POSETTE 2025 is a wrap! 🎁 Thanks for joining the fun. Missed it? Watch all 42 talks online.

Enable Users to Analyze Real-Time Events as They Happen
The Citus extension to PostgreSQL is good at scaling out event data pipelines. For many of our real-time analytics customers, it’s critical that events be analyzed as they happen. Because Citus parallelizes SQL over multiple nodes, Citus can provide real-time responsiveness, even with terabytes of data. Moreover, Citus can pre-aggregate the data in parallel across all servers using standard SQL commands to enable millisecond query times even with billions of events per day.
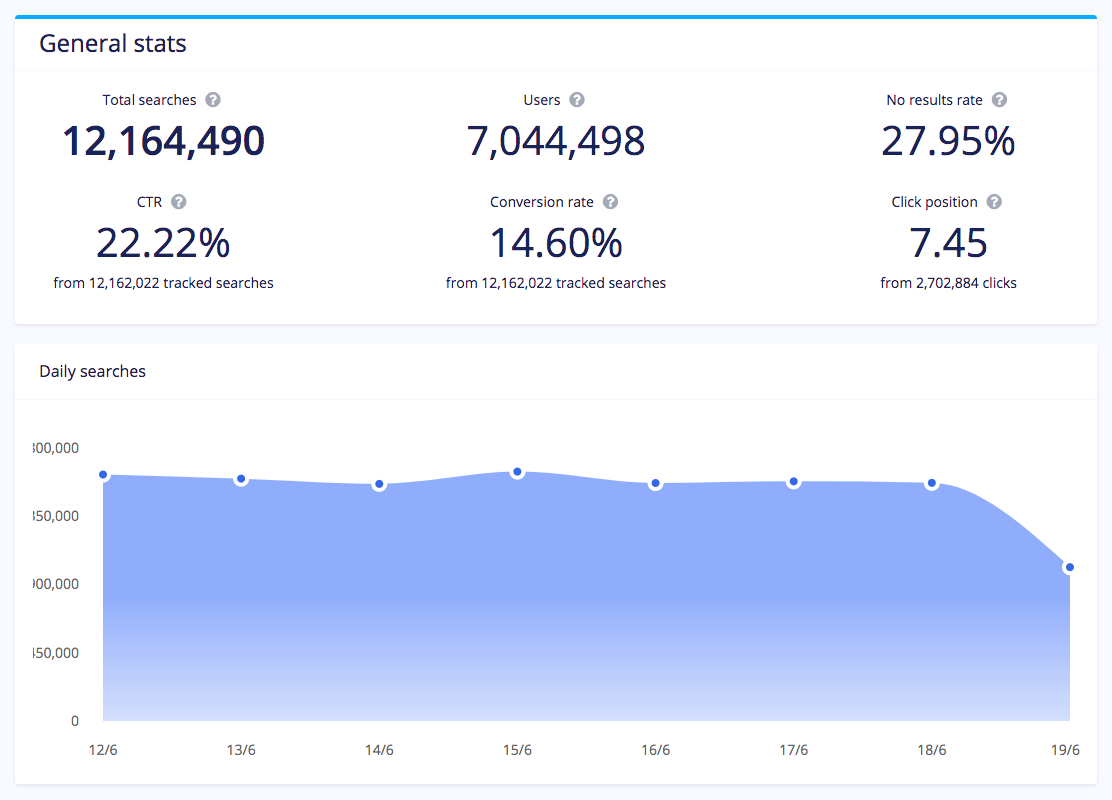
Deliver Sub-Second Responses to Your Customer Facing Dashboards
Traditional data warehouses are good at supporting teams of in-house data analysts, but not as good at supporting thousands of customers all querying their dashboards at the same time. Because of the intelligent way Citus distributes SQL over multiple nodes, you get massive parallelism AND concurrency, with Citus coordinating hundreds or even thousands of cores for high performance data ingest and fast analytical queries. With support for advanced subqueries and complex joins on co-located tables and reference tables, you can even do advanced queries such as search and funnel analysis. So your users get the insights they need with your interactive dashboards. Citus works well for both real time dashboards and historical dashboards over long time windows.
