📺 All 44 POSETTE: An Event for Postgres 2026 talks are now available on YouTube.
With the release of Citus 5.0 in 2016, all pg_shard functionality is included directly in Citus. We encourage you to take a look at Citus, instead of pg_shard which is now deprecated. Citus is available as open source and in the cloud, as the Azure Cosmos DB for PostgreSQL managed service. If you’re looking to run Citus in the cloud, take a look at Azure Cosmos DB for PostgreSQL.
The open source pg_shard extension for PostgreSQL can shard a table across a cluster of nodes, storing shards in regular tables. All communication between the pg_shard master and worker nodes happens using regular SQL commands, which allows almost any PostgreSQL server to act as a worker node, including Amazon RDS instances.
Apart from simplifying database administration, using Amazon RDS or a similar solution with pg_shard has another benefit. RDS instances have automatic failover using streaming replication, which means that it is not necessary to use pg_shard’s built-in replication for high availability. Without replication, pg_shard can be used in a multi-master / masterless set-up.
At this week’s PGDay UK, we demonstrated a distributed PostgreSQL cluster consisting of 4 worker nodes on RDS and 2 master nodes on EC2 with pg_shard installed (as shown below). We showed how the cluster automatically recovers when you terminate workers or master nodes while running queries. To make it even more interesting, we put the master nodes in an auto-scaling group and put a load-balancer in front of them. This architecture is somewhat experimental, but it can support a very high number of transactions per second and very large data sizes.
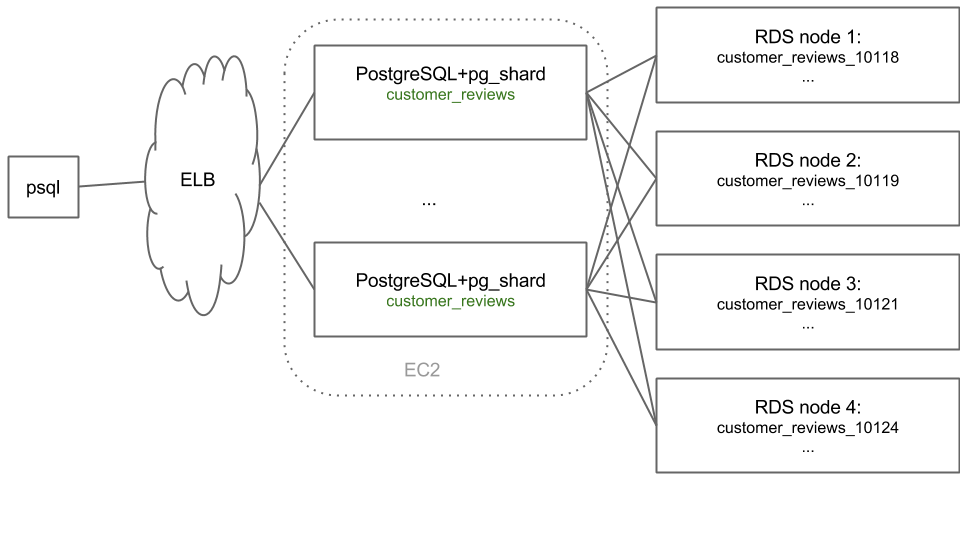 Now what good is a demo if you can’t play with it yourself? To start your very own state-of-the-art distributed PostgreSQL cluster with 4 worker nodes on Amazon RDS: Launch it using CloudFormation! Make sure to enter a (long) database password and your EC2 keypair in the Parameters screen. You can leave the other settings on their defaults.
Now what good is a demo if you can’t play with it yourself? To start your very own state-of-the-art distributed PostgreSQL cluster with 4 worker nodes on Amazon RDS: Launch it using CloudFormation! Make sure to enter a (long) database password and your EC2 keypair in the Parameters screen. You can leave the other settings on their defaults.
Once stack creation completes (~25 minutes), you can find the hostname of the load-balancer in the Outputs tab in the CloudFormation console (may require refresh), the hostnames of the master nodes can be found in the EC2 console, and the worker nodes in the RDS console.
We recommend you start by connecting to one of the master nodes over SSH. On the master node, run psql and enter the following commands:
CREATE TABLE customer_reviews
(
customer_id TEXT NOT NULL,
review_date DATE,
review_rating INTEGER,
review_votes INTEGER,
review_helpful_votes INTEGER,
product_id CHAR(10),
product_title TEXT,
product_sales_rank BIGINT,
product_group TEXT,
product_category TEXT,
product_subcategory TEXT,
similar_product_ids CHAR(10)[]
);
SELECT master_create_distributed_table('customer_reviews', 'customer_id');
SELECT master_create_worker_shards('customer_reviews', 128, 1);
\q
Every master node has a script to sync metadata to the other master nodes. In the shell, run:
sync-metadata customer_reviews
Now you should be able to run queries on the customer_reviews table via the load-balancer by running the command below. See the pg_shard github page for some example queries to use.
psql -h $(cat /etc/load-balancer)
To ingest some interesting data, use the following commands to INSERT rows using 256 parallel streams:
wget http://examples.citusdata.com/customer_reviews_{1998..2004}.csv.gz
gzip -d customer_reviews_*.csv.gz
parallel-copy-in -P 256 -C -h $(cat /etc/load-balancer) customer_reviews_1998.csv customer_reviews
In our initial benchmarks using the CloudFormation template we saw well over 100k INSERTS/second across 4 RDS instances (db.r3.4xlarge).
Sharded tables can also be queried in parallel for real-time analytics using Citus, which pushes down computation to the worker nodes and supports JOINs. This uniquely positions PostgreSQL as a platform that can support real-time data ingestion, fast sharded queries, and real-time analytics at a massive scale. An example of running queries using CitusDB is shown below:
\timing
SET pg_shard.use_citusdb_select_logic TO on;
SELECT review_date, count(*) FROM customer_reviews WHERE review_date BETWEEN '1998-01-01' AND '1998-01-31' GROUP BY review_date ORDER BY review_date ASC;
Note that the pg_shard extension is meant for queries that resemble those in NoSQL workloads, and CitusDB is meant for analytical queries. Some more complex use-cases may not be directly supported, but many have workarounds. If you'd like to learn more about pg_shard, CitusDB, or the details of our CloudFormation templates for Amazon RDS, don't hesitate to contact us.
