time (ms) | 99th percentile of connection time (ms) |
|---|---|---|---|
| 1,873 | 51.960 | 101.296 | 82.757 |
These numbers are not to be read for their absolute values. We just want to use them later as a baseline—to compare with our connection timing statistics when a failover happens and while the demo application is trying to perform its duties. Connection times in Postgres may vary a lot depending on the network properties. Think Unix domain sockets and remote TCP/IP nodes, for instance.
Now, we can do another run with a couple of Postgres failover happenings:
$ pg_autoctl do demo run --monitor 'postgres://autoctl_node@localhost:5500/pg_auto_failover?sslmode=require' --clients 10 --duration 125
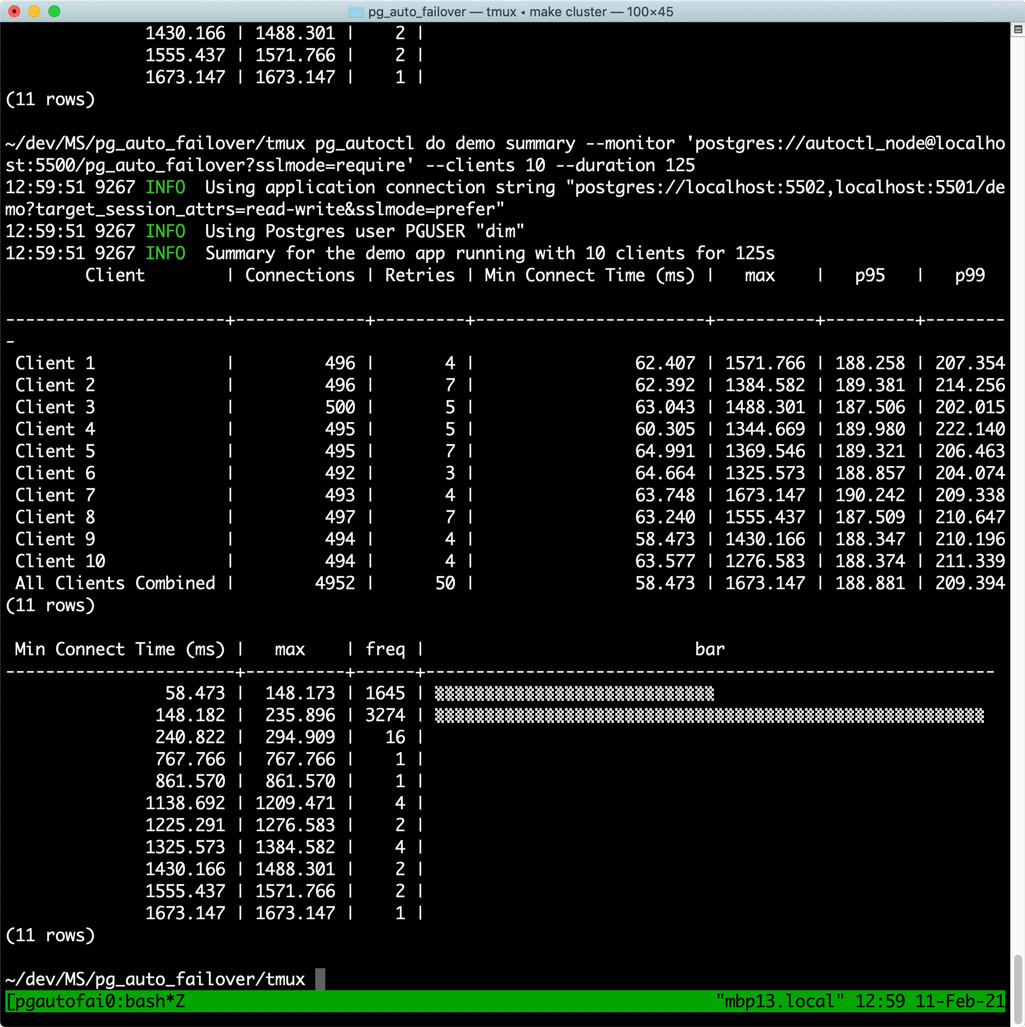
As you can see in Figure 3 above, this time our 10 clients combined connected 4,952 times total, with a minimum connection time registered at 58.473 ms and a maximum connection time of 1,673.147 ms. The 99th percentile of connection time is 209.394 ms for this round.
| Total # Postgres connections | Minimum connection time (ms) | Maximum connection time (ms) | 99th percentile of connection time (ms) |
|---|---|---|---|
| 4,952 | 58.473 | 1,673.147 | 209.394 |
During the PostgreSQL failover, we see that it took more than 1.5 second to establish a connection to Postgres, on the same host. That’s pretty long. What happens though is that the automated failover orchestrated by pg_auto_failover has taken more than 1s, and then our client demo application needed some more time to connect to the new primary.
What is also interesting above is that 99% of the 4,952 connection attempts concluded in less than 250 ms (p99 is 209.394 ms). This good result is obtained thanks to using a well-tuned retry policy named “Decorrelated Jitter”. You can read more about the decorrelated jitter approach in our pg_auto_failover source code comments.
This demo shows that it is possible for a fully automated Postgres failover in production to have less than 2s of impact on your application while it tries to re-establish a working connection to the new primary node.
Automated Failover must include client-side automated reconnections
The bottom line is that High Availability for Postgres cannot be achieved on the server-side only. Even with the best DBAs and SREs and the most robust deployment available on the planet, when a Postgres failover happens, your application code must be able to handle the ensuing “connection lost” situation.
One important aspect of handling a lost connection is of course being able to re-connect to the Postgres database, and to automatically connect to the current primary node, which might have just changed.
Thanks to pg_auto_failover you can easily see how your own application responds to a “connection lost” scenario—without having to ask your ops team to setup a production grade Postgres environment where you can drive the failovers yourself. You can even use a whole environment in a single docker container if that makes testing easier.
Automatic retry of a transaction is dangerous at best
One topic we have not explored in this post so far: What if your application was in the middle of some important processing at the time of the failover? Since Postgres implements transactions, if the connection is lost when in the middle of a transaction, then the transaction is safely cancelled in the same way as if a ROLLBACK command had been issued.
It is then up to your application to figure out if the transaction (or the whole session) should be replayed or not. When the transaction (or the session) should be replayed, can you replay it with the information that your application has in-memory, or do you need to fetch new values from the new Postgres database node? This decision is very specific to each part of your application, there is no generic way to approach this situation. Which is why I say above that an automatic retry of a transaction is dangerous at best.
The simpler way to handle this situation is to show an error to your user and ask them to redo whatever they were doing. However, when showing an error to your user results in a lost basket, asking the user to redo an action might not be an option for you and your application.
Let’s face it: error handling and fault tolerance is hard. That’s why it’s good to have the whole team work together and find the best way to handle those rare situations.
What now?
Now that you have the client-side HA concepts in mind, you might want to get to practicing failover with your own application. For that, you can use pg_auto_failover either in a testing environment or for your production needs. Our pg_auto_failover documentation is available online and should cover all you need to know.