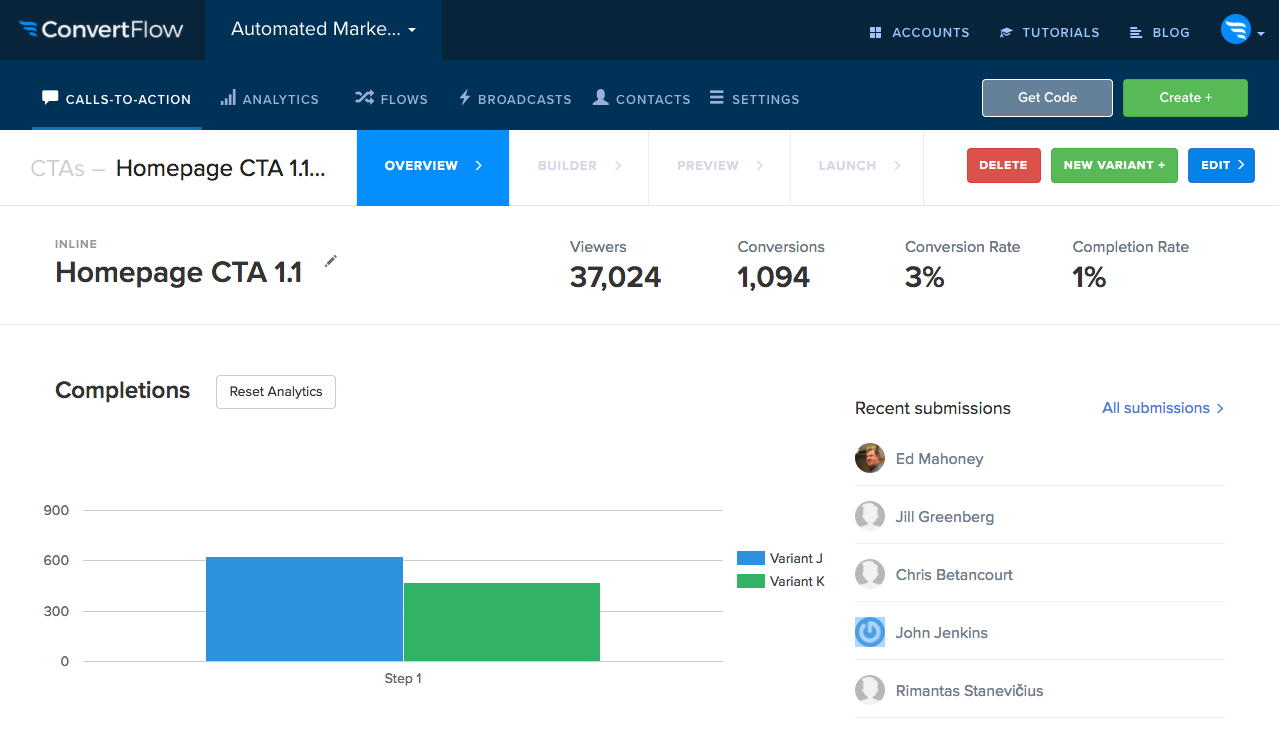
Get Insanely Fast Analytics Without Re-Architecting Your App
One of our customers describes Citus as insanely fast for real-time analytics (yay.) There are other benefits as well. The fact that Citus is built on Postgres means that applications which are compatible with Postgres will have a faster path to deploying on Citus (the same is true for teams with deep Postgres expertise already)—adopting Citus does not require large-scale application changes. And because Citus is an extension to Postgres (not a fork like so many others), you’ll always be on the most up-to-date version of PostgreSQL. Plus you get all the other Postgres data types and extensions, like JSONB, PostGIS, full text search, HyperLogLog. The list goes on.

Simplify Your Stack by Scaling Out Postgres
Some data pipeline solutions are really, really good at one thing. This has caused practitioners to have to stitch together multiple different database technologies to get the job done. One of the things our customers love about Citus is that Citus is multipurpose: you can combine powerful SQL queries with fast inserts and updates, and you can combine analytics workloads with transactional systems of record—reducing the complexity and cost of your operations. All the while keeping the powerful and familiar PostgreSQL expressiveness and features in your toolchest.


